 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundPlanner: A convex-set-based approach to bounded manipulator trajectory planning
Feb 18, 2025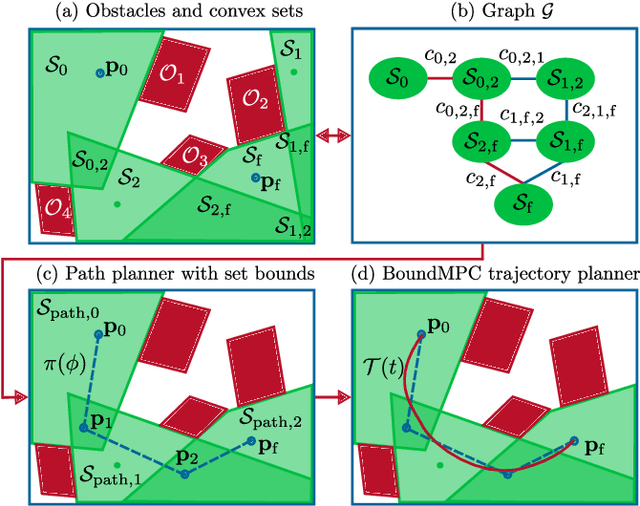
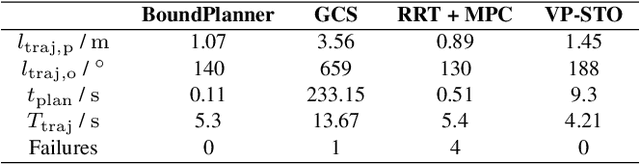
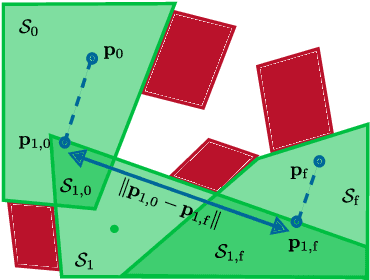

Online trajectory planning enables robot manipulators to react quickly to changing environments or tasks. Many robot trajectory planners exist for known environments but are often too slow for online computations. Current methods in online trajectory planning do not find suitable trajectories in challenging scenarios that respect the limits of the robot and account for collisions. This work proposes a trajectory planning framework consisting of the novel Cartesian path planner based on convex sets, called BoundPlanner, and the online trajectory planner BoundMPC. BoundPlanner explores and maps the collision-free space using convex sets to compute a reference path with bounds. BoundMPC is extended in this work to handle convex sets for path deviations, which allows the robot to optimally follow the path within the bounds while accounting for the robot's kinematics. Collisions of the robot's kinematic chain are considered by a novel convex-set-based collision avoidance formulation independent on the number of obstacles. Simulations and experiments with a 7-DoF manipulator show the performance of the proposed planner compared to state-of-the-art methods. The source code is available at github.com/Thieso/BoundPlanner and videos of the experiments can be found at www.acin.tuwien.ac.at/42d4
Language-Driven Closed-Loop Grasping with Model-Predictive Trajectory Replanning
Jun 14, 2024



Combining a vision module inside a closed-loop control system for a \emph{seamless movement} of a robot in a manipulation task is challenging due to the inconsistent update rates between utilized modules. This task is even more difficult in a dynamic environment, e.g., objects are moving. This paper presents a \emph{modular} zero-shot framework for language-driven manipulation of (dynamic) objects through a closed-loop control system with real-time trajectory replanning and an online 6D object pose localization. We segment an object within $\SI{0.5}{\second}$ by leveraging a vision language model via language commands. Then, guided by natural language commands, a closed-loop system, including a unified pose estimation and tracking and online trajectory planning, is utilized to continuously track this object and compute the optimal trajectory in real-time. Our proposed zero-shot framework provides a smooth trajectory that avoids jerky movements and ensures the robot can grasp a non-stationary object. Experiment results exhibit the real-time capability of the proposed zero-shot modular framework for the trajectory optimization module to accurately and efficiently grasp moving objects, i.e., up to \SI{30}{\hertz} update rates for the online 6D pose localization module and \SI{10}{\hertz} update rates for the receding-horizon trajectory optimization. These advantages highlight the modular framework's potential applications in robotics and human-robot interaction; see the video in https://www.acin.tuwien.ac.at/en/6e64/.
Model Predictive Trajectory Optimization With Dynamically Changing Waypoints for Serial Manipulators
Feb 07, 2024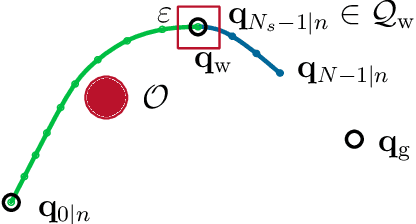
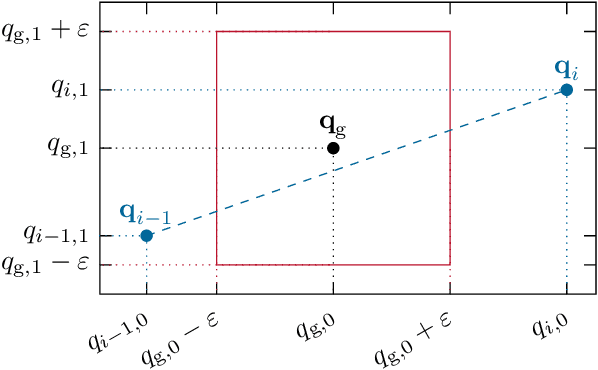
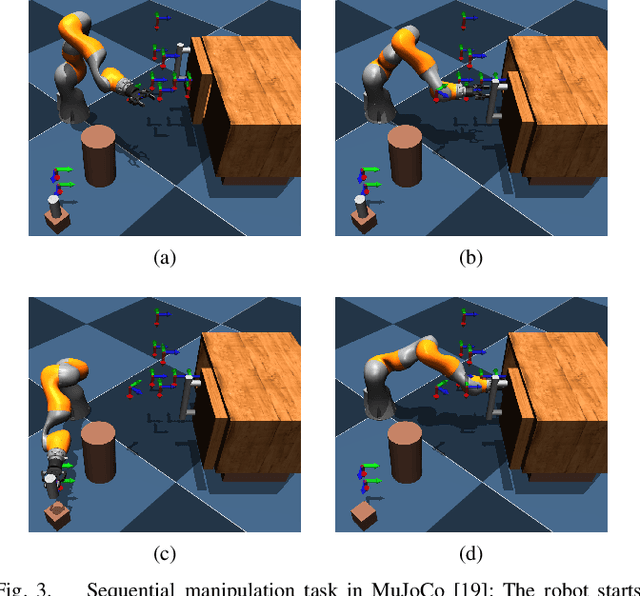
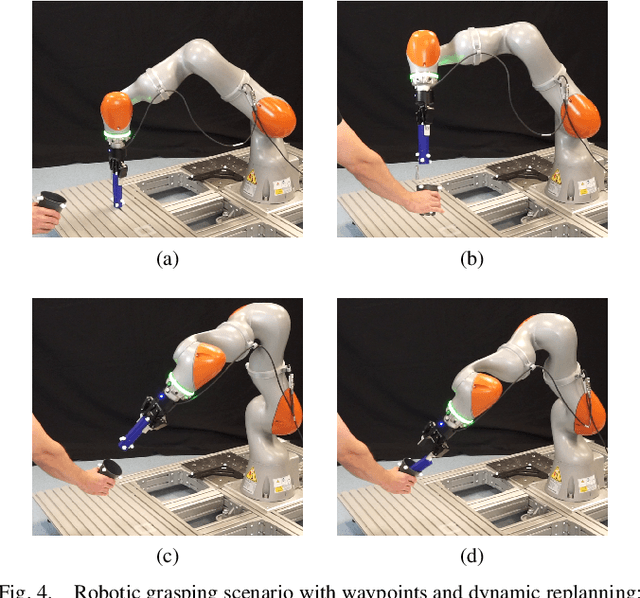
Systematically including dynamically changing waypoints as desired discrete actions, for instance, resulting from superordinate task planning, has been challenging for online model predictive trajectory optimization with short planning horizons. This paper presents a novel waypoint model predictive control (wMPC) concept for online replanning tasks. The main idea is to split the planning horizon at the waypoint when it becomes reachable within the current planning horizon and reduce the horizon length towards the waypoints and goal points. This approach keeps the computational load low and provides flexibility in adapting to changing conditions in real time. The presented approach achieves competitive path lengths and trajectory durations compared to (global) offline RRT-type planners in a multi-waypoint scenario. Moreover, the ability of wMPC to dynamically replan tasks online is experimentally demonstrated on a KUKA LBR iiwa 14 R820 robot in a dynamic pick-and-place scenario.
BoundMPC: Cartesian Trajectory Planning with Error Bounds based on Model Predictive Control in the Joint Space
Jan 10, 2024This work presents a novel online model-predictive trajectory planner for robotic manipulators called BoundMPC. This planner allows the collision-free following of Cartesian reference paths in the end-effector's position and orientation, including via-points, within desired asymmetric bounds of the orthogonal path error. The path parameter synchronizes the position and orientation reference paths. The decomposition of the path error into the tangential direction, describing the path progress, and the orthogonal direction, which represents the deviation from the path, is well known for the position from the path-following control in the literature. This paper extends this idea to the orientation by utilizing the Lie theory of rotations. Moreover, the orthogonal error plane is further decomposed into basis directions to define asymmetric Cartesian error bounds easily. Using piecewise linear position and orientation reference paths with via-points is computationally very efficient and allows replanning the pose trajectories during the robot's motion. This feature makes it possible to use this planner for dynamically changing environments and varying goals. The flexibility and performance of BoundMPC are experimentally demonstrated by two scenarios on a 7-DoF Kuka LBR iiwa 14 R820 robot. The first scenario shows the transfer of a larger object from a start to a goal pose through a confined space where the object must be tilted. The second scenario deals with grasping an object from a table where the grasping point changes during the robot's motion, and collisions with other obstacles in the scene must be avoided.
Efficient learning of large sets of locally optimal classification rules
Jan 26, 2023Conventional rule learning algorithms aim at finding a set of simple rules, where each rule covers as many examples as possible. In this paper, we argue that the rules found in this way may not be the optimal explanations for each of the examples they cover. Instead, we propose an efficient algorithm that aims at finding the best rule covering each training example in a greedy optimization consisting of one specialization and one generalization loop. These locally optimal rules are collected and then filtered for a final rule set, which is much larger than the sets learned by conventional rule learning algorithms. A new example is classified by selecting the best among the rules that cover this example. In our experiments on small to very large datasets, the approach's average classification accuracy is higher than that of state-of-the-art rule learning algorithms. Moreover, the algorithm is highly efficient and can inherently be processed in parallel without affecting the learned rule set and so the classification accuracy. We thus believe that it closes an important gap for large-scale classification rule induction.
* article, 40 pages, Machine Learning journal (2023)
Two-Step Online Trajectory Planning of a Quadcopter in Indoor Environments with Obstacles
Nov 14, 2022



This paper presents a two-step algorithm for online trajectory planning in indoor environments with unknown obstacles. In the first step, sampling-based path planning techniques such as the optimal Rapidly exploring Random Tree (RRT*) algorithm and the Line-of-Sight (LOS) algorithm are employed to generate a collision-free path consisting of multiple waypoints. Then, in the second step, constrained quadratic programming is utilized to compute a smooth trajectory that passes through all computed waypoints. The main contribution of this work is the development of a flexible trajectory planning framework that can detect changes in the environment, such as new obstacles, and compute alternative trajectories in real time. The proposed algorithm actively considers all changes in the environment and performs the replanning process only on waypoints that are occupied by new obstacles. This helps to reduce the computation time and realize the proposed approach in real time. The feasibility of the proposed algorithm is evaluated using the Intel Aero Ready-to-Fly (RTF) quadcopter in simulation and in a real-world experiment.
Singlularity Avoidance with Application to Online Trajectory Optimization for Serial Manipulators
Nov 10, 2022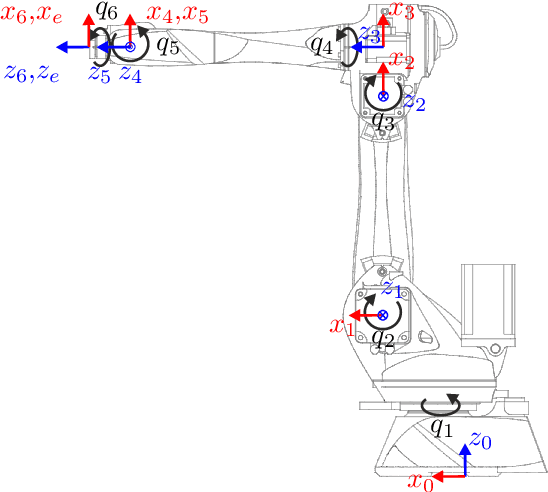
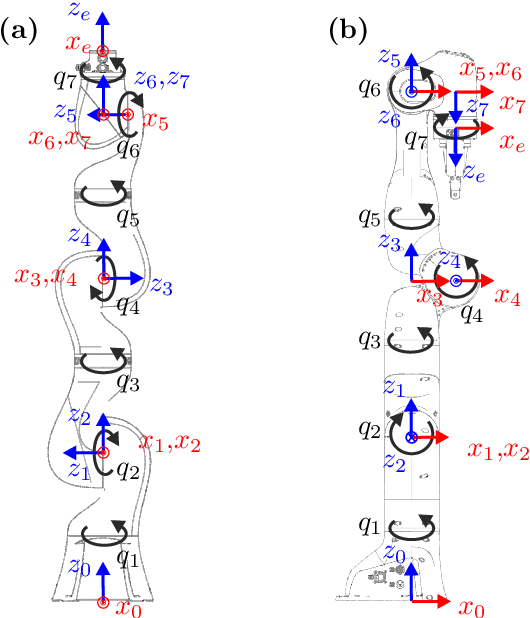

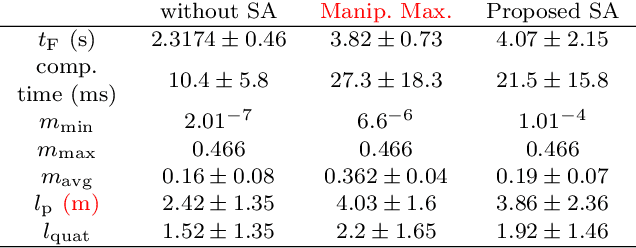
This work proposes a novel singularity avoidance approach for real-time trajectory optimization based on known singular configurations. The focus of this work lies on analyzing kinematically singular configurations for three robots with different kinematic structures, i.e., the Comau Racer 7-1.4, the KUKA LBR iiwa R820, and the Franka Emika Panda, and exploiting these configurations in form of tailored potential functions for singularity avoidance. Monte Carlo simulations of the proposed method and the commonly used manipulability maximization approach are performed for comparison. The numerical results show that the average computing time can be reduced and shorter trajectories in both time and path length are obtained with the proposed approach
Machine Learning-based Framework for Optimally Solving the Analytical Inverse Kinematics for Redundant Manipulators
Nov 08, 2022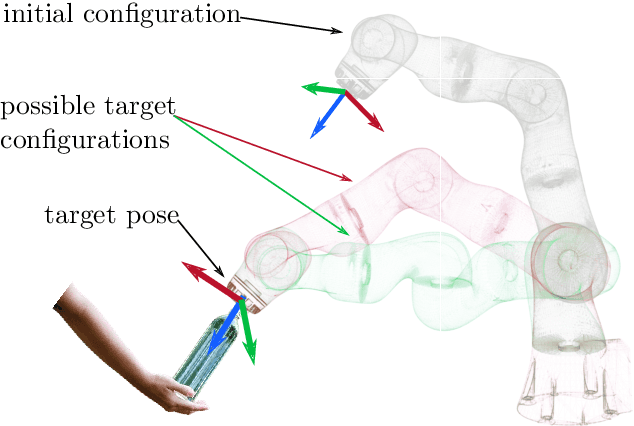

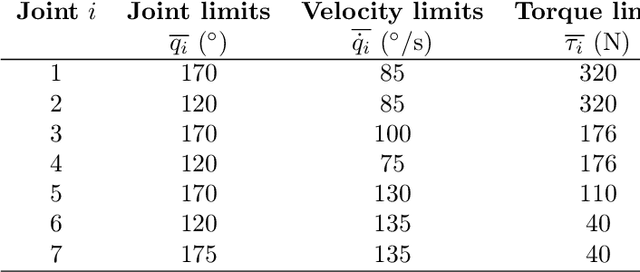
Solving the analytical inverse kinematics (IK) of redundant manipulators in real time is a difficult problem in robotics since its solution for a given target pose is not unique. Moreover, choosing the optimal IK solution with respect to application-specific demands helps to improve the robustness and to increase the success rate when driving the manipulator from its current configuration towards a desired pose. This is necessary, especially in high-dynamic tasks like catching objects in mid-flights. To compute a suitable target configuration in the joint space for a given target pose in the trajectory planning context, various factors such as travel time or manipulability must be considered. However, these factors increase the complexity of the overall problem which impedes real-time implementation. In this paper, a real-time framework to compute the analytical inverse kinematics of a redundant robot is presented. To this end, the analytical IK of the redundant manipulator is parameterized by so-called redundancy parameters, which are combined with a target pose to yield a unique IK solution. Most existing works in the literature either try to approximate the direct mapping from the desired pose of the manipulator to the solution of the IK or cluster the entire workspace to find IK solutions. In contrast, the proposed framework directly learns these redundancy parameters by using a neural network (NN) that provides the optimal IK solution with respect to the manipulability and the closeness to the current robot configuration. Monte Carlo simulations show the effectiveness of the proposed approach which is accurate and real-time capable ($\approx$ \SI{32}{\micro\second}) on the KUKA LBR iiwa 14 R820.
An Empirical Investigation into Deep and Shallow Rule Learning
Jun 18, 2021
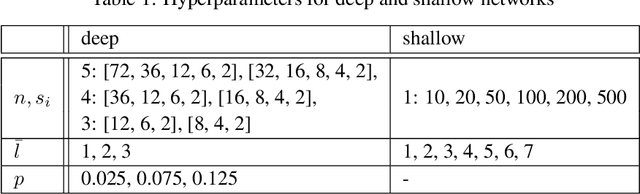
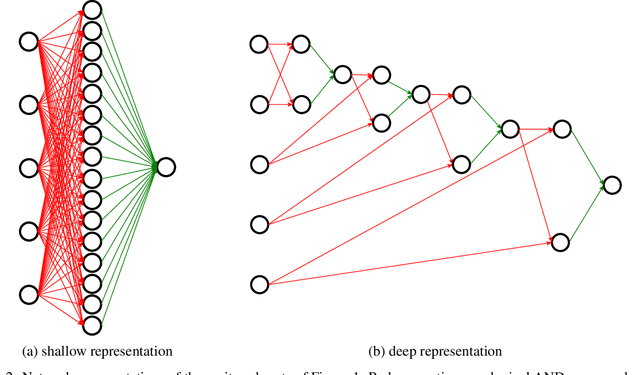
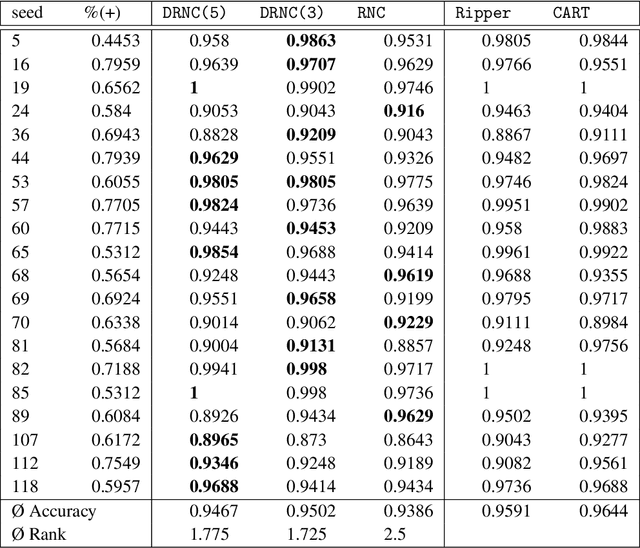
Inductive rule learning is arguably among the most traditional paradigms in machine learning. Although we have seen considerable progress over the years in learning rule-based theories, all state-of-the-art learners still learn descriptions that directly relate the input features to the target concept. In the simplest case, concept learning, this is a disjunctive normal form (DNF) description of the positive class. While it is clear that this is sufficient from a logical point of view because every logical expression can be reduced to an equivalent DNF expression, it could nevertheless be the case that more structured representations, which form deep theories by forming intermediate concepts, could be easier to learn, in very much the same way as deep neural networks are able to outperform shallow networks, even though the latter are also universal function approximators. In this paper, we empirically compare deep and shallow rule learning with a uniform general algorithm, which relies on greedy mini-batch based optimization. Our experiments on both artificial and real-world benchmark data indicate that deep rule networks outperform shallow networks.
An Investigation into Mini-Batch Rule Learning
Jun 18, 2021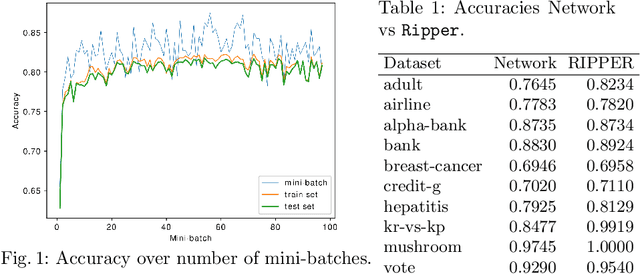
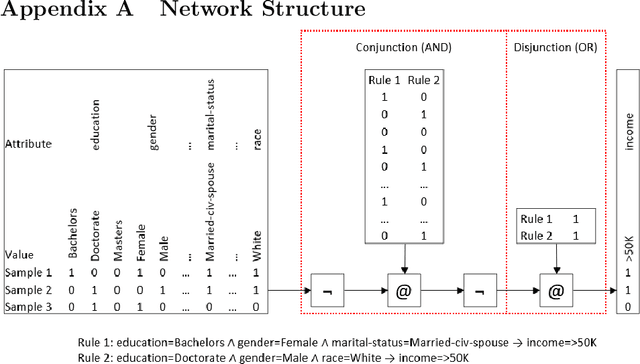
We investigate whether it is possible to learn rule sets efficiently in a network structure with a single hidden layer using iterative refinements over mini-batches of examples. A first rudimentary version shows an acceptable performance on all but one dataset, even though it does not yet reach the performance levels of Ripper.