 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA digital SRAM-based compute-in-memory macro for weight-stationary dynamic matrix multiplication in Transformer attention score computation
Nov 15, 2025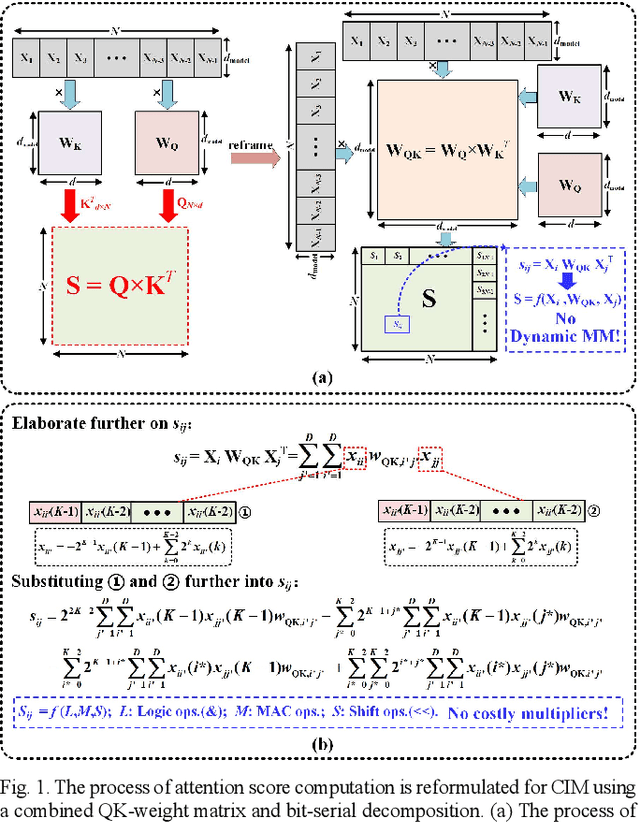
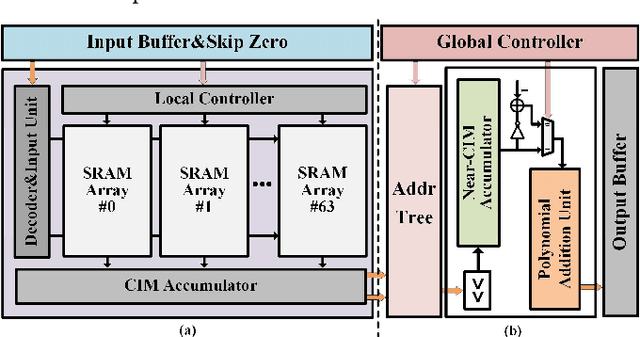


Compute-in-memory (CIM) techniques are widely employed in energy-efficient artificial intelligent (AI) processors. They alleviate power and latency bottlenecks caused by extensive data movements between compute and storage units. This work proposes a digital CIM macro to compute Transformer attention. To mitigate dynamic matrix multiplication that is unsuitable for the common weight-stationary CIM paradigm, we reformulate the attention score computation process based on a combined QK-weight matrix, so that inputs can be directly fed to CIM cells to obtain the score results. Moreover, the involved binomial matrix multiplication operation is decomposed into 4 groups of bit-serial shifting and additions, without costly physical multipliers in the CIM. We maximize the energy efficiency of the CIM circuit through zero-value bit-skipping, data-driven word line activation, read-write separate 6T cells and bit-alternating 14T/28T adders. The proposed CIM macro was implemented using a 65-nm process. It occupied only 0.35 mm2 area, and delivered a 42.27 GOPS peak performance with 1.24 mW power consumption at a 1.0 V power supply and a 100 MHz clock frequency, resulting in 34.1 TOPS/W energy efficiency and 120.77 GOPS/mm2 area efficiency. When compared to the CPU and GPU, our CIM macro is 25x and 13x more energy efficient on practical tasks, respectively. Compared with other Transformer-CIMs, our design exhibits at least 7x energy efficiency and at least 2x area efficiency improvements when scaled to the same technology node, showcasing its potential for edge-side intelligent applications.
PASTA: A Unified Framework for Offline Assortment Learning
Oct 02, 2025We study a broad class of assortment optimization problems in an offline and data-driven setting. In such problems, a firm lacks prior knowledge of the underlying choice model, and aims to determine an optimal assortment based on historical customer choice data. The combinatorial nature of assortment optimization often results in insufficient data coverage, posing a significant challenge in designing provably effective solutions. To address this, we introduce a novel Pessimistic Assortment Optimization (PASTA) framework that leverages the principle of pessimism to achieve optimal expected revenue under general choice models. Notably, PASTA requires only that the offline data distribution contains an optimal assortment, rather than providing the full coverage of all feasible assortments. Theoretically, we establish the first finite-sample regret bounds for offline assortment optimization across several widely used choice models, including the multinomial logit and nested logit models. Additionally, we derive a minimax regret lower bound, proving that PASTA is minimax optimal in terms of sample and model complexity. Numerical experiments further demonstrate that our method outperforms existing baseline approaches.
Optimal Nonlinear Online Learning under Sequential Price Competition via s-Concavity
Mar 20, 2025



We consider price competition among multiple sellers over a selling horizon of $T$ periods. In each period, sellers simultaneously offer their prices and subsequently observe their respective demand that is unobservable to competitors. The demand function for each seller depends on all sellers' prices through a private, unknown, and nonlinear relationship. To address this challenge, we propose a semi-parametric least-squares estimation of the nonlinear mean function, which does not require sellers to communicate demand information. We show that when all sellers employ our policy, their prices converge at a rate of $O(T^{-1/7})$ to the Nash equilibrium prices that sellers would reach if they were fully informed. Each seller incurs a regret of $O(T^{5/7})$ relative to a dynamic benchmark policy. A theoretical contribution of our work is proving the existence of equilibrium under shape-constrained demand functions via the concept of $s$-concavity and establishing regret bounds of our proposed policy. Technically, we also establish new concentration results for the least squares estimator under shape constraints. Our findings offer significant insights into dynamic competition-aware pricing and contribute to the broader study of non-parametric learning in strategic decision-making.
STOP: Spatiotemporal Orthogonal Propagation for Weight-Threshold-Leakage Synergistic Training of Deep Spiking Neural Networks
Nov 17, 2024



The prevailing of artificial intelligence-of-things calls for higher energy-efficient edge computing paradigms, such as neuromorphic agents leveraging brain-inspired spiking neural network (SNN) models based on spatiotemporally sparse binary activations. However, the lack of efficient and high-accuracy deep SNN learning algorithms prevents them from practical edge deployments with a strictly bounded cost. In this paper, we propose a spatiotemporal orthogonal propagation (STOP) algorithm to tack this challenge. Our algorithm enables fully synergistic learning of synaptic weights as well as firing thresholds and leakage factors in spiking neurons to improve SNN accuracy, while under a unified temporally-forward trace-based framework to mitigate the huge memory requirement for storing neural states of all time-steps in the forward pass. Characteristically, the spatially-backward neuronal errors and temporally-forward traces propagate orthogonally to and independently of each other, substantially reducing computational overhead. Our STOP algorithm obtained high recognition accuracies of 99.53%, 94.84%, 74.92%, 98.26% and 77.10% on the MNIST, CIFAR-10, CIFAR-100, DVS-Gesture and DVS-CIFAR10 datasets with adequate SNNs of intermediate scales from LeNet-5 to ResNet-18. Compared with other deep SNN training works, our method is more plausible for edge intelligent scenarios where resources are limited but high-accuracy in-situ learning is desired.
A Tale of Two Cities: Pessimism and Opportunism in Offline Dynamic Pricing
Nov 12, 2024This paper studies offline dynamic pricing without data coverage assumption, thereby allowing for any price including the optimal one not being observed in the offline data. Previous approaches that rely on the various coverage assumptions such as that the optimal prices are observable, would lead to suboptimal decisions and consequently, reduced profits. We address this challenge by framing the problem to a partial identification framework. Specifically, we establish a partial identification bound for the demand parameter whose associated price is unobserved by leveraging the inherent monotonicity property in the pricing problem. We further incorporate pessimistic and opportunistic strategies within the proposed partial identification framework to derive the estimated policy. Theoretically, we establish rate-optimal finite-sample regret guarantees for both strategies. Empirically, we demonstrate the superior performance of the newly proposed methods via a synthetic environment. This research provides practitioners with valuable insights into offline pricing strategies in the challenging no-coverage setting, ultimately fostering sustainable growth and profitability of the company.
Value Alignment and Trust in Human-Robot Interaction: Insights from Simulation and User Study
May 28, 2024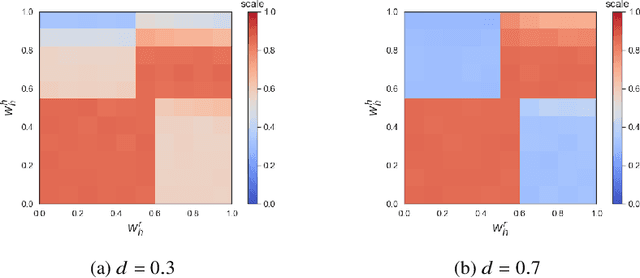
With the advent of AI technologies, humans and robots are increasingly teaming up to perform collaborative tasks. To enable smooth and effective collaboration, the topic of value alignment (operationalized herein as the degree of dynamic goal alignment within a task) between the robot and the human is gaining increasing research attention. Prior literature on value alignment makes an inherent assumption that aligning the values of the robot with that of the human benefits the team. This assumption, however, has not been empirically verified. Moreover, prior literature does not account for human's trust in the robot when analyzing human-robot value alignment. Thus, a research gap needs to be bridged by answering two questions: How does alignment of values affect trust? Is it always beneficial to align the robot's values with that of the human? We present a simulation study and a human-subject study to answer these questions. Results from the simulation study show that alignment of values is important for trust when the overall risk level of the task is high. We also present an adaptive strategy for the robot that uses Inverse Reinforcement Learning (IRL) to match the values of the robot with those of the human during interaction. Our simulations suggest that such an adaptive strategy is able to maintain trust across the full spectrum of human values. We also present results from an empirical study that validate these findings from simulation. Results indicate that real-time personalized value alignment is beneficial to trust and perceived performance by the human when the robot does not have a good prior on the human's values.
DisDet: Exploring Detectability of Backdoor Attack on Diffusion Models
Feb 05, 2024
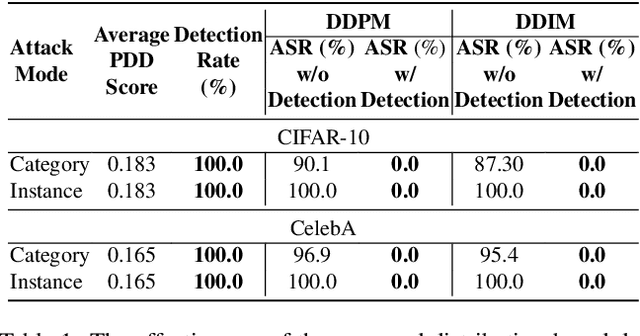

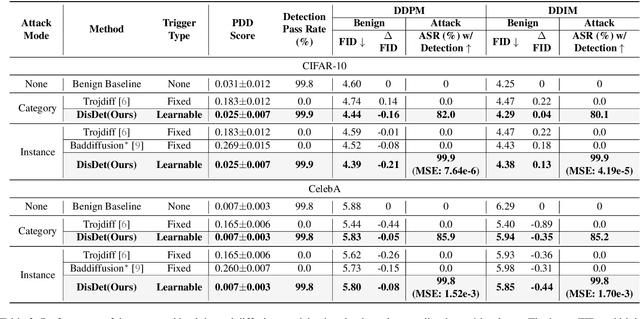
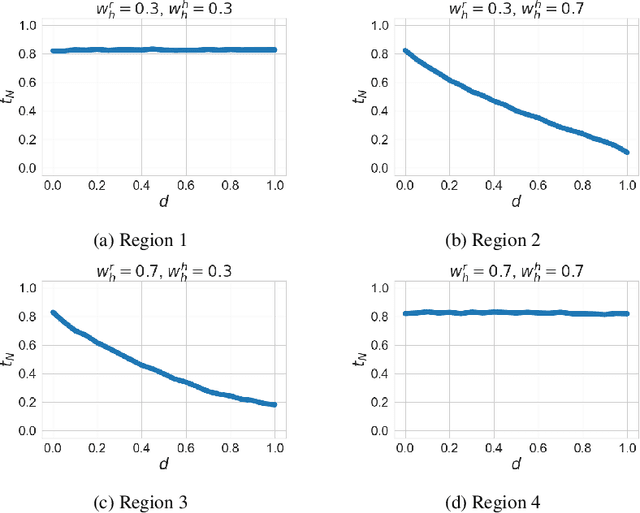
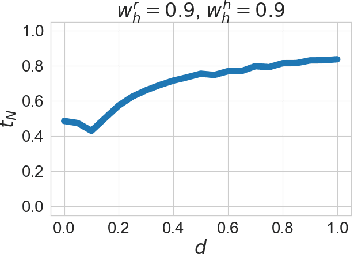
In the exciting generative AI era, the diffusion model has emerged as a very powerful and widely adopted content generation and editing tool for various data modalities, making the study of their potential security risks very necessary and critical. Very recently, some pioneering works have shown the vulnerability of the diffusion model against backdoor attacks, calling for in-depth analysis and investigation of the security challenges of this popular and fundamental AI technique. In this paper, for the first time, we systematically explore the detectability of the poisoned noise input for the backdoored diffusion models, an important performance metric yet little explored in the existing works. Starting from the perspective of a defender, we first analyze the properties of the trigger pattern in the existing diffusion backdoor attacks, discovering the important role of distribution discrepancy in Trojan detection. Based on this finding, we propose a low-cost trigger detection mechanism that can effectively identify the poisoned input noise. We then take a further step to study the same problem from the attack side, proposing a backdoor attack strategy that can learn the unnoticeable trigger to evade our proposed detection scheme. Empirical evaluations across various diffusion models and datasets demonstrate the effectiveness of the proposed trigger detection and detection-evading attack strategy. For trigger detection, our distribution discrepancy-based solution can achieve a 100\% detection rate for the Trojan triggers used in the existing works. For evading trigger detection, our proposed stealthy trigger design approach performs end-to-end learning to make the distribution of poisoned noise input approach that of benign noise, enabling nearly 100\% detection pass rate with very high attack and benign performance for the backdoored diffusion models.
Classification with neural networks with quadratic decision functions
Jan 19, 2024Neural network with quadratic decision functions have been introduced as alternatives to standard neural networks with affine linear one. They are advantageous when the objects to be identified are of compact basic geometries like circles, ellipsis etc. In this paper we investigate the use of such ansatz functions for classification. In particular we test and compare the algorithm on the MNIST dataset for classification of handwritten digits and for classification of subspecies. We also show, that the implementation can be based on the neural network structure in the software Tensorflow and Keras, respectively.
Evaluating the Impact of Personalized Value Alignment in Human-Robot Interaction: Insights into Trust and Team Performance Outcomes
Nov 27, 2023



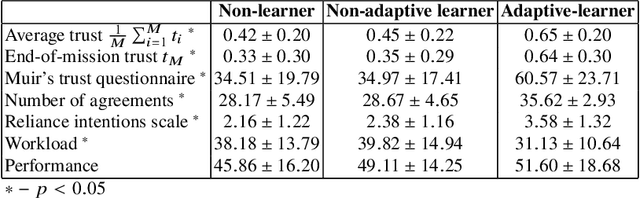
This paper examines the effect of real-time, personalized alignment of a robot's reward function to the human's values on trust and team performance. We present and compare three distinct robot interaction strategies: a non-learner strategy where the robot presumes the human's reward function mirrors its own, a non-adaptive-learner strategy in which the robot learns the human's reward function for trust estimation and human behavior modeling, but still optimizes its own reward function, and an adaptive-learner strategy in which the robot learns the human's reward function and adopts it as its own. Two human-subject experiments with a total number of 54 participants were conducted. In both experiments, the human-robot team searches for potential threats in a town. The team sequentially goes through search sites to look for threats. We model the interaction between the human and the robot as a trust-aware Markov Decision Process (trust-aware MDP) and use Bayesian Inverse Reinforcement Learning (IRL) to estimate the reward weights of the human as they interact with the robot. In Experiment 1, we start our learning algorithm with an informed prior of the human's values/goals. In Experiment 2, we start the learning algorithm with an uninformed prior. Results indicate that when starting with a good informed prior, personalized value alignment does not seem to benefit trust or team performance. On the other hand, when an informed prior is unavailable, alignment to the human's values leads to high trust and higher perceived performance while maintaining the same objective team performance.
Effect of Adapting to Human Preferences on Trust in Human-Robot Teaming
Sep 11, 2023



We present the effect of adapting to human preferences on trust in a human-robot teaming task. The team performs a task in which the robot acts as an action recommender to the human. It is assumed that the behavior of the human and the robot is based on some reward function they try to optimize. We use a new human trust-behavior model that enables the robot to learn and adapt to the human's preferences in real-time during their interaction using Bayesian Inverse Reinforcement Learning. We present three strategies for the robot to interact with a human: a non-learner strategy, in which the robot assumes that the human's reward function is the same as the robot's, a non-adaptive learner strategy that learns the human's reward function for performance estimation, but still optimizes its own reward function, and an adaptive-learner strategy that learns the human's reward function for performance estimation and also optimizes this learned reward function. Results show that adapting to the human's reward function results in the highest trust in the robot.