 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Impression for Learning with Distributed Heterogeneous Data
Paper and Code
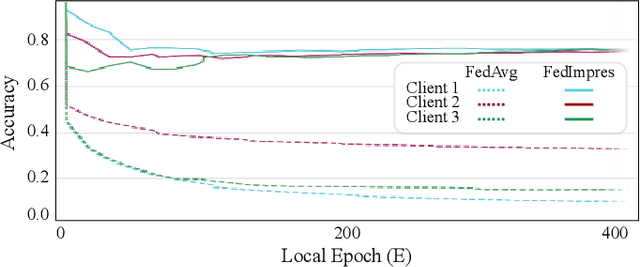
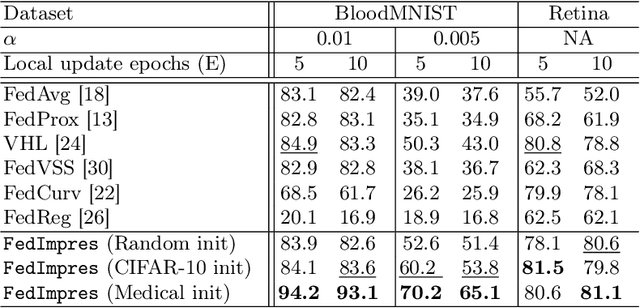
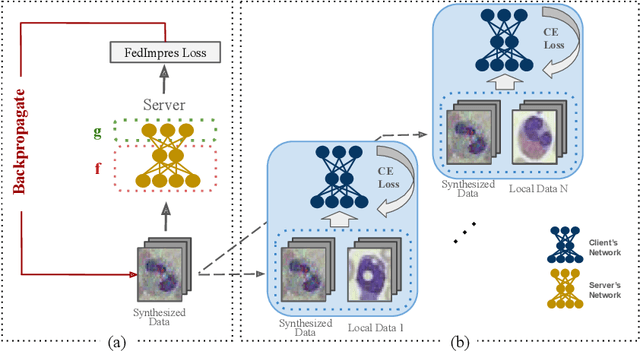

Standard deep learning-based classification approaches may not always be practical in real-world clinical applications, as they require a centralized collection of all samples. Federated learning (FL) provides a paradigm that can learn from distributed datasets across clients without requiring them to share data, which can help mitigate privacy and data ownership issues. In FL, sub-optimal convergence caused by data heterogeneity is common among data from different health centers due to the variety in data collection protocols and patient demographics across centers. Through experimentation in this study, we show that data heterogeneity leads to the phenomenon of catastrophic forgetting during local training. We propose FedImpres which alleviates catastrophic forgetting by restoring synthetic data that represents the global information as federated impression. To achieve this, we distill the global model resulting from each communication round. Subsequently, we use the synthetic data alongside the local data to enhance the generalization of local training. Extensive experiments show that the proposed method achieves state-of-the-art performance on both the BloodMNIST and Retina datasets, which contain label imbalance and domain shift, with an improvement in classification accuracy of up to 20%.