 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-rithmetic
Feb 11, 2026Modern AI systems have been successfully deployed to win medals at international math competitions, assist with research workflows, and prove novel technical lemmas. However, despite their progress at advanced levels of mathematics, they remain stubbornly bad at basic arithmetic, consistently failing on the simple task of adding two numbers. We present a systematic investigation of this phenomenon. We demonstrate empirically that all frontier models suffer significantly degraded accuracy for integer addition as the number of digits increases. Furthermore, we show that most errors made by these models are highly interpretable and can be attributed to either operand misalignment or a failure to correctly carry; these two error classes explain 87.9%, 62.9%, and 92.4% of Claude Opus 4.1, GPT-5, and Gemini 2.5 Pro errors, respectively. Finally, we show that misalignment errors are frequently related to tokenization, and that carrying errors appear largely as independent random failures.
On Generation in Metric Spaces
Feb 07, 2026We study generation in separable metric instance spaces. We extend the language generation framework from Kleinberg and Mullainathan [2024] beyond countable domains by defining novelty through metric separation and allowing asymmetric novelty parameters for the adversary and the generator. We introduce the $(\varepsilon,\varepsilon')$-closure dimension, a scale-sensitive analogue of closure dimension, which yields characterizations of uniform and non-uniform generatability and a sufficient condition for generation in the limit. Along the way, we identify a sharp geometric contrast. Namely, in doubling spaces, including all finite-dimensional normed spaces, generatability is stable across novelty scales and invariant under equivalent metrics. In general metric spaces, however, generatability can be highly scale-sensitive and metric-dependent; even in the natural infinite-dimensional Hilbert space $\ell^2$, all notions of generation may fail abruptly as the novelty parameters vary.
Optimal Stopping vs Best-of-$N$ for Inference Time Optimization
Oct 01, 2025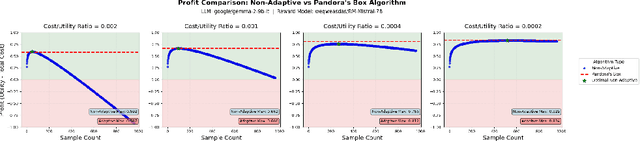
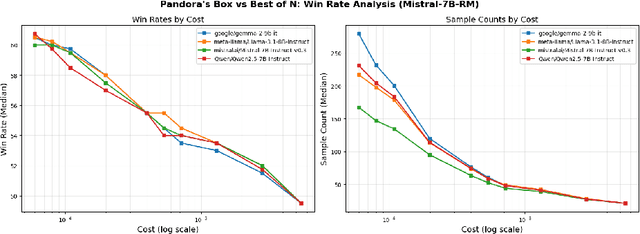
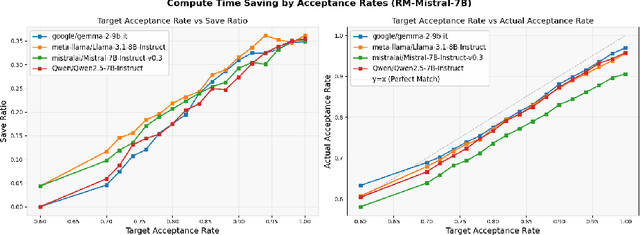
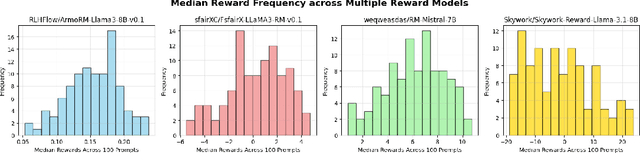
Large language model (LLM) generation often requires balancing output quality against inference cost, especially when using multiple generations. We introduce a new framework for inference-time optimization based on the classical Pandora's Box problem. Viewing each generation as opening a costly "box" with random reward, we develop algorithms that decide when to stop generating without knowing the underlying reward distribution. Our first contribution is a UCB-style Pandora's Box algorithm, which achieves performance that is provably close to Weitzman's algorithm, the optimal strategy when the distribution is known. We further adapt this method to practical LLM settings by addressing reward scaling across prompts via a Bradley-Terry inspired transformation. This leads to an adaptive inference-time optimization method that normalizes rewards and learns stopping thresholds on the fly. Experiments on the AlpacaFarm and HH-RLHF datasets, using multiple LLM-reward model pairs, show that our adaptive strategy can obtain the same performance as non-adaptive Best-of-N sampling while requiring 15-35 percent fewer generations on average. Our results establish a principled bridge between optimal stopping theory and inference-time scaling, providing both theoretical performance bounds and practical efficiency gains for LLM deployment.
Representative Language Generation
May 27, 2025We introduce "representative generation," extending the theoretical framework for generation proposed by Kleinberg et al. (2024) and formalized by Li et al. (2024), to additionally address diversity and bias concerns in generative models. Our notion requires outputs of a generative model to proportionally represent groups of interest from the training data. We characterize representative uniform and non-uniform generation, introducing the "group closure dimension" as a key combinatorial quantity. For representative generation in the limit, we analyze both information-theoretic and computational aspects, demonstrating feasibility for countably infinite hypothesis classes and collections of groups under certain conditions, but proving a negative result for computability using only membership queries. This contrasts with Kleinberg et al.'s (2024) positive results for standard generation in the limit. Our findings provide a rigorous foundation for developing more diverse and representative generative models.
Faster Rates for Private Adversarial Bandits
May 27, 2025


We design new differentially private algorithms for the problems of adversarial bandits and bandits with expert advice. For adversarial bandits, we give a simple and efficient conversion of any non-private bandit algorithm to a private bandit algorithm. Instantiating our conversion with existing non-private bandit algorithms gives a regret upper bound of $O\left(\frac{\sqrt{KT}}{\sqrt{\epsilon}}\right)$, improving upon the existing upper bound $O\left(\frac{\sqrt{KT \log(KT)}}{\epsilon}\right)$ for all $\epsilon \leq 1$. In particular, our algorithms allow for sublinear expected regret even when $\epsilon \leq \frac{1}{\sqrt{T}}$, establishing the first known separation between central and local differential privacy for this problem. For bandits with expert advice, we give the first differentially private algorithms, with expected regret $O\left(\frac{\sqrt{NT}}{\sqrt{\epsilon}}\right), O\left(\frac{\sqrt{KT\log(N)}\log(KT)}{\epsilon}\right)$, and $\tilde{O}\left(\frac{N^{1/6}K^{1/2}T^{2/3}\log(NT)}{\epsilon ^{1/3}} + \frac{N^{1/2}\log(NT)}{\epsilon}\right)$, where $K$ and $N$ are the number of actions and experts respectively. These rates allow us to get sublinear regret for different combinations of small and large $K, N$ and $\epsilon.$
Learning to Choose or Choosing to Learn: Best-of-N vs. Supervised Fine-Tuning for Bit String Generation
May 22, 2025Using the bit string generation problem as a case study, we theoretically compare two standard methods for adapting large language models to new tasks. The first, referred to as supervised fine-tuning, involves training a new next token predictor on good generations. The second method, Best-of-N, trains a reward model to select good responses from a collection generated by an unaltered base model. If the learning setting is realizable, we find that supervised fine-tuning outperforms BoN through a better dependence on the response length in its rate of convergence. If realizability fails, then depending on the failure mode, BoN can enjoy a better rate of convergence in either n or a rate of convergence with better dependence on the response length.
ABoN: Adaptive Best-of-N Alignment
May 17, 2025



Recent advances in test-time alignment methods, such as Best-of-N sampling, offer a simple and effective way to steer language models (LMs) toward preferred behaviors using reward models (RM). However, these approaches can be computationally expensive, especially when applied uniformly across prompts without accounting for differences in alignment difficulty. In this work, we propose a prompt-adaptive strategy for Best-of-N alignment that allocates inference-time compute more efficiently. Motivated by latency concerns, we develop a two-stage algorithm: an initial exploratory phase estimates the reward distribution for each prompt using a small exploration budget, and a second stage adaptively allocates the remaining budget using these estimates. Our method is simple, practical, and compatible with any LM/RM combination. Empirical results on the AlpacaEval dataset for 12 LM/RM pairs and 50 different batches of prompts show that our adaptive strategy consistently outperforms the uniform allocation with the same inference budget. Moreover, our experiments show that our adaptive strategy remains competitive against uniform allocations with 20% larger inference budgets and even improves in performance as the batch size grows.
Tracking the Best Expert Privately
Mar 12, 2025We design differentially private algorithms for the problem of prediction with expert advice under dynamic regret, also known as tracking the best expert. Our work addresses three natural types of adversaries, stochastic with shifting distributions, oblivious, and adaptive, and designs algorithms with sub-linear regret for all three cases. In particular, under a shifting stochastic adversary where the distribution may shift $S$ times, we provide an $\epsilon$-differentially private algorithm whose expected dynamic regret is at most $O\left( \sqrt{S T \log (NT)} + \frac{S \log (NT)}{\epsilon}\right)$, where $T$ and $N$ are the epsilon horizon and number of experts, respectively. For oblivious adversaries, we give a reduction from dynamic regret minimization to static regret minimization, resulting in an upper bound of $O\left(\sqrt{S T \log(NT)} + \frac{S T^{1/3}\log(T/\delta) \log(NT)}{\epsilon^{2/3}}\right)$ on the expected dynamic regret, where $S$ now denotes the allowable number of switches of the best expert. Finally, similar to static regret, we establish a fundamental separation between oblivious and adaptive adversaries for the dynamic setting: while our algorithms show that sub-linear regret is achievable for oblivious adversaries in the high-privacy regime $\epsilon \le \sqrt{S/T}$, we show that any $(\epsilon, \delta)$-differentially private algorithm must suffer linear dynamic regret under adaptive adversaries for $\epsilon \le \sqrt{S/T}$. Finally, to complement this lower bound, we give an $\epsilon$-differentially private algorithm that attains sub-linear dynamic regret under adaptive adversaries whenever $\epsilon \gg \sqrt{S/T}$.
Generation from Noisy Examples
Jan 07, 2025We continue to study the learning-theoretic foundations of generation by extending the results from Kleinberg and Mullainathan [2024] and Li et al. [2024] to account for noisy example streams. In the noiseless setting of Kleinberg and Mullainathan [2024] and Li et al. [2024], an adversary picks a hypothesis from a binary hypothesis class and provides a generator with a sequence of its positive examples. The goal of the generator is to eventually output new, unseen positive examples. In the noisy setting, an adversary still picks a hypothesis and a sequence of its positive examples. But, before presenting the stream to the generator, the adversary inserts a finite number of negative examples. Unaware of which examples are noisy, the goal of the generator is to still eventually output new, unseen positive examples. In this paper, we provide necessary and sufficient conditions for when a binary hypothesis class can be noisily generatable. We provide such conditions with respect to various constraints on the number of distinct examples that need to be seen before perfect generation of positive examples. Interestingly, for finite and countable classes we show that generatability is largely unaffected by the presence of a finite number of noisy examples.
Multiclass Transductive Online Learning
Nov 03, 2024We consider the problem of multiclass transductive online learning when the number of labels can be unbounded. Previous works by Ben-David et al. [1997] and Hanneke et al. [2023b] only consider the case of binary and finite label spaces, respectively. The latter work determined that their techniques fail to extend to the case of unbounded label spaces, and they pose the question of characterizing the optimal mistake bound for unbounded label spaces. We answer this question by showing that a new dimension, termed the Level-constrained Littlestone dimension, characterizes online learnability in this setting. Along the way, we show that the trichotomy of possible minimax rates of the expected number of mistakes established by Hanneke et al. [2023b] for finite label spaces in the realizable setting continues to hold even when the label space is unbounded. In particular, if the learner plays for $T \in \mathbb{N}$ rounds, its minimax expected number of mistakes can only grow like $\Theta(T)$, $\Theta(\log T)$, or $\Theta(1)$. To prove this result, we give another combinatorial dimension, termed the Level-constrained Branching dimension, and show that its finiteness characterizes constant minimax expected mistake-bounds. The trichotomy is then determined by a combination of the Level-constrained Littlestone and Branching dimensions. Quantitatively, our upper bounds improve upon existing multiclass upper bounds in Hanneke et al. [2023b] by removing the dependence on the label set size. In doing so, we explicitly construct learning algorithms that can handle extremely large or unbounded label spaces. A key and novel component of our algorithm is a new notion of shattering that exploits the sequential nature of transductive online learning. Finally, we complete our results by proving expected regret bounds in the agnostic setting, extending the result of Hanneke et al. [2023b].