 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFineVLA: Multimodal Reasoning-Aware Generalist Robotic Policies via Teacher-Guided Fine-Tuning
Apr 20, 2026Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into desired robotic actions. Despite their advancements, VLAs often overlook explicit reasoning and learn the functional input-action mappings, omitting crucial logical steps, which are especially pronounced in interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose ReFineVLA, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we fine-tune pre-trained VLAs with the reasoning-enriched datasets with ReFineVLA, while maintaining the underlying generalization abilities and boosting reasoning capabilities. We also conduct attention map visualization to analyze the alignment among visual observation, linguistic prompts, and to-be-executed actions of ReFineVLA, reflecting the model is ability to focus on relevant tasks and actions. Through this additional step, we explore that ReFineVLA-trained models exhibit a meaningful agreement between vision-language and action domains, highlighting the enhanced multimodal understanding and generalization. Evaluated across a suite of simulated manipulation benchmarks on SimplerEnv with both WidowX and Google Robot tasks, ReFineVLA achieves state-of-the-art performance, in success rate over the second-best method on the both the WidowX benchmark and Google Robot Tasks.
Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding
Dec 27, 2025Recent Vision-Language-Action (VLA) models have made impressive progress toward general-purpose robotic manipulation by post-training large Vision-Language Models (VLMs) for action prediction. Yet most VLAs entangle perception and control in a monolithic pipeline optimized purely for action, which can erode language-conditioned grounding. In our real-world tabletop tests, policies over-grasp when the target is absent, are distracted by clutter, and overfit to background appearance. To address these issues, we propose OBEYED-VLA (OBject-centric and gEometrY groundED VLA), a framework that explicitly disentangles perceptual grounding from action reasoning. Instead of operating directly on raw RGB, OBEYED-VLA augments VLAs with a perception module that grounds multi-view inputs into task-conditioned, object-centric, and geometry-aware observations. This module includes a VLM-based object-centric grounding stage that selects task-relevant object regions across camera views, along with a complementary geometric grounding stage that emphasizes the 3D structure of these objects over their appearance. The resulting grounded views are then fed to a pretrained VLA policy, which we fine-tune exclusively on single-object demonstrations collected without environmental clutter or non-target objects. On a real-world UR10e tabletop setup, OBEYED-VLA substantially improves robustness over strong VLA baselines across four challenging regimes and multiple difficulty levels: distractor objects, absent-target rejection, background appearance changes, and cluttered manipulation of unseen objects. Ablation studies confirm that both semantic grounding and geometry-aware grounding are critical to these gains. Overall, the results indicate that making perception an explicit, object-centric component is an effective way to strengthen and generalize VLA-based robotic manipulation.
Learning Human Motion with Temporally Conditional Mamba
Oct 14, 2025Learning human motion based on a time-dependent input signal presents a challenging yet impactful task with various applications. The goal of this task is to generate or estimate human movement that consistently reflects the temporal patterns of conditioning inputs. Existing methods typically rely on cross-attention mechanisms to fuse the condition with motion. However, this approach primarily captures global interactions and struggles to maintain step-by-step temporal alignment. To address this limitation, we introduce Temporally Conditional Mamba, a new mamba-based model for human motion generation. Our approach integrates conditional information into the recurrent dynamics of the Mamba block, enabling better temporally aligned motion. To validate the effectiveness of our method, we evaluate it on a variety of human motion tasks. Extensive experiments demonstrate that our model significantly improves temporal alignment, motion realism, and condition consistency over state-of-the-art approaches. Our project page is available at https://zquang2202.github.io/TCM.
Improving Robotic Manipulation with Efficient Geometry-Aware Vision Encoder
Sep 19, 2025Existing RGB-based imitation learning approaches typically employ traditional vision encoders such as ResNet or ViT, which lack explicit 3D reasoning capabilities. Recent geometry-grounded vision models, such as VGGT~\cite{wang2025vggt}, provide robust spatial understanding and are promising candidates to address this limitation. This work investigates the integration of geometry-aware visual representations into robotic manipulation. Our results suggest that incorporating the geometry-aware vision encoder into imitation learning frameworks, including ACT and DP, yields up to 6.5% improvement over standard vision encoders in success rate across single- and bi-manual manipulation tasks in both simulation and real-world settings. Despite these benefits, most geometry-grounded models require high computational cost, limiting their deployment in practical robotic systems. To address this challenge, we propose eVGGT, an efficient geometry-aware encoder distilled from VGGT. eVGGT is nearly 9 times faster and 5 times smaller than VGGT, while preserving strong 3D reasoning capabilities. Code and pretrained models will be released to facilitate further research in geometry-aware robotics.
Generating Actionable Robot Knowledge Bases by Combining 3D Scene Graphs with Robot Ontologies
Jul 15, 2025In robotics, the effective integration of environmental data into actionable knowledge remains a significant challenge due to the variety and incompatibility of data formats commonly used in scene descriptions, such as MJCF, URDF, and SDF. This paper presents a novel approach that addresses these challenges by developing a unified scene graph model that standardizes these varied formats into the Universal Scene Description (USD) format. This standardization facilitates the integration of these scene graphs with robot ontologies through semantic reporting, enabling the translation of complex environmental data into actionable knowledge essential for cognitive robotic control. We evaluated our approach by converting procedural 3D environments into USD format, which is then annotated semantically and translated into a knowledge graph to effectively answer competency questions, demonstrating its utility for real-time robotic decision-making. Additionally, we developed a web-based visualization tool to support the semantic mapping process, providing users with an intuitive interface to manage the 3D environment.
Efficient Collision Detection for Long and Slender Robotic Links in Euclidean Distance Fields: Application to a Forestry Crane
Jul 02, 2025
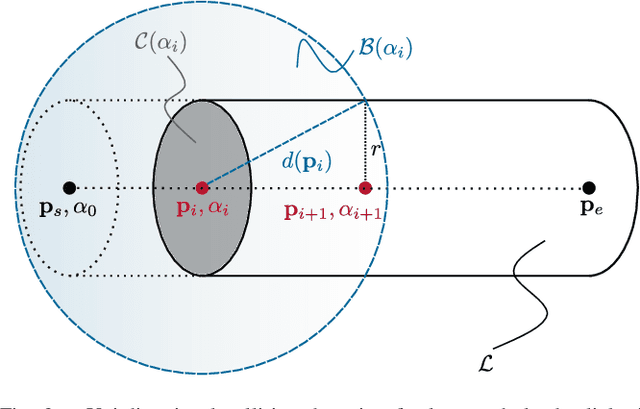
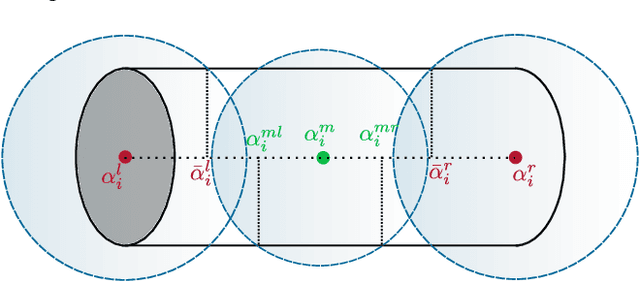

Collision-free motion planning in complex outdoor environments relies heavily on perceiving the surroundings through exteroceptive sensors. A widely used approach represents the environment as a voxelized Euclidean distance field, where robots are typically approximated by spheres. However, for large-scale manipulators such as forestry cranes, which feature long and slender links, this conventional spherical approximation becomes inefficient and inaccurate. This work presents a novel collision detection algorithm specifically designed to exploit the elongated structure of such manipulators, significantly enhancing the computational efficiency of motion planning algorithms. Unlike traditional sphere decomposition methods, our approach not only improves computational efficiency but also naturally eliminates the need to fine-tune the approximation accuracy as an additional parameter. We validate the algorithm's effectiveness using real-world LiDAR data from a forestry crane application, as well as simulated environment data.
Learning Swing-up Maneuvers for a Suspended Aerial Manipulation Platform in a Hierarchical Control Framework
Jun 16, 2025In this work, we present a novel approach to augment a model-based control method with a reinforcement learning (RL) agent and demonstrate a swing-up maneuver with a suspended aerial manipulation platform. These platforms are targeted towards a wide range of applications on construction sites involving cranes, with swing-up maneuvers allowing it to perch at a given location, inaccessible with purely the thrust force of the platform. Our proposed approach is based on a hierarchical control framework, which allows different tasks to be executed according to their assigned priorities. An RL agent is then subsequently utilized to adjust the reference set-point of the lower-priority tasks to perform the swing-up maneuver, which is confined in the nullspace of the higher-priority tasks, such as maintaining a specific orientation and position of the end-effector. Our approach is validated using extensive numerical simulation studies.
DoublyAware: Dual Planning and Policy Awareness for Temporal Difference Learning in Humanoid Locomotion
Jun 12, 2025Achieving robust robot learning for humanoid locomotion is a fundamental challenge in model-based reinforcement learning (MBRL), where environmental stochasticity and randomness can hinder efficient exploration and learning stability. The environmental, so-called aleatoric, uncertainty can be amplified in high-dimensional action spaces with complex contact dynamics, and further entangled with epistemic uncertainty in the models during learning phases. In this work, we propose DoublyAware, an uncertainty-aware extension of Temporal Difference Model Predictive Control (TD-MPC) that explicitly decomposes uncertainty into two disjoint interpretable components, i.e., planning and policy uncertainties. To handle the planning uncertainty, DoublyAware employs conformal prediction to filter candidate trajectories using quantile-calibrated risk bounds, ensuring statistical consistency and robustness against stochastic dynamics. Meanwhile, policy rollouts are leveraged as structured informative priors to support the learning phase with Group-Relative Policy Constraint (GRPC) optimizers that impose a group-based adaptive trust-region in the latent action space. This principled combination enables the robot agent to prioritize high-confidence, high-reward behavior while maintaining effective, targeted exploration under uncertainty. Evaluated on the HumanoidBench locomotion suite with the Unitree 26-DoF H1-2 humanoid, DoublyAware demonstrates improved sample efficiency, accelerated convergence, and enhanced motion feasibility compared to RL baselines. Our simulation results emphasize the significance of structured uncertainty modeling for data-efficient and reliable decision-making in TD-MPC-based humanoid locomotion learning.
ReFineVLA: Reasoning-Aware Teacher-Guided Transfer Fine-Tuning
May 25, 2025
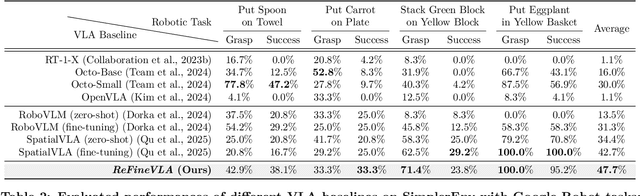

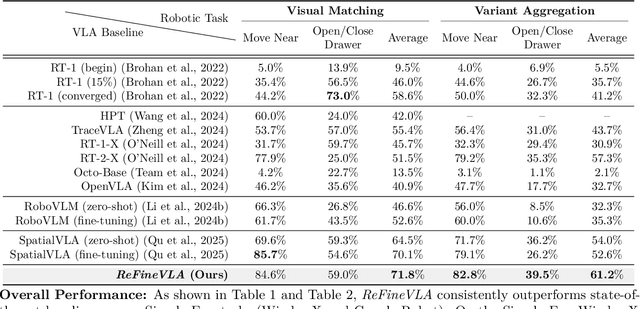
Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into robotic actions. Despite their recent advancements, VLAs often overlook the explicit reasoning and only learn the functional input-action mappings, omitting these crucial logical steps for interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose \textit{ReFineVLA}, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we use \textit{ReFineVLA} to fine-tune pre-trained VLAs with the reasoning-enriched datasets, while maintaining their inherent generalization abilities and boosting reasoning capabilities. In addition, we conduct an attention map visualization to analyze the alignment among visual attention, linguistic prompts, and to-be-executed actions of \textit{ReFineVLA}, showcasing its ability to focus on relevant tasks and actions. Through the latter step, we explore that \textit{ReFineVLA}-trained models exhibit a meaningful attention shift towards relevant objects, highlighting the enhanced multimodal understanding and improved generalization. Evaluated across manipulation tasks, \textit{ReFineVLA} outperforms the state-of-the-art baselines. Specifically, it achieves an average increase of $5.0\%$ success rate on SimplerEnv WidowX Robot tasks, improves by an average of $8.6\%$ in variant aggregation settings, and by $1.7\%$ in visual matching settings for SimplerEnv Google Robot tasks. The source code will be publicly available.
Model Tensor Planning
May 02, 2025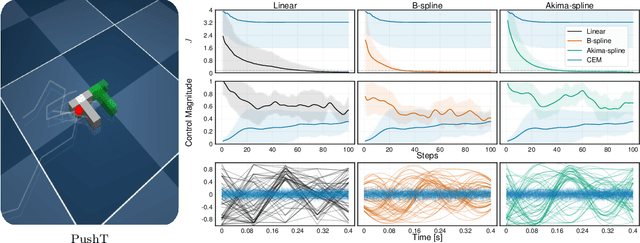
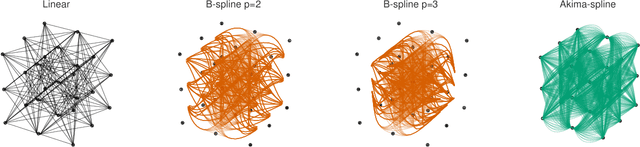

Sampling-based model predictive control (MPC) offers strong performance in nonlinear and contact-rich robotic tasks, yet often suffers from poor exploration due to locally greedy sampling schemes. We propose \emph{Model Tensor Planning} (MTP), a novel sampling-based MPC framework that introduces high-entropy control trajectory generation through structured tensor sampling. By sampling over randomized multipartite graphs and interpolating control trajectories with B-splines and Akima splines, MTP ensures smooth and globally diverse control candidates. We further propose a simple $\beta$-mixing strategy that blends local exploitative and global exploratory samples within the modified Cross-Entropy Method (CEM) update, balancing control refinement and exploration. Theoretically, we show that MTP achieves asymptotic path coverage and maximum entropy in the control trajectory space in the limit of infinite tensor depth and width. Our implementation is fully vectorized using JAX and compatible with MuJoCo XLA, supporting \emph{Just-in-time} (JIT) compilation and batched rollouts for real-time control with online domain randomization. Through experiments on various challenging robotic tasks, ranging from dexterous in-hand manipulation to humanoid locomotion, we demonstrate that MTP outperforms standard MPC and evolutionary strategy baselines in task success and control robustness. Design and sensitivity ablations confirm the effectiveness of MTP tensor sampling structure, spline interpolation choices, and mixing strategy. Altogether, MTP offers a scalable framework for robust exploration in model-based planning and control.