 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025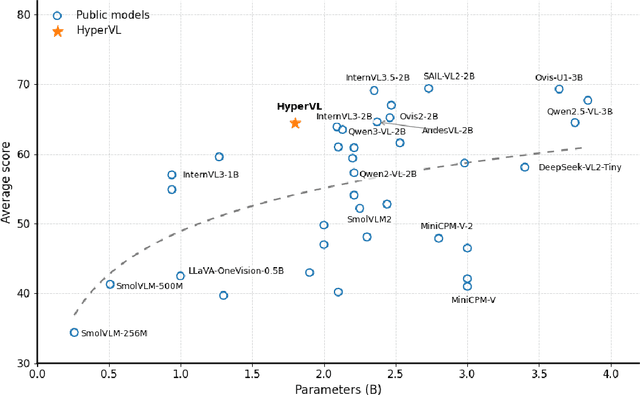

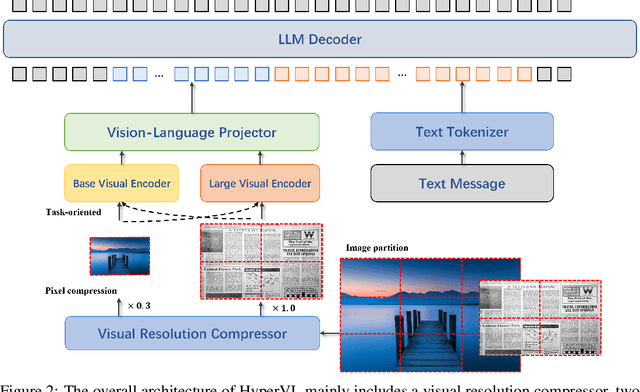

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
PPLNs: Parametric Piecewise Linear Networks for Event-Based Temporal Modeling and Beyond
Sep 29, 2024



We present Parametric Piecewise Linear Networks (PPLNs) for temporal vision inference. Motivated by the neuromorphic principles that regulate biological neural behaviors, PPLNs are ideal for processing data captured by event cameras, which are built to simulate neural activities in the human retina. We discuss how to represent the membrane potential of an artificial neuron by a parametric piecewise linear function with learnable coefficients. This design echoes the idea of building deep models from learnable parametric functions recently popularized by Kolmogorov-Arnold Networks (KANs). Experiments demonstrate the state-of-the-art performance of PPLNs in event-based and image-based vision applications, including steering prediction, human pose estimation, and motion deblurring. The source code of our implementation is available at https://github.com/chensong1995/PPLN.
Machine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024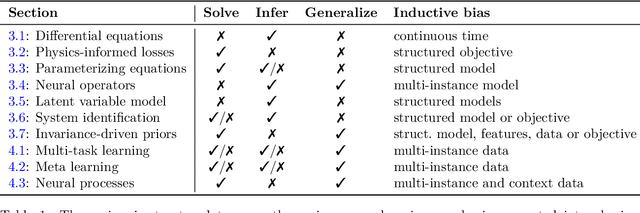
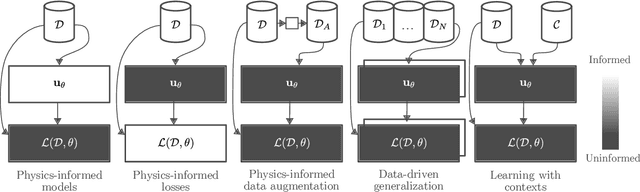
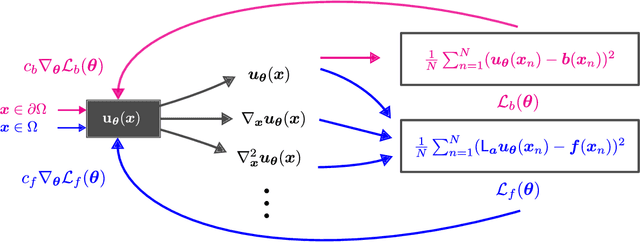
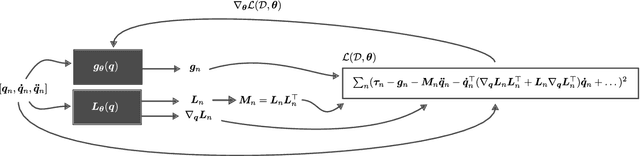
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
TutteNet: Injective 3D Deformations by Composition of 2D Mesh Deformations
Jun 17, 2024



This work proposes a novel representation of injective deformations of 3D space, which overcomes existing limitations of injective methods: inaccuracy, lack of robustness, and incompatibility with general learning and optimization frameworks. The core idea is to reduce the problem to a deep composition of multiple 2D mesh-based piecewise-linear maps. Namely, we build differentiable layers that produce mesh deformations through Tutte's embedding (guaranteed to be injective in 2D), and compose these layers over different planes to create complex 3D injective deformations of the 3D volume. We show our method provides the ability to efficiently and accurately optimize and learn complex deformations, outperforming other injective approaches. As a main application, we produce complex and artifact-free NeRF and SDF deformations.
An Optimization Framework to Enforce Multi-View Consistency for Texturing 3D Meshes Using Pre-Trained Text-to-Image Models
Mar 22, 2024



A fundamental problem in the texturing of 3D meshes using pre-trained text-to-image models is to ensure multi-view consistency. State-of-the-art approaches typically use diffusion models to aggregate multi-view inputs, where common issues are the blurriness caused by the averaging operation in the aggregation step or inconsistencies in local features. This paper introduces an optimization framework that proceeds in four stages to achieve multi-view consistency. Specifically, the first stage generates an over-complete set of 2D textures from a predefined set of viewpoints using an MV-consistent diffusion process. The second stage selects a subset of views that are mutually consistent while covering the underlying 3D model. We show how to achieve this goal by solving semi-definite programs. The third stage performs non-rigid alignment to align the selected views across overlapping regions. The fourth stage solves an MRF problem to associate each mesh face with a selected view. In particular, the third and fourth stages are iterated, with the cuts obtained in the fourth stage encouraging non-rigid alignment in the third stage to focus on regions close to the cuts. Experimental results show that our approach significantly outperforms baseline approaches both qualitatively and quantitatively.
Detecting Any Human-Object Interaction Relationship: Universal HOI Detector with Spatial Prompt Learning on Foundation Models
Nov 07, 2023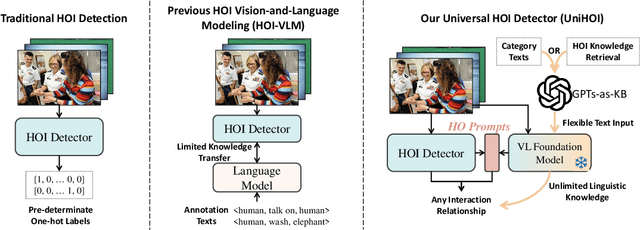
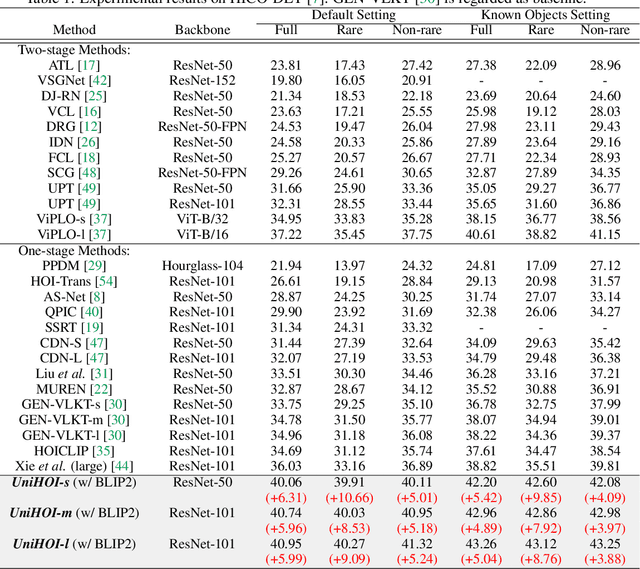
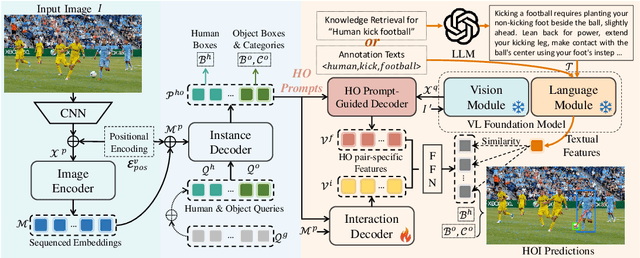
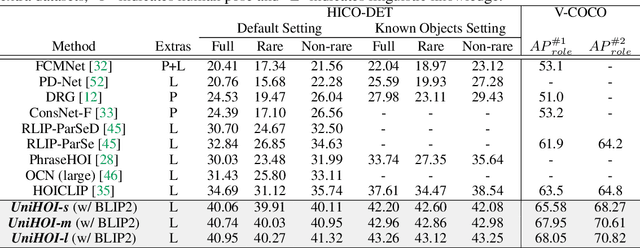
Human-object interaction (HOI) detection aims to comprehend the intricate relationships between humans and objects, predicting $<human, action, object>$ triplets, and serving as the foundation for numerous computer vision tasks. The complexity and diversity of human-object interactions in the real world, however, pose significant challenges for both annotation and recognition, particularly in recognizing interactions within an open world context. This study explores the universal interaction recognition in an open-world setting through the use of Vision-Language (VL) foundation models and large language models (LLMs). The proposed method is dubbed as \emph{\textbf{UniHOI}}. We conduct a deep analysis of the three hierarchical features inherent in visual HOI detectors and propose a method for high-level relation extraction aimed at VL foundation models, which we call HO prompt-based learning. Our design includes an HO Prompt-guided Decoder (HOPD), facilitates the association of high-level relation representations in the foundation model with various HO pairs within the image. Furthermore, we utilize a LLM (\emph{i.e.} GPT) for interaction interpretation, generating a richer linguistic understanding for complex HOIs. For open-category interaction recognition, our method supports either of two input types: interaction phrase or interpretive sentence. Our efficient architecture design and learning methods effectively unleash the potential of the VL foundation models and LLMs, allowing UniHOI to surpass all existing methods with a substantial margin, under both supervised and zero-shot settings. The code and pre-trained weights are available at: \url{https://github.com/Caoyichao/UniHOI}.
Learning from Multi-View Representation for Point-Cloud Pre-Training
Jun 05, 2023



A critical problem in the pre-training of 3D point clouds is leveraging massive 2D data. A fundamental challenge is to address the 2D-3D domain gap. This paper proposes a novel approach to point-cloud pre-training that enables learning 3D representations by leveraging pre-trained 2D-based networks. In particular, it avoids overfitting to 2D representations and potentially discarding critical 3D features for 3D recognition tasks. The key to our approach is a novel multi-view representation, which learns a shared 3D feature volume consistent with deep features extracted from multiple 2D camera views. The 2D deep features are regularized using pre-trained 2D networks through the 2D knowledge transfer loss. To prevent the resulting 3D feature representations from discarding 3D signals, we introduce the multi-view consistency loss that forces the projected 2D feature representations to capture pixel-wise correspondences across different views. Such correspondences induce 3D geometry and effectively retain 3D features in the projected 2D features. Experimental results demonstrate that our pre-trained model can be successfully transferred to various downstream tasks, including 3D detection and semantic segmentation, and achieve state-of-the-art performance.
LiDAR-Based 3D Object Detection via Hybrid 2D Semantic Scene Generation
Apr 04, 2023Bird's-Eye View (BEV) features are popular intermediate scene representations shared by the 3D backbone and the detector head in LiDAR-based object detectors. However, little research has been done to investigate how to incorporate additional supervision on the BEV features to improve proposal generation in the detector head, while still balancing the number of powerful 3D layers and efficient 2D network operations. This paper proposes a novel scene representation that encodes both the semantics and geometry of the 3D environment in 2D, which serves as a dense supervision signal for better BEV feature learning. The key idea is to use auxiliary networks to predict a combination of explicit and implicit semantic probabilities by exploiting their complementary properties. Extensive experiments show that our simple yet effective design can be easily integrated into most state-of-the-art 3D object detectors and consistently improves upon baseline models.
DeblurSR: Event-Based Motion Deblurring Under the Spiking Representation
Mar 15, 2023

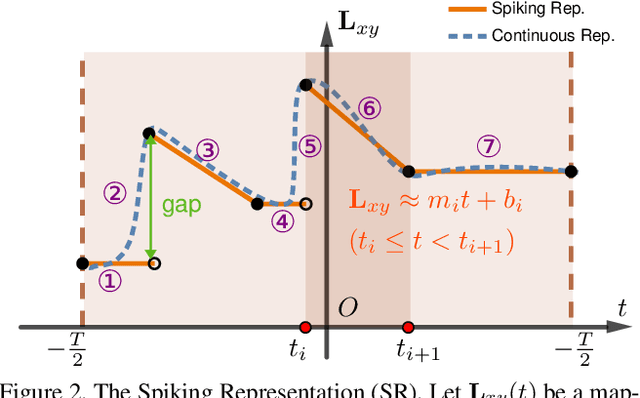

We present DeblurSR, a novel motion deblurring approach that converts a blurry image into a sharp video. DeblurSR utilizes event data to compensate for motion ambiguities and exploits the spiking representation to parameterize the sharp output video as a mapping from time to intensity. Our key contribution, the Spiking Representation (SR), is inspired by the neuromorphic principles determining how biological neurons communicate with each other in living organisms. We discuss why the spikes can represent sharp edges and how the spiking parameters are interpreted from the neuromorphic perspective. DeblurSR has higher output quality and requires fewer computing resources than state-of-the-art event-based motion deblurring methods. We additionally show that our approach easily extends to video super-resolution when combined with recent advances in implicit neural representation. The implementation and animated visualization of DeblurSR are available at https://github.com/chensong1995/DeblurSR.
Deep Anomaly Detection on Tennessee Eastman Process Data
Mar 10, 2023This paper provides the first comprehensive evaluation and analysis of modern (deep-learning) unsupervised anomaly detection methods for chemical process data. We focus on the Tennessee Eastman process dataset, which has been a standard litmus test to benchmark anomaly detection methods for nearly three decades. Our extensive study will facilitate choosing appropriate anomaly detection methods in industrial applications.