 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation Risk Bounds for Kolmogorov-Arnold Networks Trained by DP-SGD with Correlated Noise
May 12, 2026We establish the first population risk bounds for Kolmogorov-Arnold Networks (KANs) trained by mini-batch SGD with gradient clipping, covering non-private SGD as well as differentially private SGD (DP-SGD) with Gaussian perturbations that interpolate between independent and temporally correlated noise. This setting is substantially closer to practice than prior KAN theory along two axes: training is by mini-batch SGD, the standard recipe for modern networks, rather than full-batch gradient descent (GD); and correlated-noise mechanisms have empirically shown a more favorable privacy-utility tradeoff than independent-noise mechanisms. Our results cover the corresponding full-batch GD and independent-noise DP-GD results for KANs by Wang et al. (2026), while yielding sharper fixed-second-layer specializations. The technical core is a new analysis route for correlated-noise DP training in the non-convex regime. Temporal dependence breaks the conditional-centering structure underlying standard one-step SGD arguments, and the projection step obstructs the exact cancellation structure of correlated perturbations. We address these difficulties through an auxiliary unprojected dynamics, a shifted iterate that absorbs the current noise perturbation, and a high-probability bootstrap certifying projection inactivity. Combining this optimization analysis with a stability-based generalization argument yields the stated population risk bounds. To the best of our knowledge, this is the first optimization and population risk analysis of a correlated-noise mechanism for DP training beyond convex learning, in particular for neural networks.
Skipping the Zeros in Diffusion Models for Sparse Data Generation
May 03, 2026Diffusion models (DMs) excel on dense continuous data, but are not designed for sparse continuous data. They do not model exact zeros that represent the deliberate absence of a signal. As a result, they erase sparsity patterns and perform unnecessary computation on mostly zero entries. With Sparsity-Exploiting Diffusion (SED), we model only non-zero values, preserving sparsity. SED delivers computational savings while maintaining or improving generation quality by skipping zeros during training and inference. Across physics and biology benchmarks, SED matches or surpasses conventional DMs and domain-specific baselines, while vision experiments provide intuitive insights into the limitations of dense DMs and the benefits of SED.
Superstudent intelligence in thermodynamics
Jun 11, 2025In this short note, we report and analyze a striking event: OpenAI's large language model o3 has outwitted all students in a university exam on thermodynamics. The thermodynamics exam is a difficult hurdle for most students, where they must show that they have mastered the fundamentals of this important topic. Consequently, the failure rates are very high, A-grades are rare - and they are considered proof of the students' exceptional intellectual abilities. This is because pattern learning does not help in the exam. The problems can only be solved by knowledgeably and creatively combining principles of thermodynamics. We have given our latest thermodynamics exam not only to the students but also to OpenAI's most powerful reasoning model, o3, and have assessed the answers of o3 exactly the same way as those of the students. In zero-shot mode, the model o3 solved all problems correctly, better than all students who took the exam; its overall score was in the range of the best scores we have seen in more than 10,000 similar exams since 1985. This is a turning point: machines now excel in complex tasks, usually taken as proof of human intellectual capabilities. We discuss the consequences this has for the work of engineers and the education of future engineers.
Multi-level Supervised Contrastive Learning
Feb 05, 2025



Contrastive learning is a well-established paradigm in representation learning. The standard framework of contrastive learning minimizes the distance between "similar" instances and maximizes the distance between dissimilar ones in the projection space, disregarding the various aspects of similarity that can exist between two samples. Current methods rely on a single projection head, which fails to capture the full complexity of different aspects of a sample, leading to suboptimal performance, especially in scenarios with limited training data. In this paper, we present a novel supervised contrastive learning method in a unified framework called multilevel contrastive learning (MLCL), that can be applied to both multi-label and hierarchical classification tasks. The key strength of the proposed method is the ability to capture similarities between samples across different labels and/or hierarchies using multiple projection heads. Extensive experiments on text and image datasets demonstrate that the proposed approach outperforms state-of-the-art contrastive learning methods
Sparse Data Generation Using Diffusion Models
Feb 04, 2025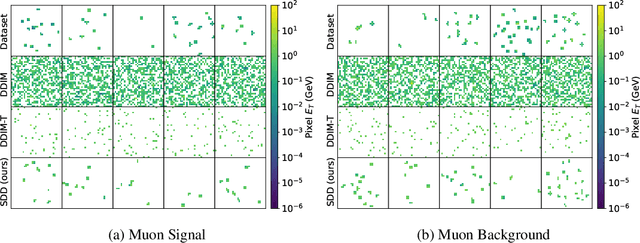
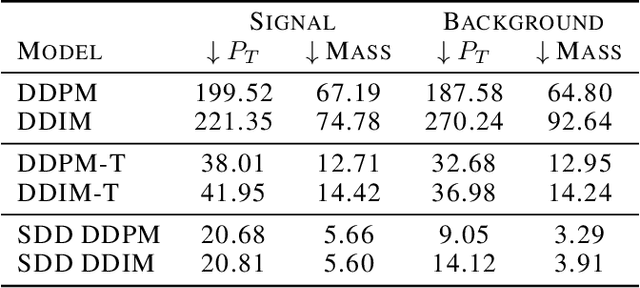
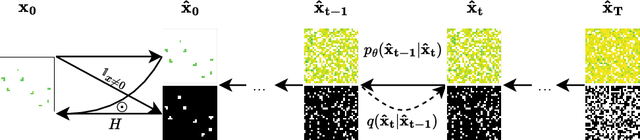
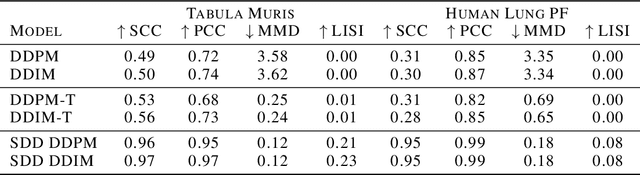
Sparse data is ubiquitous, appearing in numerous domains, from economics and recommender systems to astronomy and biomedical sciences. However, efficiently and realistically generating sparse data remains a significant challenge. We introduce Sparse Data Diffusion (SDD), a novel method for generating sparse data. SDD extends continuous state-space diffusion models by explicitly modeling sparsity through the introduction of Sparsity Bits. Empirical validation on image data from various domains-including two scientific applications, physics and biology-demonstrates that SDD achieves high fidelity in representing data sparsity while preserving the quality of the generated data.
Challenging Assumptions in Learning Generic Text Style Embeddings
Jan 27, 2025


Recent advancements in language representation learning primarily emphasize language modeling for deriving meaningful representations, often neglecting style-specific considerations. This study addresses this gap by creating generic, sentence-level style embeddings crucial for style-centric tasks. Our approach is grounded on the premise that low-level text style changes can compose any high-level style. We hypothesize that applying this concept to representation learning enables the development of versatile text style embeddings. By fine-tuning a general-purpose text encoder using contrastive learning and standard cross-entropy loss, we aim to capture these low-level style shifts, anticipating that they offer insights applicable to high-level text styles. The outcomes prompt us to reconsider the underlying assumptions as the results do not always show that the learned style representations capture high-level text styles.
BBPOS: BERT-based Part-of-Speech Tagging for Uzbek
Jan 17, 2025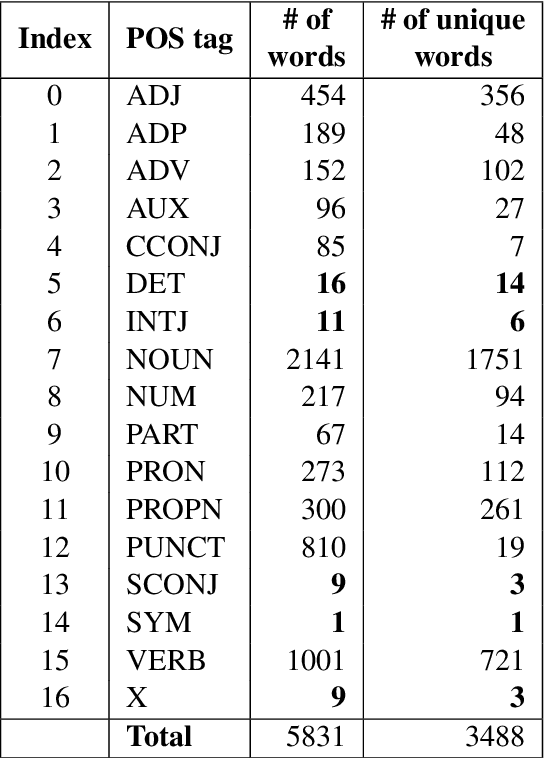
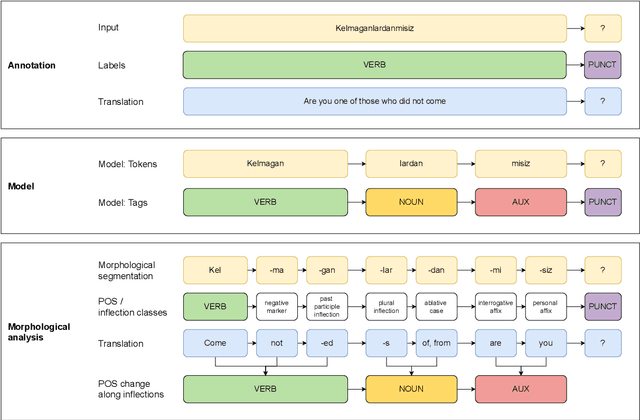

This paper advances NLP research for the low-resource Uzbek language by evaluating two previously untested monolingual Uzbek BERT models on the part-of-speech (POS) tagging task and introducing the first publicly available UPOS-tagged benchmark dataset for Uzbek. Our fine-tuned models achieve 91% average accuracy, outperforming the baseline multi-lingual BERT as well as the rule-based tagger. Notably, these models capture intermediate POS changes through affixes and demonstrate context sensitivity, unlike existing rule-based taggers.
Towards Graph Foundation Models: A Study on the Generalization of Positional and Structural Encodings
Dec 10, 2024Recent advances in integrating positional and structural encodings (PSEs) into graph neural networks (GNNs) have significantly enhanced their performance across various graph learning tasks. However, the general applicability of these encodings and their potential to serve as foundational representations for graphs remain uncertain. This paper investigates the fine-tuning efficiency, scalability with sample size, and generalization capability of learnable PSEs across diverse graph datasets. Specifically, we evaluate their potential as universal pre-trained models that can be easily adapted to new tasks with minimal fine-tuning and limited data. Furthermore, we assess the expressivity of the learned representations, particularly, when used to augment downstream GNNs. We demonstrate through extensive benchmarking and empirical analysis that PSEs generally enhance downstream models. However, some datasets may require specific PSE-augmentations to achieve optimal performance. Nevertheless, our findings highlight their significant potential to become integral components of future graph foundation models. We provide new insights into the strengths and limitations of PSEs, contributing to the broader discourse on foundation models in graph learning.
Tethering Broken Themes: Aligning Neural Topic Models with Labels and Authors
Oct 22, 2024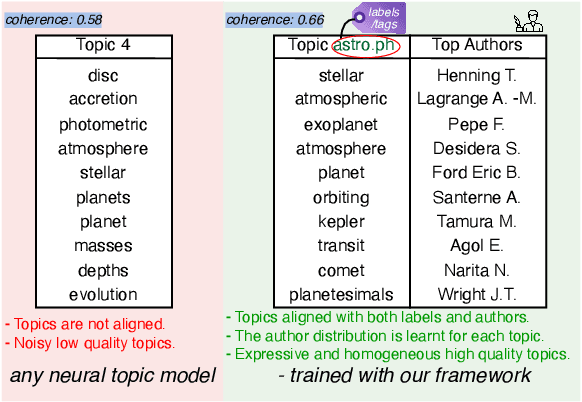
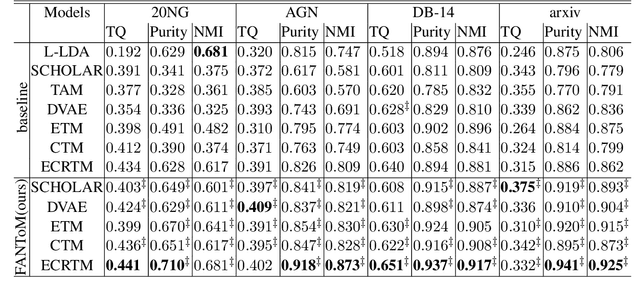
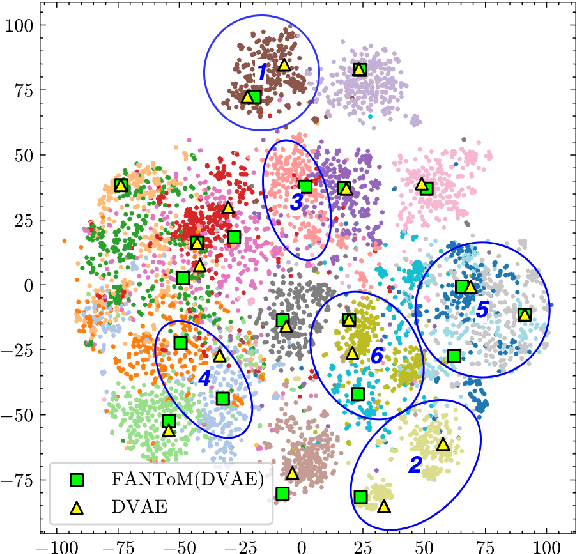
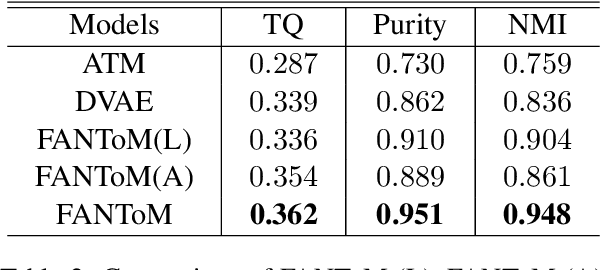
Topic models are a popular approach for extracting semantic information from large document collections. However, recent studies suggest that the topics generated by these models often do not align well with human intentions. While metadata such as labels and authorship information is available, it has not yet been effectively incorporated into neural topic models. To address this gap, we introduce FANToM, a novel method for aligning neural topic models with both labels and authorship information. FANToM allows for the inclusion of this metadata when available, producing interpretable topics and author distributions for each topic. Our approach demonstrates greater expressiveness than conventional topic models by learning the alignment between labels, topics, and authors. Experimental results show that FANToM improves upon existing models in terms of both topic quality and alignment. Additionally, it identifies author interests and similarities.
SetPINNs: Set-based Physics-informed Neural Networks
Sep 30, 2024Physics-Informed Neural Networks (PINNs) have emerged as a promising method for approximating solutions to partial differential equations (PDEs) using deep learning. However, PINNs, based on multilayer perceptrons (MLP), often employ point-wise predictions, overlooking the implicit dependencies within the physical system such as temporal or spatial dependencies. These dependencies can be captured using more complex network architectures, for example CNNs or Transformers. However, these architectures conventionally do not allow for incorporating physical constraints, as advancements in integrating such constraints within these frameworks are still lacking. Relying on point-wise predictions often results in trivial solutions. To address this limitation, we propose SetPINNs, a novel approach inspired by Finite Elements Methods from the field of Numerical Analysis. SetPINNs allow for incorporating the dependencies inherent in the physical system while at the same time allowing for incorporating the physical constraints. They accurately approximate PDE solutions of a region, thereby modeling the inherent dependencies between multiple neighboring points in that region. Our experiments show that SetPINNs demonstrate superior generalization performance and accuracy across diverse physical systems, showing that they mitigate failure modes and converge faster in comparison to existing approaches. Furthermore, we demonstrate the utility of SetPINNs on two real-world physical systems.