 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspMamba: A Mamba-based Language-driven Grasp Detection Framework with Hierarchical Feature Learning
Sep 22, 2024Grasp detection is a fundamental robotic task critical to the success of many industrial applications. However, current language-driven models for this task often struggle with cluttered images, lengthy textual descriptions, or slow inference speed. We introduce GraspMamba, a new language-driven grasp detection method that employs hierarchical feature fusion with Mamba vision to tackle these challenges. By leveraging rich visual features of the Mamba-based backbone alongside textual information, our approach effectively enhances the fusion of multimodal features. GraspMamba represents the first Mamba-based grasp detection model to extract vision and language features at multiple scales, delivering robust performance and rapid inference time. Intensive experiments show that GraspMamba outperforms recent methods by a clear margin. We validate our approach through real-world robotic experiments, highlighting its fast inference speed.
LoG-VMamba: Local-Global Vision Mamba for Medical Image Segmentation
Aug 26, 2024



Mamba, a State Space Model (SSM), has recently shown competitive performance to Convolutional Neural Networks (CNNs) and Transformers in Natural Language Processing and general sequence modeling. Various attempts have been made to adapt Mamba to Computer Vision tasks, including medical image segmentation (MIS). Vision Mamba (VM)-based networks are particularly attractive due to their ability to achieve global receptive fields, similar to Vision Transformers, while also maintaining linear complexity in the number of tokens. However, the existing VM models still struggle to maintain both spatially local and global dependencies of tokens in high dimensional arrays due to their sequential nature. Employing multiple and/or complicated scanning strategies is computationally costly, which hinders applications of SSMs to high-dimensional 2D and 3D images that are common in MIS problems. In this work, we propose Local-Global Vision Mamba, LoG-VMamba, that explicitly enforces spatially adjacent tokens to remain nearby on the channel axis, and retains the global context in a compressed form. Our method allows the SSMs to access the local and global contexts even before reaching the last token while requiring only a simple scanning strategy. Our segmentation models are computationally efficient and substantially outperform both CNN and Transformers-based baselines on a diverse set of 2D and 3D MIS tasks. The implementation of LoG-VMamba is available at \url{https://github.com/Oulu-IMEDS/LoG-VMamba}.
Variational Autoencoder for Anomaly Detection: A Comparative Study
Aug 24, 2024This paper aims to conduct a comparative analysis of contemporary Variational Autoencoder (VAE) architectures employed in anomaly detection, elucidating their performance and behavioral characteristics within this specific task. The architectural configurations under consideration encompass the original VAE baseline, the VAE with a Gaussian Random Field prior (VAE-GRF), and the VAE incorporating a vision transformer (ViT-VAE). The findings reveal that ViT-VAE exhibits exemplary performance across various scenarios, whereas VAE-GRF may necessitate more intricate hyperparameter tuning to attain its optimal performance state. Additionally, to mitigate the propensity for over-reliance on results derived from the widely used MVTec dataset, this paper leverages the recently-public MiAD dataset for benchmarking. This deliberate inclusion seeks to enhance result competitiveness by alleviating the impact of domain-specific models tailored exclusively for MVTec, thereby contributing to a more robust evaluation framework. Codes is available at https://github.com/endtheme123/VAE-compare.git.
Active Sensing of Knee Osteoarthritis Progression with Reinforcement Learning
Aug 05, 2024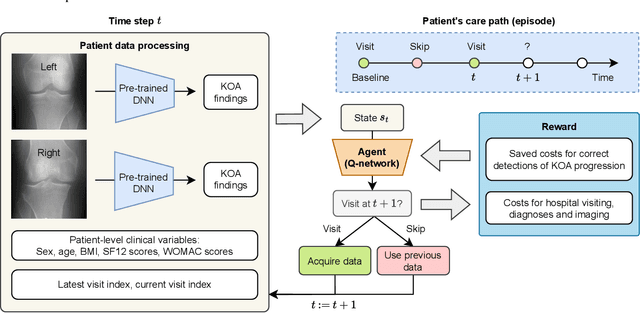
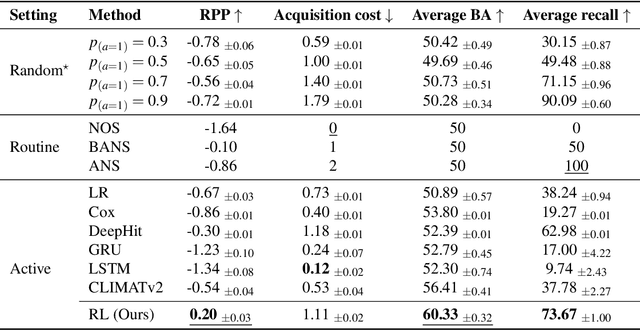
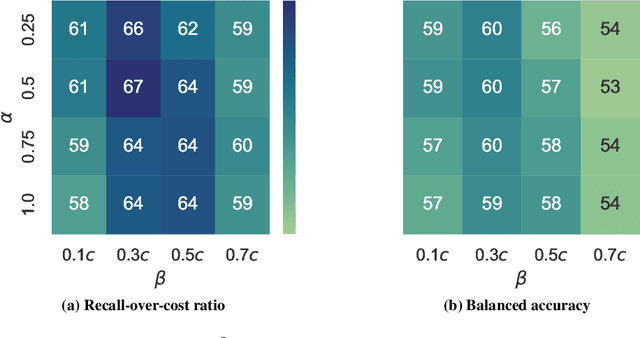
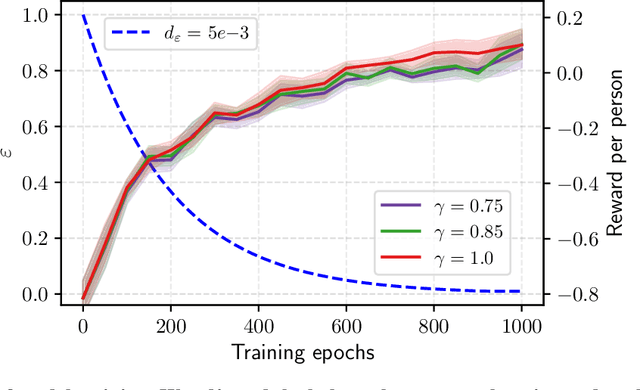
Osteoarthritis (OA) is the most common musculoskeletal disease, which has no cure. Knee OA (KOA) is one of the highest causes of disability worldwide, and it costs billions of United States dollars to the global community. Prediction of KOA progression has been of high interest to the community for years, as it can advance treatment development through more efficient clinical trials and improve patient outcomes through more efficient healthcare utilization. Existing approaches for predicting KOA, however, are predominantly static, i.e. consider data from a single time point to predict progression many years into the future, and knee level, i.e. consider progression in a single joint only. Due to these and related reasons, these methods fail to deliver the level of predictive performance, which is sufficient to result in cost savings and better patient outcomes. Collecting extensive data from all patients on a regular basis could address the issue, but it is limited by the high cost at a population level. In this work, we propose to go beyond static prediction models in OA, and bring a novel Active Sensing (AS) approach, designed to dynamically follow up patients with the objective of maximizing the number of informative data acquisitions, while minimizing their total cost over a period of time. Our approach is based on Reinforcement Learning (RL), and it leverages a novel reward function designed specifically for AS of disease progression in more than one part of a human body. Our method is end-to-end, relies on multi-modal Deep Learning, and requires no human input at inference time. Throughout an exhaustive experimental evaluation, we show that using RL can provide a higher monetary benefit when compared to state-of-the-art baselines.
Language-Driven Closed-Loop Grasping with Model-Predictive Trajectory Replanning
Jun 14, 2024



Combining a vision module inside a closed-loop control system for a \emph{seamless movement} of a robot in a manipulation task is challenging due to the inconsistent update rates between utilized modules. This task is even more difficult in a dynamic environment, e.g., objects are moving. This paper presents a \emph{modular} zero-shot framework for language-driven manipulation of (dynamic) objects through a closed-loop control system with real-time trajectory replanning and an online 6D object pose localization. We segment an object within $\SI{0.5}{\second}$ by leveraging a vision language model via language commands. Then, guided by natural language commands, a closed-loop system, including a unified pose estimation and tracking and online trajectory planning, is utilized to continuously track this object and compute the optimal trajectory in real-time. Our proposed zero-shot framework provides a smooth trajectory that avoids jerky movements and ensures the robot can grasp a non-stationary object. Experiment results exhibit the real-time capability of the proposed zero-shot modular framework for the trajectory optimization module to accurately and efficiently grasp moving objects, i.e., up to \SI{30}{\hertz} update rates for the online 6D pose localization module and \SI{10}{\hertz} update rates for the receding-horizon trajectory optimization. These advantages highlight the modular framework's potential applications in robotics and human-robot interaction; see the video in https://www.acin.tuwien.ac.at/en/6e64/.
Image-level Regression for Uncertainty-aware Retinal Image Segmentation
May 27, 2024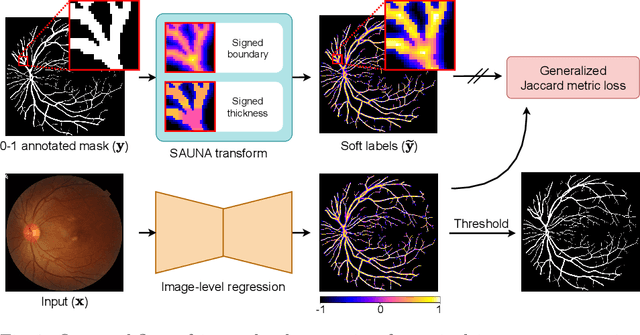
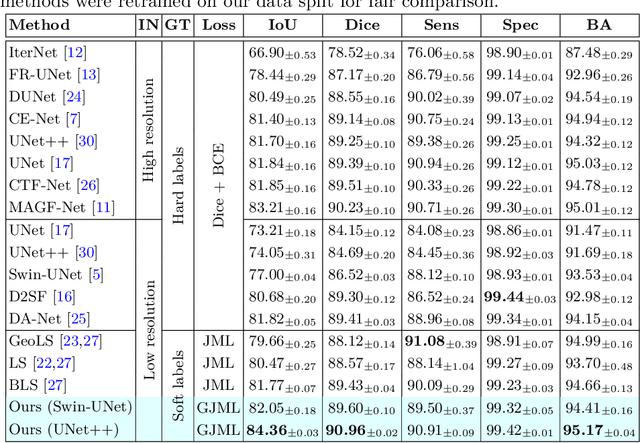
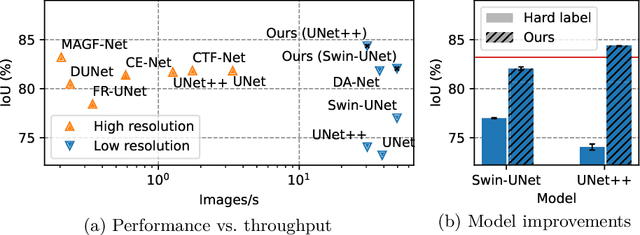
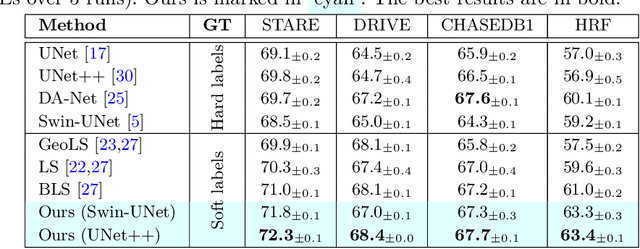
Accurate retinal vessel segmentation is a crucial step in the quantitative assessment of retinal vasculature, which is needed for the early detection of retinal diseases and other conditions. Numerous studies have been conducted to tackle the problem of segmenting vessels automatically using a pixel-wise classification approach. The common practice of creating ground truth labels is to categorize pixels as foreground and background. This approach is, however, biased, and it ignores the uncertainty of a human annotator when it comes to annotating e.g. thin vessels. In this work, we propose a simple and effective method that casts the retinal image segmentation task as an image-level regression. For this purpose, we first introduce a novel Segmentation Annotation Uncertainty-Aware (SAUNA) transform, which adds pixel uncertainty to the ground truth using the pixel's closeness to the annotation boundary and vessel thickness. To train our model with soft labels, we generalize the earlier proposed Jaccard metric loss to arbitrary hypercubes, which is a second contribution of this work. The proposed SAUNA transform and the new theoretical results allow us to directly train a standard U-Net-like architecture at the image level, outperforming all recently published methods. We conduct thorough experiments and compare our method to a diverse set of baselines across 5 retinal image datasets. Our implementation is available at \url{https://github.com/Oulu-IMEDS/SAUNA}.
SiNGR: Brain Tumor Segmentation via Signed Normalized Geodesic Transform Regression
May 27, 2024



One of the primary challenges in brain tumor segmentation arises from the uncertainty of voxels close to tumor boundaries. However, the conventional process of generating ground truth segmentation masks fails to treat such uncertainties properly. Those ``hard labels'' with 0s and 1s conceptually influenced the majority of prior studies on brain image segmentation. As a result, tumor segmentation is often solved through voxel classification. In this work, we instead view this problem as a voxel-level regression, where the ground truth represents a certainty mapping from any pixel based on the distance to tumor border. We propose a novel ground truth label transformation, which is based on a signed geodesic transform, to capture the uncertainty in brain tumors' vicinity, while maintaining a margin between positive and negative samples. We combine this idea with a Focal-like regression L1-loss that enables effective regression learning in high-dimensional output space by appropriately weighting voxels according to their difficulty. We thoroughly conduct an experimental evaluation to validate the components of our proposed method, compare it to a diverse array of state-of-the-art segmentation models, and show that it is architecture-agnostic. The code of our method is made publicly available (\url{https://github.com/Oulu-IMEDS/SiNGR/}).
Universal Graph Continual Learning
Aug 27, 2023
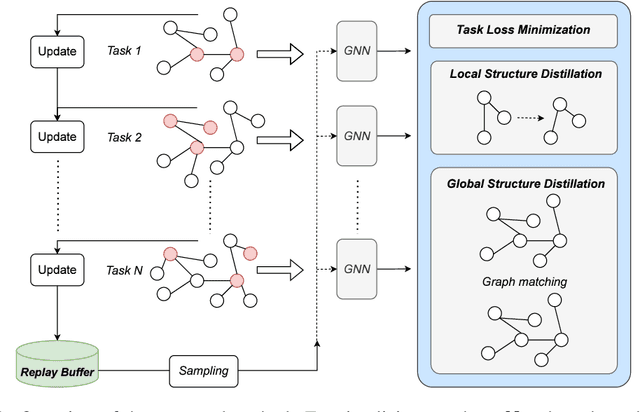
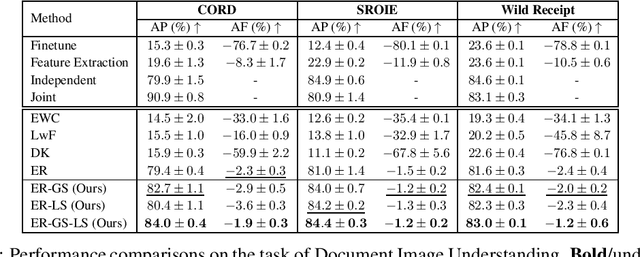
We address catastrophic forgetting issues in graph learning as incoming data transits from one to another graph distribution. Whereas prior studies primarily tackle one setting of graph continual learning such as incremental node classification, we focus on a universal approach wherein each data point in a task can be a node or a graph, and the task varies from node to graph classification. We propose a novel method that enables graph neural networks to excel in this universal setting. Our approach perseveres knowledge about past tasks through a rehearsal mechanism that maintains local and global structure consistency across the graphs. We benchmark our method against various continual learning baselines in real-world graph datasets and achieve significant improvement in average performance and forgetting across tasks.
A Stronger Baseline For Automatic Pfirrmann Grading Of Lumbar Spine MRI Using Deep Learning
Oct 26, 2022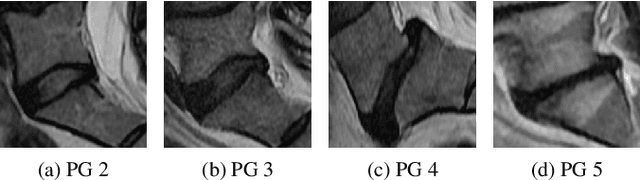
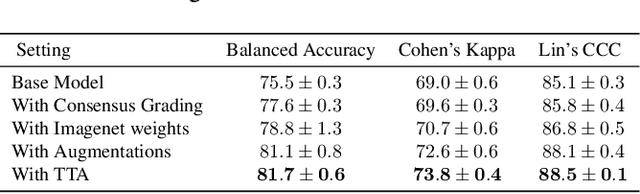
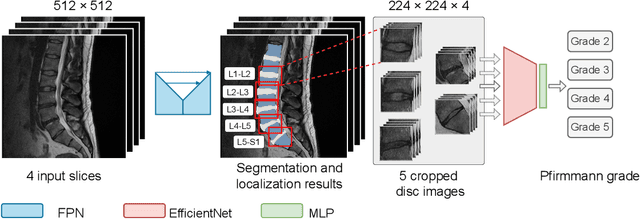
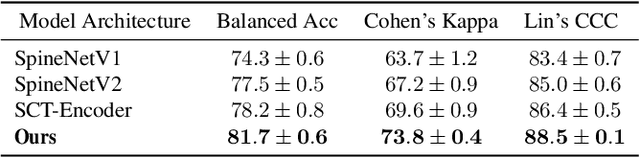
This paper addresses the challenge of grading visual features in lumbar spine MRI using Deep Learning. Such a method is essential for the automatic quantification of structural changes in the spine, which is valuable for understanding low back pain. Multiple recent studies investigated different architecture designs, and the most recent success has been attributed to the use of transformer architectures. In this work, we argue that with a well-tuned three-stage pipeline comprising semantic segmentation, localization, and classification, convolutional networks outperform the state-of-the-art approaches. We conducted an ablation study of the existing methods in a population cohort, and report performance generalization across various subgroups. Our code is publicly available to advance research on disc degeneration and low back pain.
Clinically-Inspired Multi-Agent Transformers for Disease Trajectory Forecasting from Multimodal Data
Oct 25, 2022Deep neural networks are often applied to medical images to automate the problem of medical diagnosis. However, a more clinically relevant question that practitioners usually face is how to predict the future trajectory of a disease. Current methods for prognosis or disease trajectory forecasting often require domain knowledge and are complicated to apply. In this paper, we formulate the prognosis prediction problem as a one-to-many prediction problem. Inspired by a clinical decision-making process with two agents -- a radiologist and a general practitioner -- we predict prognosis with two transformer-based components that share information with each other. The first transformer in this framework aims to analyze the imaging data, and the second one leverages its internal states as inputs, also fusing them with auxiliary clinical data. The temporal nature of the problem is modeled within the transformer states, allowing us to treat the forecasting problem as a multi-task classification, for which we propose a novel loss. We show the effectiveness of our approach in predicting the development of structural knee osteoarthritis changes and forecasting Alzheimer's disease clinical status directly from raw multi-modal data. The proposed method outperforms multiple state-of-the-art baselines with respect to performance and calibration, both of which are needed for real-world applications. An open-source implementation of our method is made publicly available at \url{https://github.com/Oulu-IMEDS/CLIMATv2}.