 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC Learning with Bandit Feedback: Sharp Sample Complexity in the Realizable Setting
May 26, 2026We study the problem of multiclass PAC learning with bandit feedback in the realizable setting. In this framework, there is an unknown data distribution over an instance space $\mathcal{X}$ and a label space $\mathcal{Y}$, as in classical multiclass PAC learning, but the learner does not observe the labels of the i.i.d. training examples. Instead, in each round, it receives an unlabeled instance, predicts its label, and receives bandit feedback indicating only whether the prediction is correct. Despite this restriction, the goal remains the same as in classical PAC learning. We provide a general characterization of the optimal sample complexity of this problem, sharp for every concept class up to logarithmic factors. Our characterization is based on a new combinatorial dimension, termed the bandit $\mathrm{DS}$ dimension, defined via generalized combinatorial structures we call pseudo-boxes. These extend the pseudo-cubes underlying the $\mathrm{DS}$ dimension by allowing a different number of neighbors in each coordinate. In contrast to the $\mathrm{DS}$ dimension, which governs the full-information setting by counting the number of coordinates in the pseudo-cube, the bandit $\mathrm{DS}$ dimension aggregates the number of neighbors across coordinates, leading to a characterization in which the sample complexity scales with the total number of neighbors. We also propose a general learning algorithm achieving the upper bound, based on an algorithmic principle called ListCascade, which connects bandit learning to list learning and may be of independent interest.
An Optimal Sauer Lemma Over $k$-ary Alphabets
Apr 14, 2026The Sauer-Shelah-Perles Lemma is a cornerstone of combinatorics and learning theory, bounding the size of a binary hypothesis class in terms of its Vapnik-Chervonenkis (VC) dimension. For classes of functions over a $k$-ary alphabet, namely the multiclass setting, the Natarajan dimension has long served as an analogue of VC dimension, yet the corresponding Sauer-type bounds are suboptimal for alphabet sizes $k>2$. In this work, we establish a sharp Sauer inequality for multiclass and list prediction. Our bound is expressed in terms of the Daniely--Shalev-Shwartz (DS) dimension, and more generally with its extension, the list-DS dimension -- the combinatorial parameters that characterize multiclass and list PAC learnability. Our bound is tight for every alphabet size $k$, list size $\ell$, and dimension value, replacing the exponential dependence on $\ell$ in the Natarajan-based bound by the optimal polynomial dependence, and improving the dependence on $k$ as well. Our proof uses the polynomial method. In contrast to the classical VC case, where several direct combinatorial proofs are known, we are not aware of any purely combinatorial proof in the DS setting. This motivates several directions for future research, which are discussed in the paper. As consequences, we obtain improved sample complexity upper bounds for list PAC learning and for uniform convergence of list predictors, sharpening the recent results of Charikar et al.~(STOC~2023), Hanneke et al.~(COLT~2024), and Brukhim et al.~(NeurIPS~2024).
Multiclass Transductive Online Learning
Nov 03, 2024We consider the problem of multiclass transductive online learning when the number of labels can be unbounded. Previous works by Ben-David et al. [1997] and Hanneke et al. [2023b] only consider the case of binary and finite label spaces, respectively. The latter work determined that their techniques fail to extend to the case of unbounded label spaces, and they pose the question of characterizing the optimal mistake bound for unbounded label spaces. We answer this question by showing that a new dimension, termed the Level-constrained Littlestone dimension, characterizes online learnability in this setting. Along the way, we show that the trichotomy of possible minimax rates of the expected number of mistakes established by Hanneke et al. [2023b] for finite label spaces in the realizable setting continues to hold even when the label space is unbounded. In particular, if the learner plays for $T \in \mathbb{N}$ rounds, its minimax expected number of mistakes can only grow like $\Theta(T)$, $\Theta(\log T)$, or $\Theta(1)$. To prove this result, we give another combinatorial dimension, termed the Level-constrained Branching dimension, and show that its finiteness characterizes constant minimax expected mistake-bounds. The trichotomy is then determined by a combination of the Level-constrained Littlestone and Branching dimensions. Quantitatively, our upper bounds improve upon existing multiclass upper bounds in Hanneke et al. [2023b] by removing the dependence on the label set size. In doing so, we explicitly construct learning algorithms that can handle extremely large or unbounded label spaces. A key and novel component of our algorithm is a new notion of shattering that exploits the sequential nature of transductive online learning. Finally, we complete our results by proving expected regret bounds in the agnostic setting, extending the result of Hanneke et al. [2023b].
Towards Deep Learning Models Resistant to Large Perturbations
Mar 30, 2020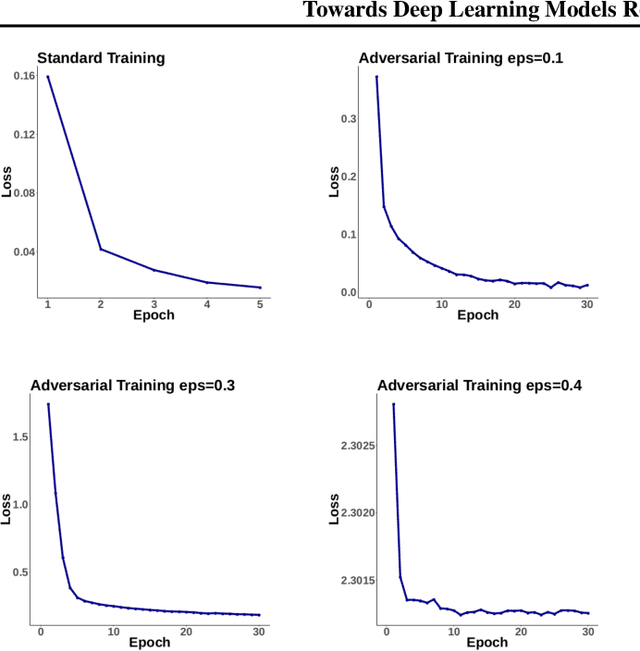
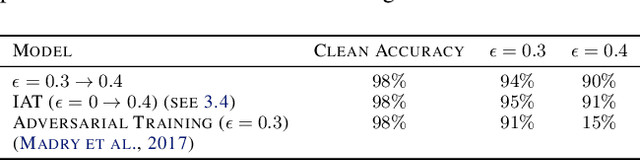
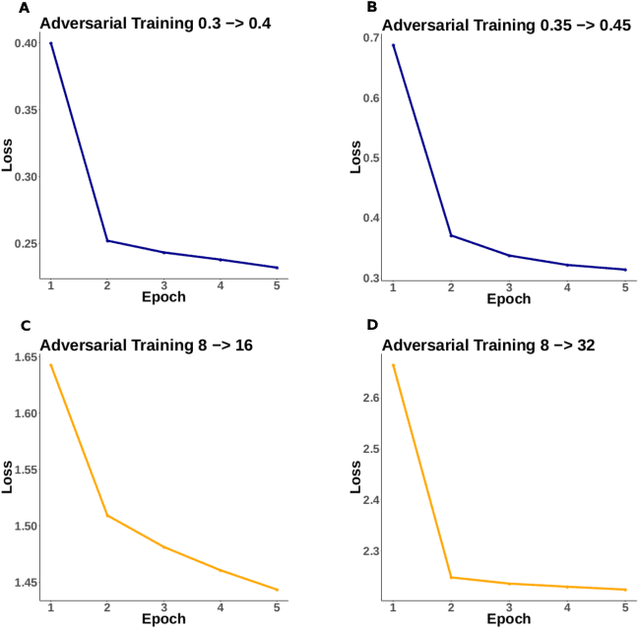

Adversarial robustness has proven to be a required property of machine learning algorithms. A key and often overlooked aspect of this problem is to try to make the adversarial noise magnitude as large as possible to enhance the benefits of the model robustness. We show that the well-established algorithm called "adversarial training" fails to train a deep neural network given a large, but reasonable, perturbation magnitude. In this paper, we propose a simple yet effective initialization of the network weights that makes learning on higher levels of noise possible. We next evaluate this idea rigorously on MNIST ($\epsilon$ up to $\approx 0.40$) and CIFAR10 ($\epsilon$ up to $\approx 32/255$) datasets assuming the $\ell_{\infty}$ attack model. Additionally, in order to establish the limits of $\epsilon$ in which the learning is feasible, we study the optimal robust classifier assuming full access to the joint data and label distribution. Then, we provide some theoretical results on the adversarial accuracy for a simple multi-dimensional Bernoulli distribution, which yields some insights on the range of feasible perturbations for the MNIST dataset.
ARAE: Adversarially Robust Training of Autoencoders Improves Novelty Detection
Mar 12, 2020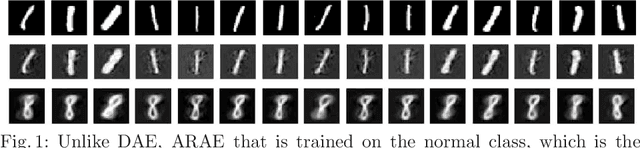
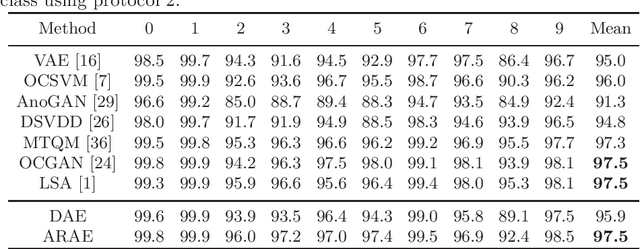
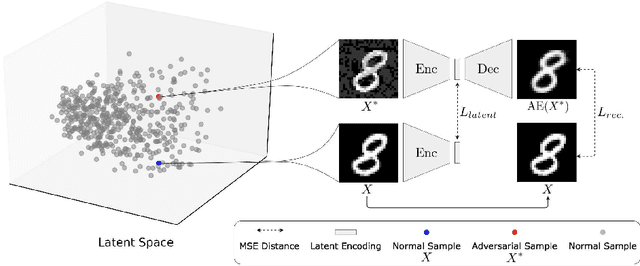

Autoencoders (AE) have recently been widely employed to approach the novelty detection problem. Trained only on the normal data, the AE is expected to reconstruct the normal data effectively while fail to regenerate the anomalous data, which could be utilized for novelty detection. However, in this paper, it is demonstrated that this does not always hold. AE often generalizes so perfectly that it can also reconstruct the anomalous data well. To address this problem, we propose a novel AE that can learn more semantically meaningful features. Specifically, we exploit the fact that adversarial robustness promotes learning of meaningful features. Therefore, we force the AE to learn such features by penalizing networks with a bottleneck layer that is unstable against adversarial perturbations. We show that despite using a much simpler architecture in comparison to the prior methods, the proposed AE outperforms or is competitive to state-of-the-art on three benchmark datasets.