 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Impression for Learning with Distributed Heterogeneous Data
Sep 11, 2024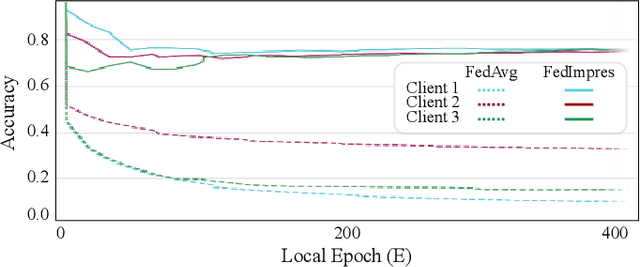
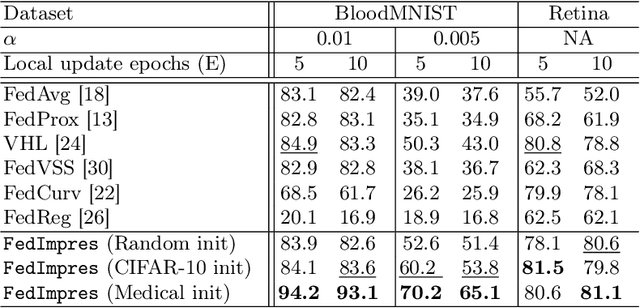
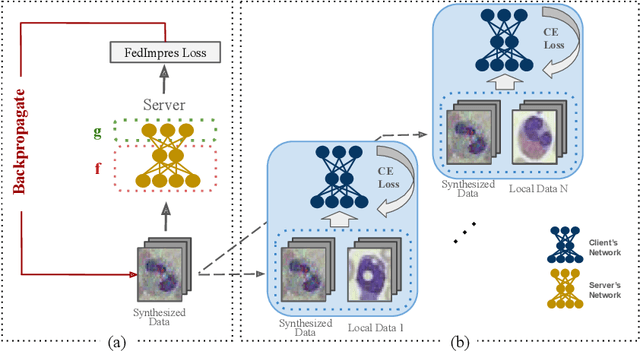

Standard deep learning-based classification approaches may not always be practical in real-world clinical applications, as they require a centralized collection of all samples. Federated learning (FL) provides a paradigm that can learn from distributed datasets across clients without requiring them to share data, which can help mitigate privacy and data ownership issues. In FL, sub-optimal convergence caused by data heterogeneity is common among data from different health centers due to the variety in data collection protocols and patient demographics across centers. Through experimentation in this study, we show that data heterogeneity leads to the phenomenon of catastrophic forgetting during local training. We propose FedImpres which alleviates catastrophic forgetting by restoring synthetic data that represents the global information as federated impression. To achieve this, we distill the global model resulting from each communication round. Subsequently, we use the synthetic data alongside the local data to enhance the generalization of local training. Extensive experiments show that the proposed method achieves state-of-the-art performance on both the BloodMNIST and Retina datasets, which contain label imbalance and domain shift, with an improvement in classification accuracy of up to 20%.
Adversarial Attack by Limited Point Cloud Surface Modifications
Oct 07, 2021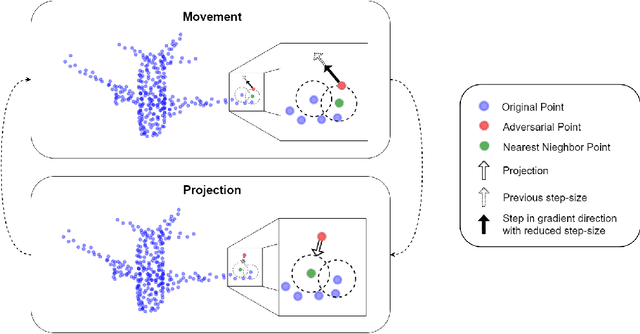
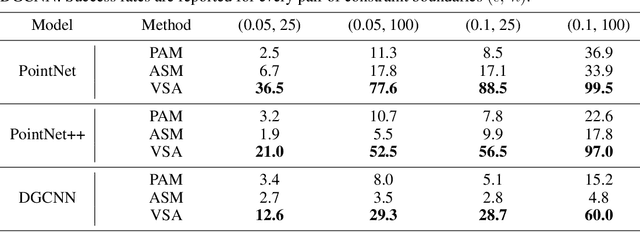

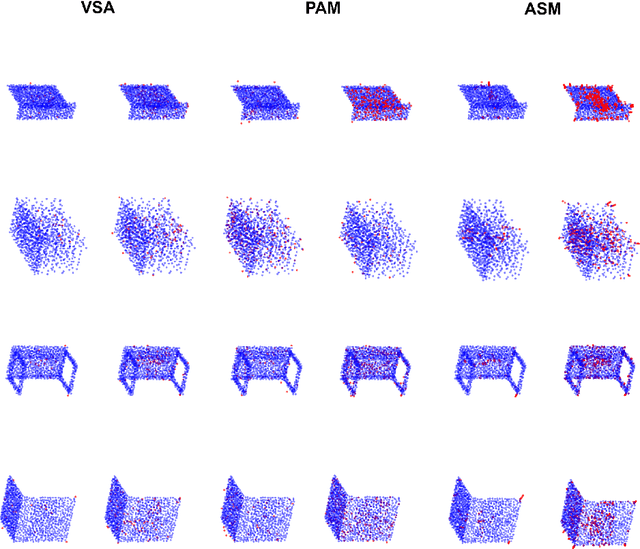
Recent research has revealed that the security of deep neural networks that directly process 3D point clouds to classify objects can be threatened by adversarial samples. Although existing adversarial attack methods achieve high success rates, they do not restrict the point modifications enough to preserve the point cloud appearance. To overcome this shortcoming, two constraints are proposed. These include applying hard boundary constraints on the number of modified points and on the point perturbation norms. Due to the restrictive nature of the problem, the search space contains many local maxima. The proposed method addresses this issue by using a high step-size at the beginning of the algorithm to search the main surface of the point cloud fast and effectively. Then, in order to converge to the desired output, the step-size is gradually decreased. To evaluate the performance of the proposed method, it is run on the ModelNet40 and ScanObjectNN datasets by employing the state-of-the-art point cloud classification models; including PointNet, PointNet++, and DGCNN. The obtained results show that it can perform successful attacks and achieve state-of-the-art results by only a limited number of point modifications while preserving the appearance of the point cloud. Moreover, due to the effective search algorithm, it can perform successful attacks in just a few steps. Additionally, the proposed step-size scheduling algorithm shows an improvement of up to $14.5\%$ when adopted by other methods as well. The proposed method also performs effectively against popular defense methods.
ARAE: Adversarially Robust Training of Autoencoders Improves Novelty Detection
Mar 12, 2020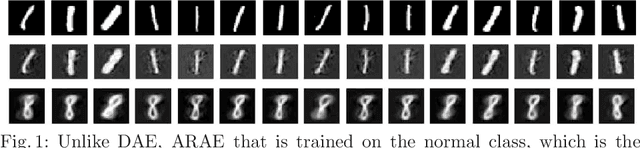
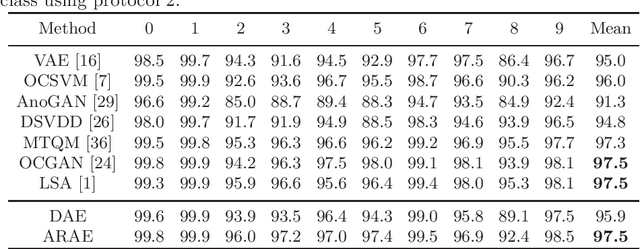
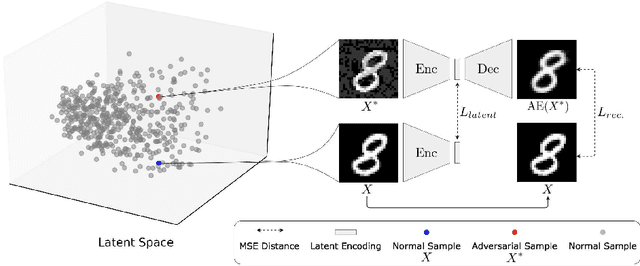

Autoencoders (AE) have recently been widely employed to approach the novelty detection problem. Trained only on the normal data, the AE is expected to reconstruct the normal data effectively while fail to regenerate the anomalous data, which could be utilized for novelty detection. However, in this paper, it is demonstrated that this does not always hold. AE often generalizes so perfectly that it can also reconstruct the anomalous data well. To address this problem, we propose a novel AE that can learn more semantically meaningful features. Specifically, we exploit the fact that adversarial robustness promotes learning of meaningful features. Therefore, we force the AE to learn such features by penalizing networks with a bottleneck layer that is unstable against adversarial perturbations. We show that despite using a much simpler architecture in comparison to the prior methods, the proposed AE outperforms or is competitive to state-of-the-art on three benchmark datasets.