 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024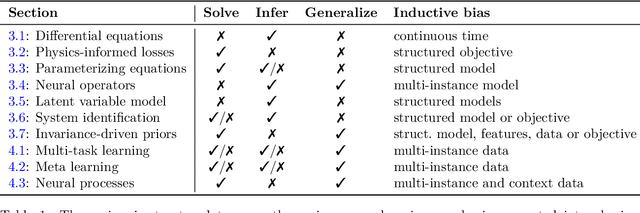
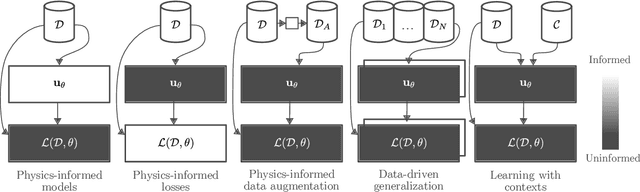
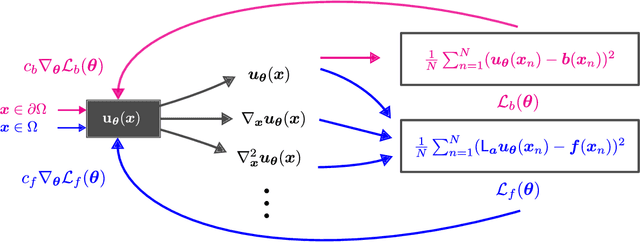
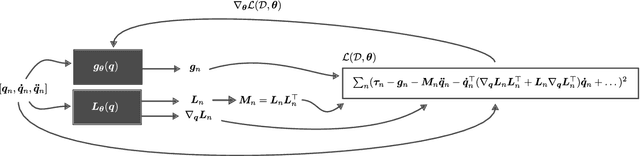
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
Multi-Task Reinforcement Learning with Mixture of Orthogonal Experts
Nov 19, 2023Multi-Task Reinforcement Learning (MTRL) tackles the long-standing problem of endowing agents with skills that generalize across a variety of problems. To this end, sharing representations plays a fundamental role in capturing both unique and common characteristics of the tasks. Tasks may exhibit similarities in terms of skills, objects, or physical properties while leveraging their representations eases the achievement of a universal policy. Nevertheless, the pursuit of learning a shared set of diverse representations is still an open challenge. In this paper, we introduce a novel approach for representation learning in MTRL that encapsulates common structures among the tasks using orthogonal representations to promote diversity. Our method, named Mixture Of Orthogonal Experts (MOORE), leverages a Gram-Schmidt process to shape a shared subspace of representations generated by a mixture of experts. When task-specific information is provided, MOORE generates relevant representations from this shared subspace. We assess the effectiveness of our approach on two MTRL benchmarks, namely MiniGrid and MetaWorld, showing that MOORE surpasses related baselines and establishes a new state-of-the-art result on MetaWorld.
Towards Discriminative and Transferable One-Stage Few-Shot Object Detectors
Oct 11, 2022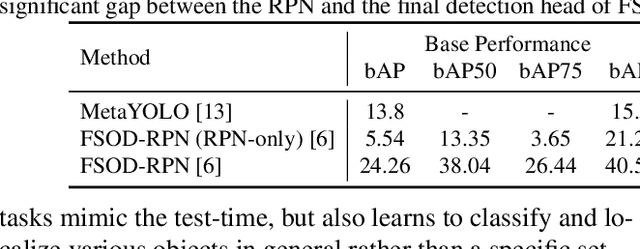
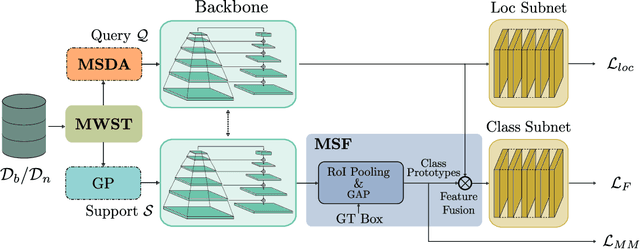
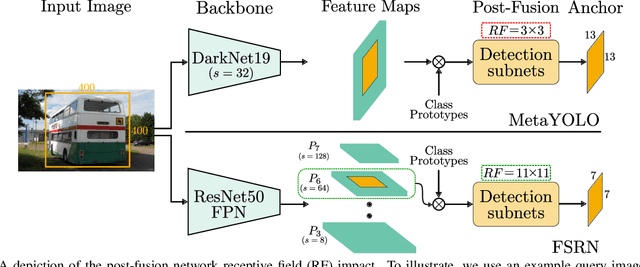
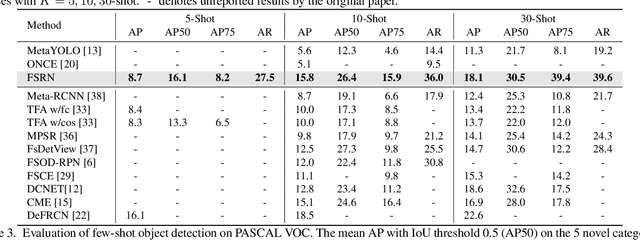
Recent object detection models require large amounts of annotated data for training a new classes of objects. Few-shot object detection (FSOD) aims to address this problem by learning novel classes given only a few samples. While competitive results have been achieved using two-stage FSOD detectors, typically one-stage FSODs underperform compared to them. We make the observation that the large gap in performance between two-stage and one-stage FSODs are mainly due to their weak discriminability, which is explained by a small post-fusion receptive field and a small number of foreground samples in the loss function. To address these limitations, we propose the Few-shot RetinaNet (FSRN) that consists of: a multi-way support training strategy to augment the number of foreground samples for dense meta-detectors, an early multi-level feature fusion providing a wide receptive field that covers the whole anchor area and two augmentation techniques on query and source images to enhance transferability. Extensive experiments show that the proposed approach addresses the limitations and boosts both discriminability and transferability. FSRN is almost two times faster than two-stage FSODs while remaining competitive in accuracy, and it outperforms the state-of-the-art of one-stage meta-detectors and also some two-stage FSODs on the MS-COCO and PASCAL VOC benchmarks.
CFA: Constraint-based Finetuning Approach for Generalized Few-Shot Object Detection
Apr 11, 2022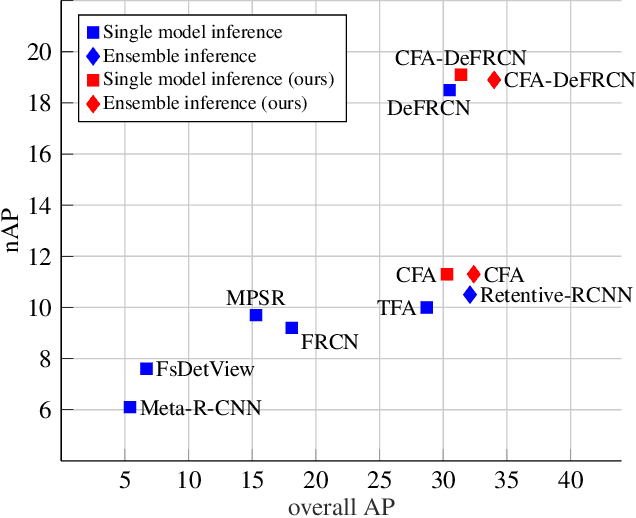
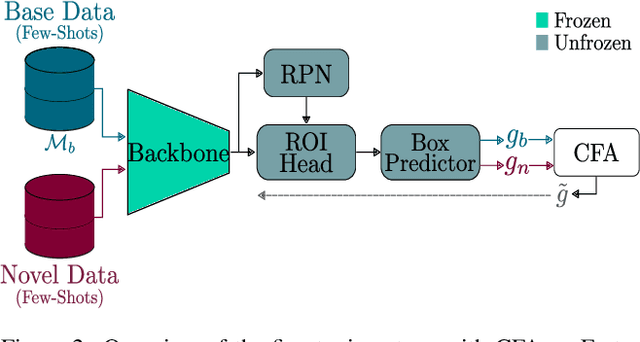
Few-shot object detection (FSOD) seeks to detect novel categories with limited data by leveraging prior knowledge from abundant base data. Generalized few-shot object detection (G-FSOD) aims to tackle FSOD without forgetting previously seen base classes and, thus, accounts for a more realistic scenario, where both classes are encountered during test time. While current FSOD methods suffer from catastrophic forgetting, G-FSOD addresses this limitation yet exhibits a performance drop on novel tasks compared to the state-of-the-art FSOD. In this work, we propose a constraint-based finetuning approach (CFA) to alleviate catastrophic forgetting, while achieving competitive results on the novel task without increasing the model capacity. CFA adapts a continual learning method, namely Average Gradient Episodic Memory (A-GEM) to G-FSOD. Specifically, more constraints on the gradient search strategy are imposed from which a new gradient update rule is derived, allowing for better knowledge exchange between base and novel classes. To evaluate our method, we conduct extensive experiments on MS-COCO and PASCAL-VOC datasets. Our method outperforms current FSOD and G-FSOD approaches on the novel task with minor degeneration on the base task. Moreover, CFA is orthogonal to FSOD approaches and operates as a plug-and-play module without increasing the model capacity or inference time.