 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximin Relative Improvement: Fair Learning as a Bargaining Problem
Feb 04, 2026When deploying a single predictor across multiple subpopulations, we propose a fundamentally different approach: interpreting group fairness as a bargaining problem among subpopulations. This game-theoretic perspective reveals that existing robust optimization methods such as minimizing worst-group loss or regret correspond to classical bargaining solutions and embody different fairness principles. We propose relative improvement, the ratio of actual risk reduction to potential reduction from a baseline predictor, which recovers the Kalai-Smorodinsky solution. Unlike absolute-scale methods that may not be comparable when groups have different potential predictability, relative improvement provides axiomatic justification including scale invariance and individual monotonicity. We establish finite-sample convergence guarantees under mild conditions.
Limitations of refinement methods for weak to strong generalization
Aug 23, 2025



Standard techniques for aligning large language models (LLMs) utilize human-produced data, which could limit the capability of any aligned LLM to human level. Label refinement and weak training have emerged as promising strategies to address this superalignment problem. In this work, we adopt probabilistic assumptions commonly used to study label refinement and analyze whether refinement can be outperformed by alternative approaches, including computationally intractable oracle methods. We show that both weak training and label refinement suffer from irreducible error, leaving a performance gap between label refinement and the oracle. These results motivate future research into developing alternative methods for weak to strong generalization that synthesize the practicality of label refinement or weak training and the optimality of the oracle procedure.
Learning to Choose or Choosing to Learn: Best-of-N vs. Supervised Fine-Tuning for Bit String Generation
May 22, 2025Using the bit string generation problem as a case study, we theoretically compare two standard methods for adapting large language models to new tasks. The first, referred to as supervised fine-tuning, involves training a new next token predictor on good generations. The second method, Best-of-N, trains a reward model to select good responses from a collection generated by an unaltered base model. If the learning setting is realizable, we find that supervised fine-tuning outperforms BoN through a better dependence on the response length in its rate of convergence. If realizability fails, then depending on the failure mode, BoN can enjoy a better rate of convergence in either n or a rate of convergence with better dependence on the response length.
Optimal Nonlinear Online Learning under Sequential Price Competition via s-Concavity
Mar 20, 2025



We consider price competition among multiple sellers over a selling horizon of $T$ periods. In each period, sellers simultaneously offer their prices and subsequently observe their respective demand that is unobservable to competitors. The demand function for each seller depends on all sellers' prices through a private, unknown, and nonlinear relationship. To address this challenge, we propose a semi-parametric least-squares estimation of the nonlinear mean function, which does not require sellers to communicate demand information. We show that when all sellers employ our policy, their prices converge at a rate of $O(T^{-1/7})$ to the Nash equilibrium prices that sellers would reach if they were fully informed. Each seller incurs a regret of $O(T^{5/7})$ relative to a dynamic benchmark policy. A theoretical contribution of our work is proving the existence of equilibrium under shape-constrained demand functions via the concept of $s$-concavity and establishing regret bounds of our proposed policy. Technically, we also establish new concentration results for the least squares estimator under shape constraints. Our findings offer significant insights into dynamic competition-aware pricing and contribute to the broader study of non-parametric learning in strategic decision-making.
Likelihood-Free Estimation for Spatiotemporal Hawkes processes with missing data and application to predictive policing
Feb 10, 2025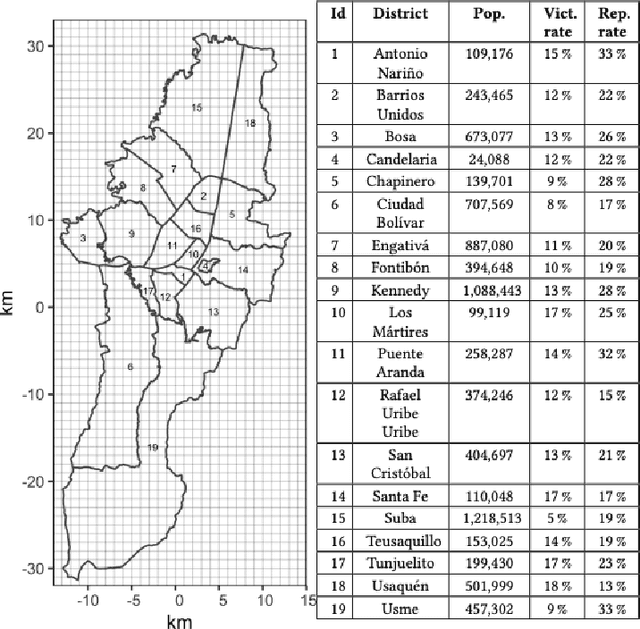



With the growing use of AI technology, many police departments use forecasting software to predict probable crime hotspots and allocate patrolling resources effectively for crime prevention. The clustered nature of crime data makes self-exciting Hawkes processes a popular modeling choice. However, one significant challenge in fitting such models is the inherent missingness in crime data due to non-reporting, which can bias the estimated parameters of the predictive model, leading to inaccurate downstream hotspot forecasts, often resulting in over or under-policing in various communities, especially the vulnerable ones. Our work introduces a Wasserstein Generative Adversarial Networks (WGAN) driven likelihood-free approach to account for unreported crimes in Spatiotemporal Hawkes models. We demonstrate through empirical analysis how this methodology improves the accuracy of parametric estimation in the presence of data missingness, leading to more reliable and efficient policing strategies.
Dynamic Pricing in the Linear Valuation Model using Shape Constraints
Feb 09, 2025


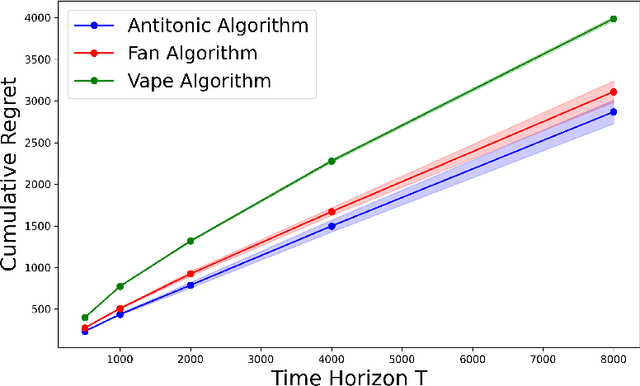
We propose a shape-constrained approach to dynamic pricing for censored data in the linear valuation model that eliminates the need for tuning parameters commonly required in existing methods. Previous works have addressed the challenge of unknown market noise distribution F using strategies ranging from kernel methods to reinforcement learning algorithms, such as bandit techniques and upper confidence bounds (UCB), under the Lipschitz (and stronger) assumption(s) on $F_0$. In contrast, our method relies on isotonic regression under the weaker assumption that $F_0$ is $\alpha$-Holder continuous for some $\alpha \in (0,1]$. We obtain an upper bound on the asymptotic expected regret that matches existing bounds in the literature for $\alpha = 1$ (the Lipschitz case). Simulations and experiments with real-world data obtained by Welltower Inc (a major healthcare Real Estate Investment Trust) consistently demonstrate that our method attains better empirical regret in comparison to several existing methods in the literature while offering the advantage of being completely tuning-parameter free.
Sloth: scaling laws for LLM skills to predict multi-benchmark performance across families
Dec 09, 2024Scaling laws for large language models (LLMs) predict model performance based on parameters like size and training data. However, differences in training configurations and data processing across model families lead to significant variations in benchmark performance, making it difficult for a single scaling law to generalize across all LLMs. On the other hand, training family-specific scaling laws requires training models of varying sizes for every family. In this work, we propose Skills Scaling Laws (SSLaws, pronounced as Sloth), a novel scaling law that leverages publicly available benchmark data and assumes LLM performance is driven by low-dimensional latent skills, such as reasoning and instruction following. These latent skills are influenced by computational resources like model size and training tokens but with varying efficiencies across model families. Sloth exploits correlations across benchmarks to provide more accurate and interpretable predictions while alleviating the need to train multiple LLMs per family. We present both theoretical results on parameter identification and empirical evaluations on 12 prominent benchmarks, from Open LLM Leaderboard v1/v2, demonstrating that Sloth predicts LLM performance efficiently and offers insights into scaling behaviors for downstream tasks such as coding and emotional intelligence applications.
Distributionally Robust Performative Prediction
Dec 05, 2024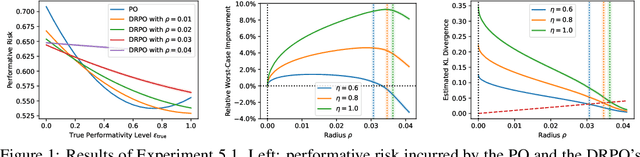
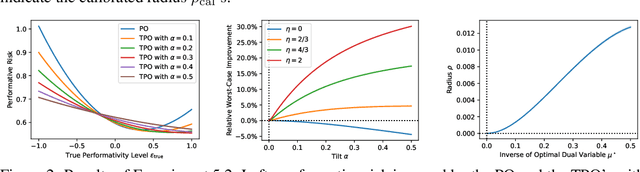
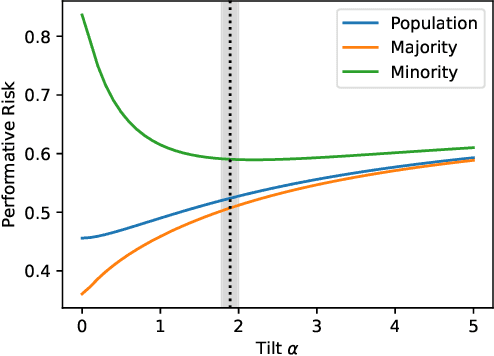
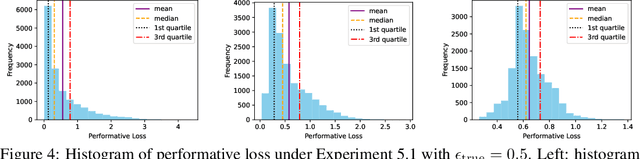
Performative prediction aims to model scenarios where predictive outcomes subsequently influence the very systems they target. The pursuit of a performative optimum (PO) -- minimizing performative risk -- is generally reliant on modeling of the distribution map, which characterizes how a deployed ML model alters the data distribution. Unfortunately, inevitable misspecification of the distribution map can lead to a poor approximation of the true PO. To address this issue, we introduce a novel framework of distributionally robust performative prediction and study a new solution concept termed as distributionally robust performative optimum (DRPO). We show provable guarantees for DRPO as a robust approximation to the true PO when the nominal distribution map is different from the actual one. Moreover, distributionally robust performative prediction can be reformulated as an augmented performative prediction problem, enabling efficient optimization. The experimental results demonstrate that DRPO offers potential advantages over traditional PO approach when the distribution map is misspecified at either micro- or macro-level.
Microfoundation Inference for Strategic Prediction
Nov 13, 2024



Often in prediction tasks, the predictive model itself can influence the distribution of the target variable, a phenomenon termed performative prediction. Generally, this influence stems from strategic actions taken by stakeholders with a vested interest in predictive models. A key challenge that hinders the widespread adaptation of performative prediction in machine learning is that practitioners are generally unaware of the social impacts of their predictions. To address this gap, we propose a methodology for learning the distribution map that encapsulates the long-term impacts of predictive models on the population. Specifically, we model agents' responses as a cost-adjusted utility maximization problem and propose estimates for said cost. Our approach leverages optimal transport to align pre-model exposure (ex ante) and post-model exposure (ex post) distributions. We provide a rate of convergence for this proposed estimate and assess its quality through empirical demonstrations on a credit-scoring dataset.
LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content
Oct 15, 2024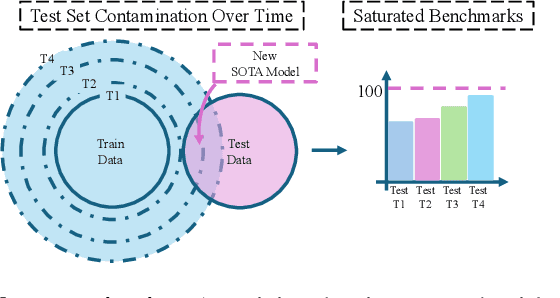



The large-scale training of multi-modal models on data scraped from the web has shown outstanding utility in infusing these models with the required world knowledge to perform effectively on multiple downstream tasks. However, one downside of scraping data from the web can be the potential sacrifice of the benchmarks on which the abilities of these models are often evaluated. To safeguard against test data contamination and to truly test the abilities of these foundation models we propose LiveXiv: A scalable evolving live benchmark based on scientific ArXiv papers. LiveXiv accesses domain-specific manuscripts at any given timestamp and proposes to automatically generate visual question-answer pairs (VQA). This is done without any human-in-the-loop, using the multi-modal content in the manuscripts, like graphs, charts, and tables. Moreover, we introduce an efficient evaluation approach that estimates the performance of all models on the evolving benchmark using evaluations of only a subset of models. This significantly reduces the overall evaluation cost. We benchmark multiple open and proprietary Large Multi-modal Models (LMMs) on the first version of our benchmark, showing its challenging nature and exposing the models true abilities, avoiding contamination. Lastly, in our commitment to high quality, we have collected and evaluated a manually verified subset. By comparing its overall results to our automatic annotations, we have found that the performance variance is indeed minimal (<2.5%). Our dataset is available online on HuggingFace, and our code will be available here.