 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations of refinement methods for weak to strong generalization
Aug 23, 2025



Standard techniques for aligning large language models (LLMs) utilize human-produced data, which could limit the capability of any aligned LLM to human level. Label refinement and weak training have emerged as promising strategies to address this superalignment problem. In this work, we adopt probabilistic assumptions commonly used to study label refinement and analyze whether refinement can be outperformed by alternative approaches, including computationally intractable oracle methods. We show that both weak training and label refinement suffer from irreducible error, leaving a performance gap between label refinement and the oracle. These results motivate future research into developing alternative methods for weak to strong generalization that synthesize the practicality of label refinement or weak training and the optimality of the oracle procedure.
Learning to Choose or Choosing to Learn: Best-of-N vs. Supervised Fine-Tuning for Bit String Generation
May 22, 2025Using the bit string generation problem as a case study, we theoretically compare two standard methods for adapting large language models to new tasks. The first, referred to as supervised fine-tuning, involves training a new next token predictor on good generations. The second method, Best-of-N, trains a reward model to select good responses from a collection generated by an unaltered base model. If the learning setting is realizable, we find that supervised fine-tuning outperforms BoN through a better dependence on the response length in its rate of convergence. If realizability fails, then depending on the failure mode, BoN can enjoy a better rate of convergence in either n or a rate of convergence with better dependence on the response length.
CARROT: A Cost Aware Rate Optimal Router
Feb 05, 2025



With the rapid growth in the number of Large Language Models (LLMs), there has been a recent interest in LLM routing, or directing queries to the cheapest LLM that can deliver a suitable response. Following this line of work, we introduce CARROT, a Cost AwaRe Rate Optimal rouTer that can select models based on any desired trade-off between performance and cost. Given a query, CARROT selects a model based on estimates of models' cost and performance. Its simplicity lends CARROT computational efficiency, while our theoretical analysis demonstrates minimax rate-optimality in its routing performance. Alongside CARROT, we also introduce the Smart Price-aware Routing (SPROUT) dataset to facilitate routing on a wide spectrum of queries with the latest state-of-the-art LLMs. Using SPROUT and prior benchmarks such as Routerbench and open-LLM-leaderboard-v2 we empirically validate CARROT's performance against several alternative routers.
Sloth: scaling laws for LLM skills to predict multi-benchmark performance across families
Dec 09, 2024Scaling laws for large language models (LLMs) predict model performance based on parameters like size and training data. However, differences in training configurations and data processing across model families lead to significant variations in benchmark performance, making it difficult for a single scaling law to generalize across all LLMs. On the other hand, training family-specific scaling laws requires training models of varying sizes for every family. In this work, we propose Skills Scaling Laws (SSLaws, pronounced as Sloth), a novel scaling law that leverages publicly available benchmark data and assumes LLM performance is driven by low-dimensional latent skills, such as reasoning and instruction following. These latent skills are influenced by computational resources like model size and training tokens but with varying efficiencies across model families. Sloth exploits correlations across benchmarks to provide more accurate and interpretable predictions while alleviating the need to train multiple LLMs per family. We present both theoretical results on parameter identification and empirical evaluations on 12 prominent benchmarks, from Open LLM Leaderboard v1/v2, demonstrating that Sloth predicts LLM performance efficiently and offers insights into scaling behaviors for downstream tasks such as coding and emotional intelligence applications.
Microfoundation Inference for Strategic Prediction
Nov 13, 2024



Often in prediction tasks, the predictive model itself can influence the distribution of the target variable, a phenomenon termed performative prediction. Generally, this influence stems from strategic actions taken by stakeholders with a vested interest in predictive models. A key challenge that hinders the widespread adaptation of performative prediction in machine learning is that practitioners are generally unaware of the social impacts of their predictions. To address this gap, we propose a methodology for learning the distribution map that encapsulates the long-term impacts of predictive models on the population. Specifically, we model agents' responses as a cost-adjusted utility maximization problem and propose estimates for said cost. Our approach leverages optimal transport to align pre-model exposure (ex ante) and post-model exposure (ex post) distributions. We provide a rate of convergence for this proposed estimate and assess its quality through empirical demonstrations on a credit-scoring dataset.
Algorithmic Fairness in Performative Policy Learning: Escaping the Impossibility of Group Fairness
May 30, 2024

In many prediction problems, the predictive model affects the distribution of the prediction target. This phenomenon is known as performativity and is often caused by the behavior of individuals with vested interests in the outcome of the predictive model. Although performativity is generally problematic because it manifests as distribution shifts, we develop algorithmic fairness practices that leverage performativity to achieve stronger group fairness guarantees in social classification problems (compared to what is achievable in non-performative settings). In particular, we leverage the policymaker's ability to steer the population to remedy inequities in the long term. A crucial benefit of this approach is that it is possible to resolve the incompatibilities between conflicting group fairness definitions.
A statistical framework for weak-to-strong generalization
May 25, 2024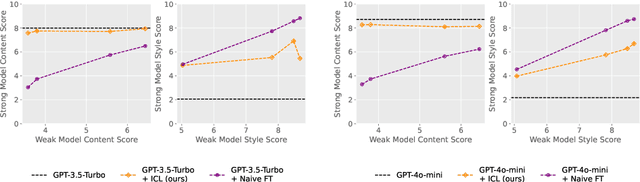
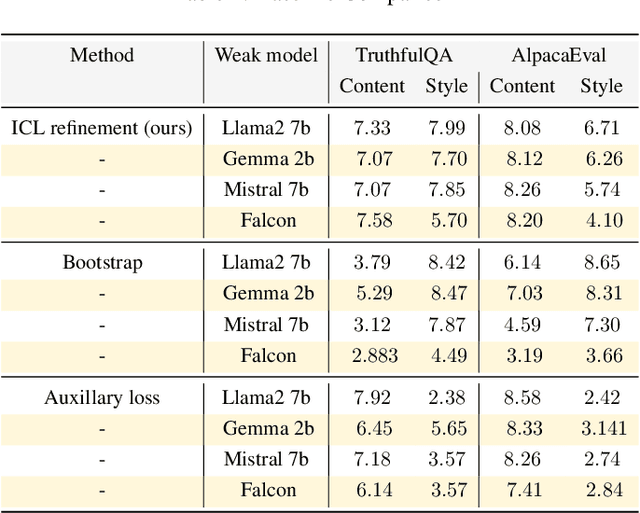
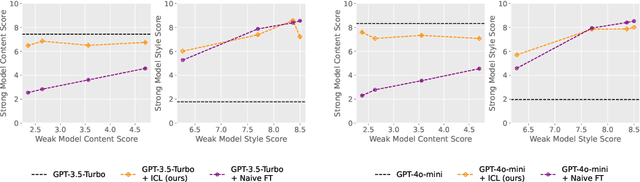
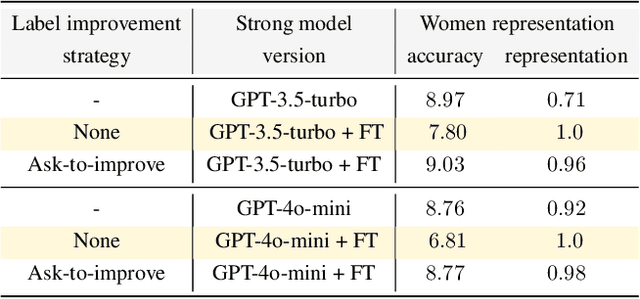
Modern large language model (LLM) alignment techniques rely on human feedback, but it is unclear whether the techniques fundamentally limit the capabilities of aligned LLMs. In particular, it is unclear whether it is possible to align (stronger) LLMs with superhuman capabilities with (weaker) human feedback without degrading their capabilities. This is an instance of the weak-to-strong generalization problem: using weaker (less capable) feedback to train a stronger (more capable) model. We prove that weak-to-strong generalization is possible by eliciting latent knowledge from pre-trained LLMs. In particular, we cast the weak-to-strong generalization problem as a transfer learning problem in which we wish to transfer a latent concept from a weak model to a strong pre-trained model. We prove that a naive fine-tuning approach suffers from fundamental limitations, but an alternative refinement-based approach suggested by the problem structure provably overcomes the limitations of fine-tuning. Finally, we demonstrate the practical applicability of the refinement approach with three LLM alignment tasks.
Learning In Reverse Causal Strategic Environments With Ramifications on Two Sided Markets
Apr 20, 2024Motivated by equilibrium models of labor markets, we develop a formulation of causal strategic classification in which strategic agents can directly manipulate their outcomes. As an application, we compare employers that anticipate the strategic response of a labor force with employers that do not. We show through a combination of theory and experiment that employers with performatively optimal hiring policies improve employer reward, labor force skill level, and in some cases labor force equity. On the other hand, we demonstrate that performative employers harm labor force utility and fail to prevent discrimination in other cases.