 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoublyAware: Dual Planning and Policy Awareness for Temporal Difference Learning in Humanoid Locomotion
Jun 12, 2025Achieving robust robot learning for humanoid locomotion is a fundamental challenge in model-based reinforcement learning (MBRL), where environmental stochasticity and randomness can hinder efficient exploration and learning stability. The environmental, so-called aleatoric, uncertainty can be amplified in high-dimensional action spaces with complex contact dynamics, and further entangled with epistemic uncertainty in the models during learning phases. In this work, we propose DoublyAware, an uncertainty-aware extension of Temporal Difference Model Predictive Control (TD-MPC) that explicitly decomposes uncertainty into two disjoint interpretable components, i.e., planning and policy uncertainties. To handle the planning uncertainty, DoublyAware employs conformal prediction to filter candidate trajectories using quantile-calibrated risk bounds, ensuring statistical consistency and robustness against stochastic dynamics. Meanwhile, policy rollouts are leveraged as structured informative priors to support the learning phase with Group-Relative Policy Constraint (GRPC) optimizers that impose a group-based adaptive trust-region in the latent action space. This principled combination enables the robot agent to prioritize high-confidence, high-reward behavior while maintaining effective, targeted exploration under uncertainty. Evaluated on the HumanoidBench locomotion suite with the Unitree 26-DoF H1-2 humanoid, DoublyAware demonstrates improved sample efficiency, accelerated convergence, and enhanced motion feasibility compared to RL baselines. Our simulation results emphasize the significance of structured uncertainty modeling for data-efficient and reliable decision-making in TD-MPC-based humanoid locomotion learning.
Model Tensor Planning
May 02, 2025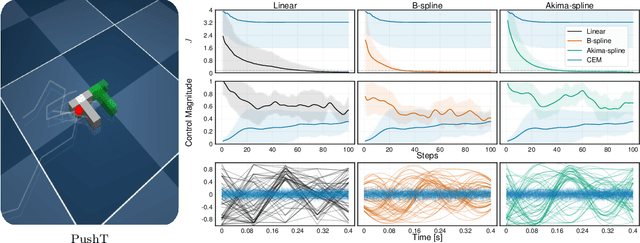
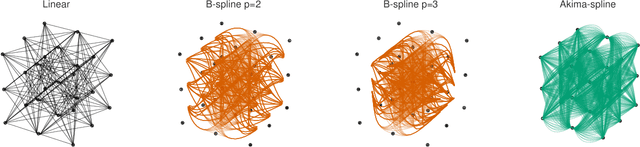

Sampling-based model predictive control (MPC) offers strong performance in nonlinear and contact-rich robotic tasks, yet often suffers from poor exploration due to locally greedy sampling schemes. We propose \emph{Model Tensor Planning} (MTP), a novel sampling-based MPC framework that introduces high-entropy control trajectory generation through structured tensor sampling. By sampling over randomized multipartite graphs and interpolating control trajectories with B-splines and Akima splines, MTP ensures smooth and globally diverse control candidates. We further propose a simple $\beta$-mixing strategy that blends local exploitative and global exploratory samples within the modified Cross-Entropy Method (CEM) update, balancing control refinement and exploration. Theoretically, we show that MTP achieves asymptotic path coverage and maximum entropy in the control trajectory space in the limit of infinite tensor depth and width. Our implementation is fully vectorized using JAX and compatible with MuJoCo XLA, supporting \emph{Just-in-time} (JIT) compilation and batched rollouts for real-time control with online domain randomization. Through experiments on various challenging robotic tasks, ranging from dexterous in-hand manipulation to humanoid locomotion, we demonstrate that MTP outperforms standard MPC and evolutionary strategy baselines in task success and control robustness. Design and sensitivity ablations confirm the effectiveness of MTP tensor sampling structure, spline interpolation choices, and mixing strategy. Altogether, MTP offers a scalable framework for robust exploration in model-based planning and control.
FlowMP: Learning Motion Fields for Robot Planning with Conditional Flow Matching
Mar 08, 2025Prior flow matching methods in robotics have primarily learned velocity fields to morph one distribution of trajectories into another. In this work, we extend flow matching to capture second-order trajectory dynamics, incorporating acceleration effects either explicitly in the model or implicitly through the learning objective. Unlike diffusion models, which rely on a noisy forward process and iterative denoising steps, flow matching trains a continuous transformation (flow) that directly maps a simple prior distribution to the target trajectory distribution without any denoising procedure. By modeling trajectories with second-order dynamics, our approach ensures that generated robot motions are smooth and physically executable, avoiding the jerky or dynamically infeasible trajectories that first-order models might produce. We empirically demonstrate that this second-order conditional flow matching yields superior performance on motion planning benchmarks, achieving smoother trajectories and higher success rates than baseline planners. These findings highlight the advantage of learning acceleration-aware motion fields, as our method outperforms existing motion planning methods in terms of trajectory quality and planning success.
Grasp Diffusion Network: Learning Grasp Generators from Partial Point Clouds with Diffusion Models in SO(3)xR3
Dec 11, 2024



Grasping objects successfully from a single-view camera is crucial in many robot manipulation tasks. An approach to solve this problem is to leverage simulation to create large datasets of pairs of objects and grasp poses, and then learn a conditional generative model that can be prompted quickly during deployment. However, the grasp pose data is highly multimodal since there are several ways to grasp an object. Hence, in this work, we learn a grasp generative model with diffusion models to sample candidate grasp poses given a partial point cloud of an object. A novel aspect of our method is to consider diffusion in the manifold space of rotations and to propose a collision-avoidance cost guidance to improve the grasp success rate during inference. To accelerate grasp sampling we use recent techniques from the diffusion literature to achieve faster inference times. We show in simulation and real-world experiments that our approach can grasp several objects from raw depth images with $90\%$ success rate and benchmark it against several baselines.
Global Tensor Motion Planning
Nov 28, 2024Batch planning is increasingly crucial for the scalability of robotics tasks and dataset generation diversity. This paper presents Global Tensor Motion Planning (GTMP) -- a sampling-based motion planning algorithm comprising only tensor operations. We introduce a novel discretization structure represented as a random multipartite graph, enabling efficient vectorized sampling, collision checking, and search. We provide an early theoretical investigation showing that GTMP exhibits probabilistic completeness while supporting modern GPU/TPU. Additionally, by incorporating smooth structures into the multipartite graph, GTMP directly plans smooth splines without requiring gradient-based optimization. Experiments on lidar-scanned occupancy maps and the MotionBenchMarker dataset demonstrate GTMP's computation efficiency in batch planning compared to baselines, underscoring GTMP's potential as a robust, scalable planner for diverse applications and large-scale robot learning tasks.
Machine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024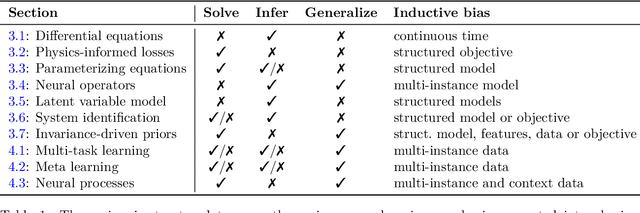
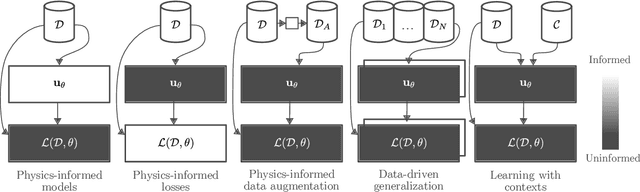
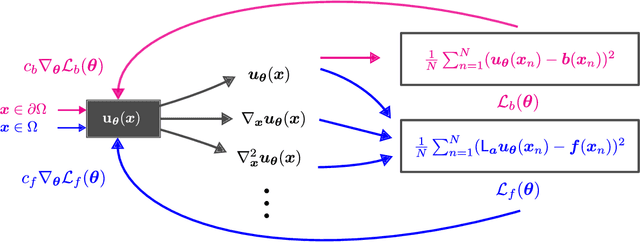
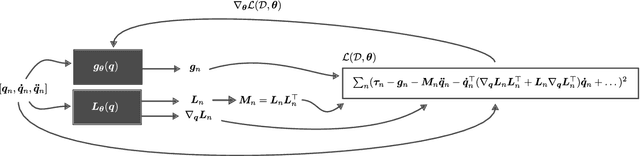
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
Jul 05, 2024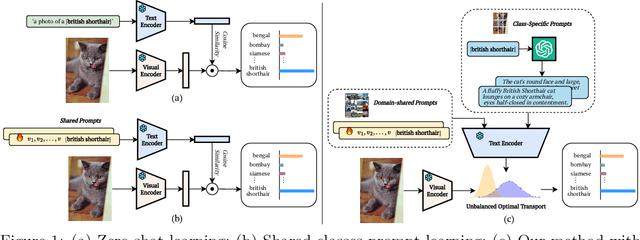
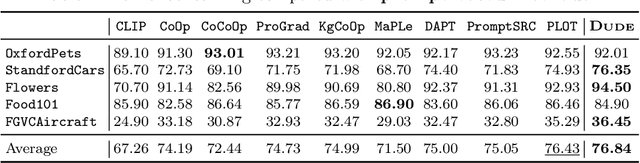
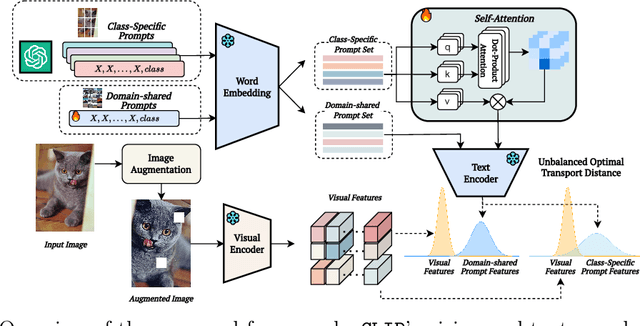
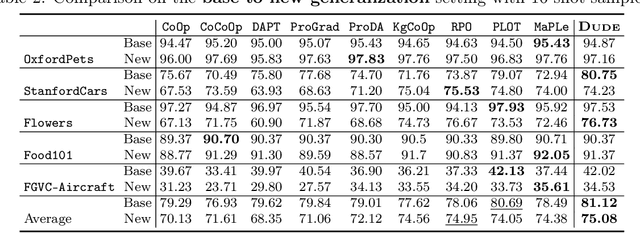
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.
Structure-Aware E(3)-Invariant Molecular Conformer Aggregation Networks
Feb 03, 2024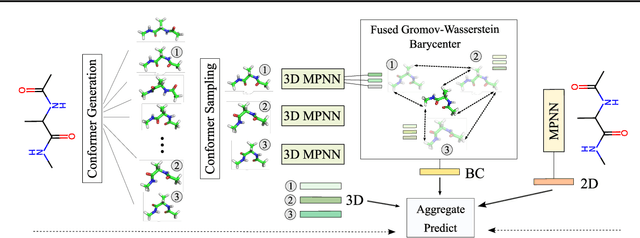

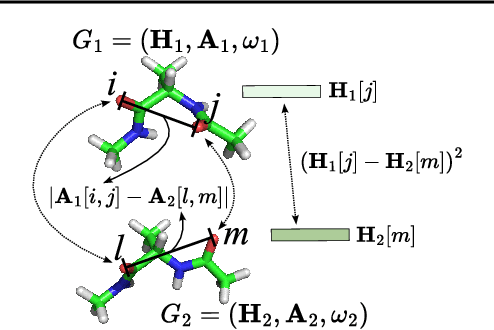

A molecule's 2D representation consists of its atoms, their attributes, and the molecule's covalent bonds. A 3D (geometric) representation of a molecule is called a conformer and consists of its atom types and Cartesian coordinates. Every conformer has a potential energy, and the lower this energy, the more likely it occurs in nature. Most existing machine learning methods for molecular property prediction consider either 2D molecular graphs or 3D conformer structure representations in isolation. Inspired by recent work on using ensembles of conformers in conjunction with 2D graph representations, we propose E(3)-invariant molecular conformer aggregation networks. The method integrates a molecule's 2D representation with that of multiple of its conformers. Contrary to prior work, we propose a novel 2D--3D aggregation mechanism based on a differentiable solver for the \emph{Fused Gromov-Wasserstein Barycenter} problem and the use of an efficient online conformer generation method based on distance geometry. We show that the proposed aggregation mechanism is E(3) invariant and provides an efficient GPU implementation. Moreover, we demonstrate that the aggregation mechanism helps to outperform state-of-the-art property prediction methods on established datasets significantly.
Accelerating Motion Planning via Optimal Transport
Sep 27, 2023Motion planning is still an open problem for many disciplines, e.g., robotics, autonomous driving, due to issues like high planning times that hinder real-time, efficient decision-making. A class of methods striving to provide smooth solutions is gradient-based trajectory optimization. However, those methods might suffer from bad local minima, while for many settings, they may be inapplicable due to the absence of easy access to objectives-gradients. In response to these issues, we introduce Motion Planning via Optimal Transport (MPOT) - a gradient-free method that optimizes a batch of smooth trajectories over highly nonlinear costs, even for high-dimensional tasks, while imposing smoothness through a Gaussian Process dynamics prior via planning-as-inference perspective. To facilitate batch trajectory optimization, we introduce an original zero-order and highly-parallelizable update rule -- the Sinkhorn Step, which uses the regular polytope family for its search directions; each regular polytope, centered on trajectory waypoints, serves as a local neighborhood, effectively acting as a trust region, where the Sinkhorn Step "transports" local waypoints toward low-cost regions. We theoretically show that Sinkhorn Step guides the optimizing parameters toward local minima regions on non-convex objective functions. We then show the efficiency of MPOT in a range of problems from low-dimensional point-mass navigation to high-dimensional whole-body robot motion planning, evincing its superiority compared with popular motion planners and paving the way for new applications of optimal transport in motion planning.
Motion Planning Diffusion: Learning and Planning of Robot Motions with Diffusion Models
Aug 03, 2023Learning priors on trajectory distributions can help accelerate robot motion planning optimization. Given previously successful plans, learning trajectory generative models as priors for a new planning problem is highly desirable. Prior works propose several ways on utilizing this prior to bootstrapping the motion planning problem. Either sampling the prior for initializations or using the prior distribution in a maximum-a-posterior formulation for trajectory optimization. In this work, we propose learning diffusion models as priors. We then can sample directly from the posterior trajectory distribution conditioned on task goals, by leveraging the inverse denoising process of diffusion models. Furthermore, diffusion has been recently shown to effectively encode data multimodality in high-dimensional settings, which is particularly well-suited for large trajectory dataset. To demonstrate our method efficacy, we compare our proposed method - Motion Planning Diffusion - against several baselines in simulated planar robot and 7-dof robot arm manipulator environments. To assess the generalization capabilities of our method, we test it in environments with previously unseen obstacles. Our experiments show that diffusion models are strong priors to encode high-dimensional trajectory distributions of robot motions.