Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation into Mini-Batch Rule Learning
Paper and Code
Jun 18, 2021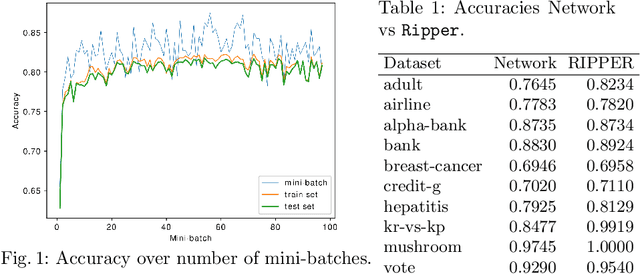
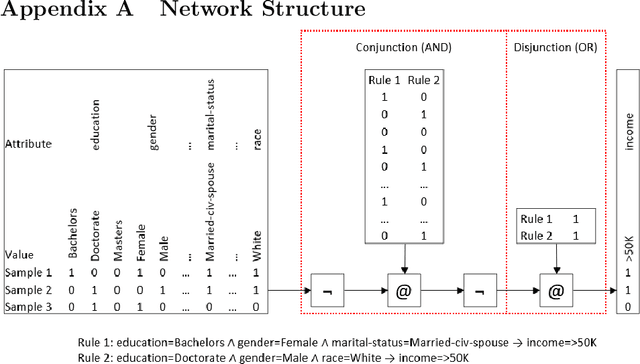
We investigate whether it is possible to learn rule sets efficiently in a network structure with a single hidden layer using iterative refinements over mini-batches of examples. A first rudimentary version shows an acceptable performance on all but one dataset, even though it does not yet reach the performance levels of Ripper.
* 2nd Workshop on Deep Continuous-Discrete Machine Learning
(DeCoDeML), ECML-PKDD 2020, Ghent, Belgium
View paper on