 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Supervised Contrastive Learning
Feb 05, 2025



Contrastive learning is a well-established paradigm in representation learning. The standard framework of contrastive learning minimizes the distance between "similar" instances and maximizes the distance between dissimilar ones in the projection space, disregarding the various aspects of similarity that can exist between two samples. Current methods rely on a single projection head, which fails to capture the full complexity of different aspects of a sample, leading to suboptimal performance, especially in scenarios with limited training data. In this paper, we present a novel supervised contrastive learning method in a unified framework called multilevel contrastive learning (MLCL), that can be applied to both multi-label and hierarchical classification tasks. The key strength of the proposed method is the ability to capture similarities between samples across different labels and/or hierarchies using multiple projection heads. Extensive experiments on text and image datasets demonstrate that the proposed approach outperforms state-of-the-art contrastive learning methods
ARAE: Adversarially Robust Training of Autoencoders Improves Novelty Detection
Mar 12, 2020
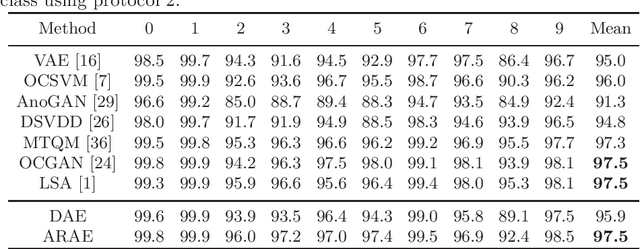
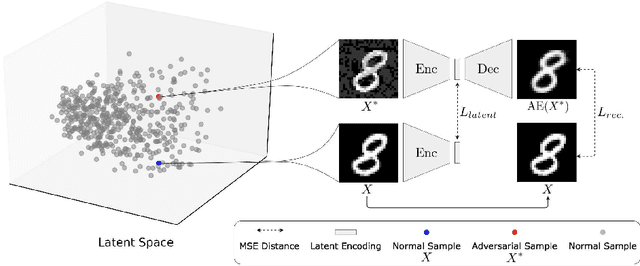

Autoencoders (AE) have recently been widely employed to approach the novelty detection problem. Trained only on the normal data, the AE is expected to reconstruct the normal data effectively while fail to regenerate the anomalous data, which could be utilized for novelty detection. However, in this paper, it is demonstrated that this does not always hold. AE often generalizes so perfectly that it can also reconstruct the anomalous data well. To address this problem, we propose a novel AE that can learn more semantically meaningful features. Specifically, we exploit the fact that adversarial robustness promotes learning of meaningful features. Therefore, we force the AE to learn such features by penalizing networks with a bottleneck layer that is unstable against adversarial perturbations. We show that despite using a much simpler architecture in comparison to the prior methods, the proposed AE outperforms or is competitive to state-of-the-art on three benchmark datasets.