 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Context, Guided by Choice: A Reward-Free Paradigm for Reinforcement Learning with Transformers
Feb 09, 2026In-context reinforcement learning (ICRL) leverages the in-context learning capabilities of transformer models (TMs) to efficiently generalize to unseen sequential decision-making tasks without parameter updates. However, existing ICRL methods rely on explicit reward signals during pretraining, which limits their applicability when rewards are ambiguous, hard to specify, or costly to obtain. To overcome this limitation, we propose a new learning paradigm, In-Context Preference-based Reinforcement Learning (ICPRL), in which both pretraining and deployment rely solely on preference feedback, eliminating the need for reward supervision. We study two variants that differ in the granularity of feedback: Immediate Preference-based RL (I-PRL) with per-step preferences, and Trajectory Preference-based RL (T-PRL) with trajectory-level comparisons. We first show that supervised pretraining, a standard approach in ICRL, remains effective under preference-only context datasets, demonstrating the feasibility of in-context reinforcement learning using only preference signals. To further improve data efficiency, we introduce alternative preference-native frameworks for I-PRL and T-PRL that directly optimize TM policies from preference data without requiring reward signals nor optimal action labels.Experiments on dueling bandits, navigation, and continuous control tasks demonstrate that ICPRL enables strong in-context generalization to unseen tasks, achieving performance comparable to ICRL methods trained with full reward supervision.
In-Context Reinforcement Learning From Suboptimal Historical Data
Jan 27, 2026Transformer models have achieved remarkable empirical successes, largely due to their in-context learning capabilities. Inspired by this, we explore training an autoregressive transformer for in-context reinforcement learning (ICRL). In this setting, we initially train a transformer on an offline dataset consisting of trajectories collected from various RL tasks, and then fix and use this transformer to create an action policy for new RL tasks. Notably, we consider the setting where the offline dataset contains trajectories sampled from suboptimal behavioral policies. In this case, standard autoregressive training corresponds to imitation learning and results in suboptimal performance. To address this, we propose the Decision Importance Transformer(DIT) framework, which emulates the actor-critic algorithm in an in-context manner. In particular, we first train a transformer-based value function that estimates the advantage functions of the behavior policies that collected the suboptimal trajectories. Then we train a transformer-based policy via a weighted maximum likelihood estimation loss, where the weights are constructed based on the trained value function to steer the suboptimal policies to the optimal ones. We conduct extensive experiments to test the performance of DIT on both bandit and Markov Decision Process problems. Our results show that DIT achieves superior performance, particularly when the offline dataset contains suboptimal historical data.
PASTA: A Unified Framework for Offline Assortment Learning
Oct 02, 2025We study a broad class of assortment optimization problems in an offline and data-driven setting. In such problems, a firm lacks prior knowledge of the underlying choice model, and aims to determine an optimal assortment based on historical customer choice data. The combinatorial nature of assortment optimization often results in insufficient data coverage, posing a significant challenge in designing provably effective solutions. To address this, we introduce a novel Pessimistic Assortment Optimization (PASTA) framework that leverages the principle of pessimism to achieve optimal expected revenue under general choice models. Notably, PASTA requires only that the offline data distribution contains an optimal assortment, rather than providing the full coverage of all feasible assortments. Theoretically, we establish the first finite-sample regret bounds for offline assortment optimization across several widely used choice models, including the multinomial logit and nested logit models. Additionally, we derive a minimax regret lower bound, proving that PASTA is minimax optimal in terms of sample and model complexity. Numerical experiments further demonstrate that our method outperforms existing baseline approaches.
Contextual Online Uncertainty-Aware Preference Learning for Human Feedback
Apr 29, 2025Reinforcement Learning from Human Feedback (RLHF) has become a pivotal paradigm in artificial intelligence to align large models with human preferences. In this paper, we propose a novel statistical framework to simultaneously conduct the online decision-making and statistical inference on the optimal model using human preference data based on dynamic contextual information. Our approach introduces an efficient decision strategy that achieves both the optimal regret bound and the asymptotic distribution of the estimators. A key challenge in RLHF is handling the dependent online human preference outcomes with dynamic contexts. To address this, in the methodological aspect, we propose a two-stage algorithm starting with $\epsilon$-greedy followed by exploitations; in the theoretical aspect, we tailor anti-concentration inequalities and matrix martingale concentration techniques to derive the uniform estimation rate and asymptotic normality of the estimators using dependent samples from both stages. Extensive simulation results demonstrate that our method outperforms state-of-the-art strategies. We apply the proposed framework to analyze the human preference data for ranking large language models on the Massive Multitask Language Understanding dataset, yielding insightful results on the performance of different large language models for medical anatomy knowledge.
Ranking of Large Language Model with Nonparametric Prompts
Dec 07, 2024
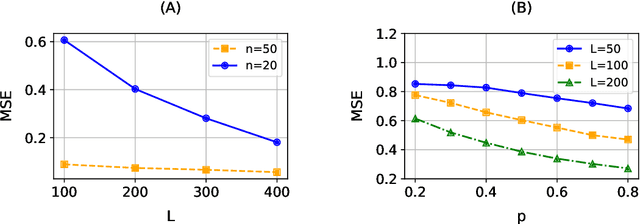
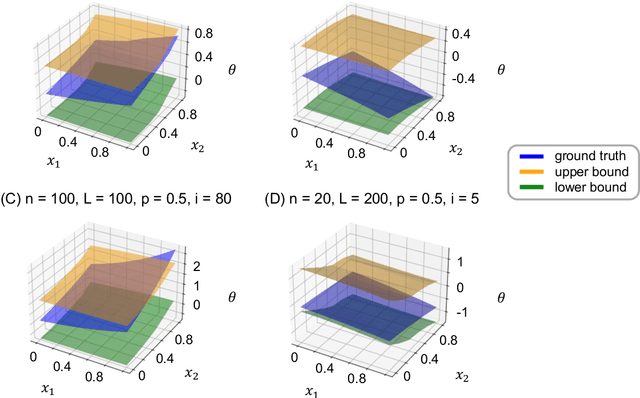
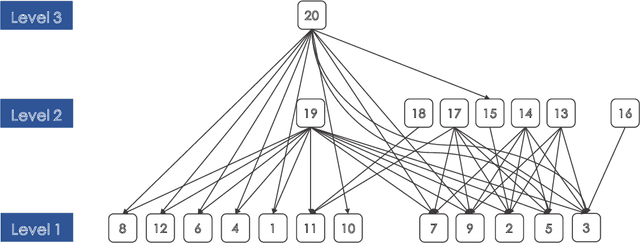
We consider the inference for the ranking of large language models (LLMs). Alignment arises as a big challenge to mitigate hallucinations in the use of LLMs. Ranking LLMs has been shown as a well-performing tool to improve alignment based on the best-of-$N$ policy. In this paper, we propose a new inferential framework for testing hypotheses and constructing confidence intervals of the ranking of language models. We consider the widely adopted Bradley-Terry-Luce (BTL) model, where each item is assigned a positive preference score that determines its pairwise comparisons' outcomes. We further extend it into the contextual setting, where the score of each model varies with the prompt. We show the convergence rate of our estimator. By extending the current Gaussian multiplier bootstrap theory to accommodate the supremum of not identically distributed empirical processes, we construct the confidence interval for ranking and propose a valid testing procedure. We also introduce the confidence diagram as a global ranking property. We conduct numerical experiments to assess the performance of our method.
Pivotal Estimation of Linear Discriminant Analysis in High Dimensions
Sep 18, 2023



We consider the linear discriminant analysis problem in the high-dimensional settings. In this work, we propose PANDA(PivotAl liNear Discriminant Analysis), a tuning-insensitive method in the sense that it requires very little effort to tune the parameters. Moreover, we prove that PANDA achieves the optimal convergence rate in terms of both the estimation error and misclassification rate. Our theoretical results are backed up by thorough numerical studies using both simulated and real datasets. In comparison with the existing methods, we observe that our proposed PANDA yields equal or better performance, and requires substantially less effort in parameter tuning.
PASTA: Pessimistic Assortment Optimization
Feb 08, 2023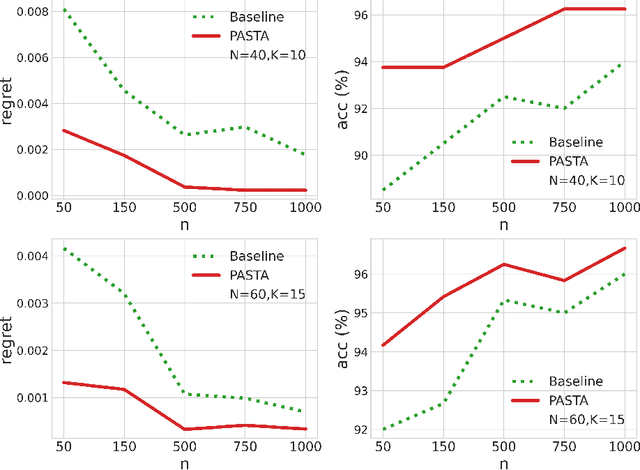
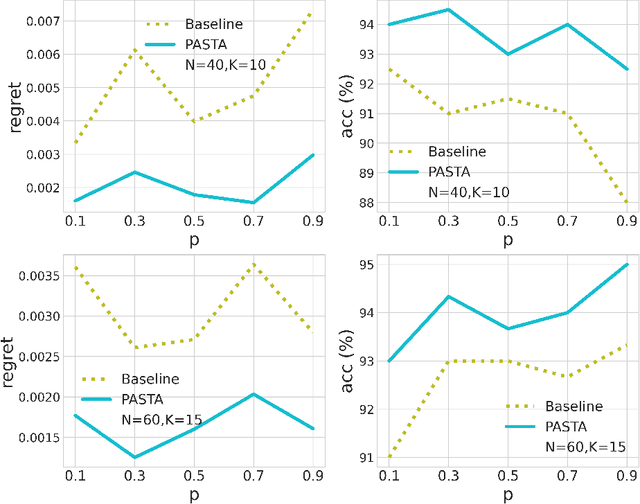
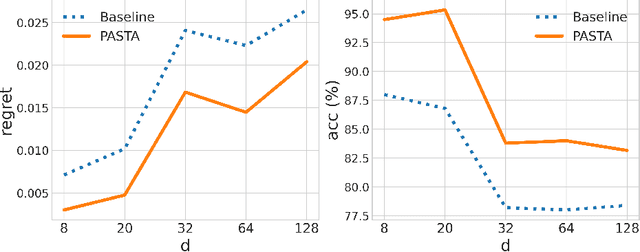
We consider a class of assortment optimization problems in an offline data-driven setting. A firm does not know the underlying customer choice model but has access to an offline dataset consisting of the historically offered assortment set, customer choice, and revenue. The objective is to use the offline dataset to find an optimal assortment. Due to the combinatorial nature of assortment optimization, the problem of insufficient data coverage is likely to occur in the offline dataset. Therefore, designing a provably efficient offline learning algorithm becomes a significant challenge. To this end, we propose an algorithm referred to as Pessimistic ASsortment opTimizAtion (PASTA for short) designed based on the principle of pessimism, that can correctly identify the optimal assortment by only requiring the offline data to cover the optimal assortment under general settings. In particular, we establish a regret bound for the offline assortment optimization problem under the celebrated multinomial logit model. We also propose an efficient computational procedure to solve our pessimistic assortment optimization problem. Numerical studies demonstrate the superiority of the proposed method over the existing baseline method.
Combinatorial Inference on the Optimal Assortment in Multinomial Logit Models
Feb 02, 2023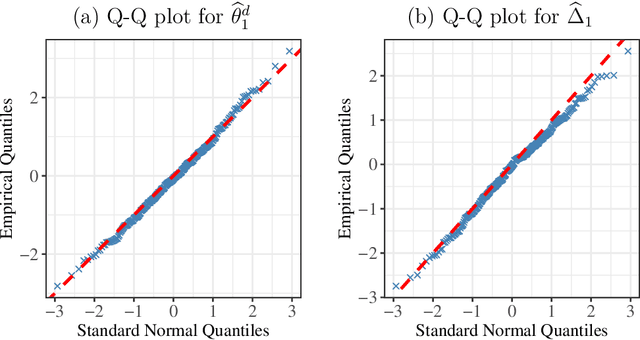
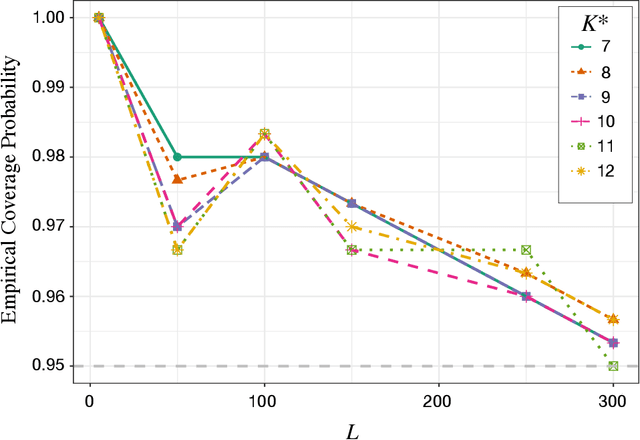
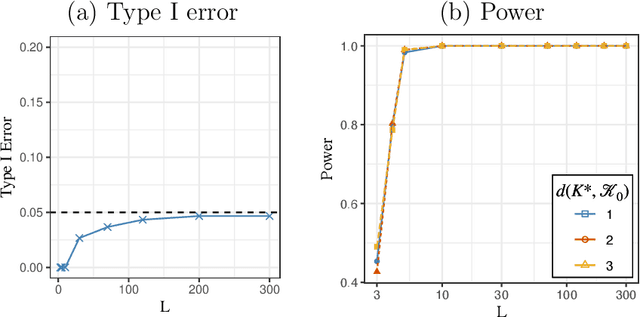
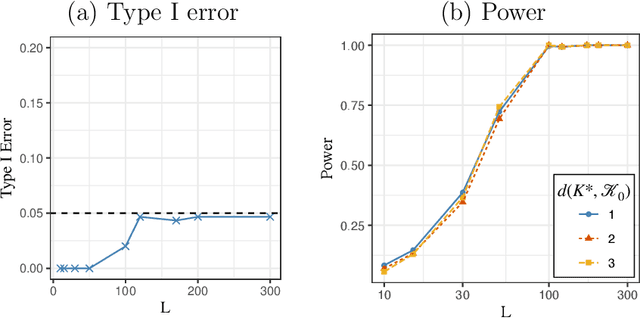
Assortment optimization has received active explorations in the past few decades due to its practical importance. Despite the extensive literature dealing with optimization algorithms and latent score estimation, uncertainty quantification for the optimal assortment still needs to be explored and is of great practical significance. Instead of estimating and recovering the complete optimal offer set, decision-makers may only be interested in testing whether a given property holds true for the optimal assortment, such as whether they should include several products of interest in the optimal set, or how many categories of products the optimal set should include. This paper proposes a novel inferential framework for testing such properties. We consider the widely adopted multinomial logit (MNL) model, where we assume that each customer will purchase an item within the offered products with a probability proportional to the underlying preference score associated with the product. We reduce inferring a general optimal assortment property to quantifying the uncertainty associated with the sign change point detection of the marginal revenue gaps. We show the asymptotic normality of the marginal revenue gap estimator, and construct a maximum statistic via the gap estimators to detect the sign change point. By approximating the distribution of the maximum statistic with multiplier bootstrap techniques, we propose a valid testing procedure. We also conduct numerical experiments to assess the performance of our method.
Stochastic Compositional Optimization with Compositional Constraints
Sep 09, 2022Stochastic compositional optimization (SCO) has attracted considerable attention because of its broad applicability to important real-world problems. However, existing works on SCO assume that the projection within a solution update is simple, which fails to hold for problem instances where the constraints are in the form of expectations, such as empirical conditional value-at-risk constraints. We study a novel model that incorporates single-level expected value and two-level compositional constraints into the current SCO framework. Our model can be applied widely to data-driven optimization and risk management, including risk-averse optimization and high-moment portfolio selection, and can handle multiple constraints. We further propose a class of primal-dual algorithms that generates sequences converging to the optimal solution at the rate of $\cO(\frac{1}{\sqrt{N}})$under both single-level expected value and two-level compositional constraints, where $N$ is the iteration counter, establishing the benchmarks in expected value constrained SCO.
Lagrangian Inference for Ranking Problems
Oct 01, 2021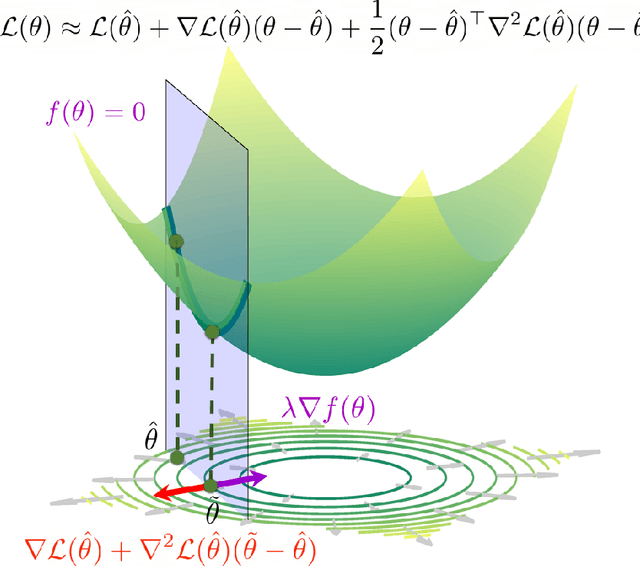
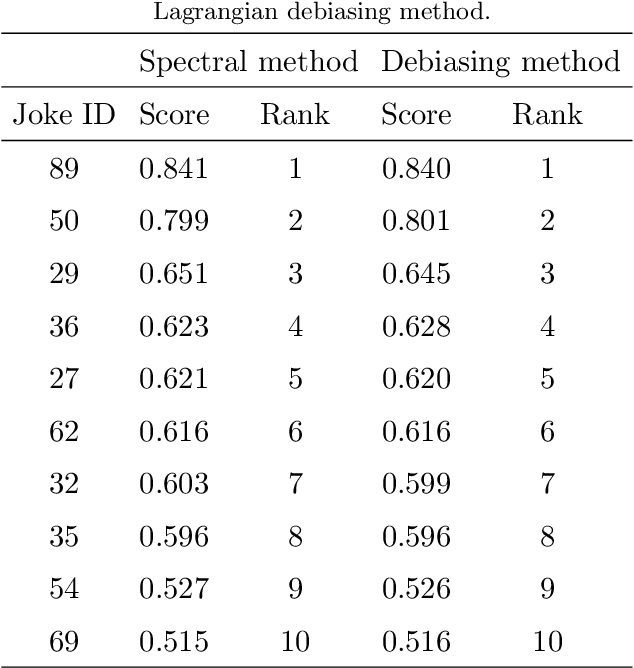

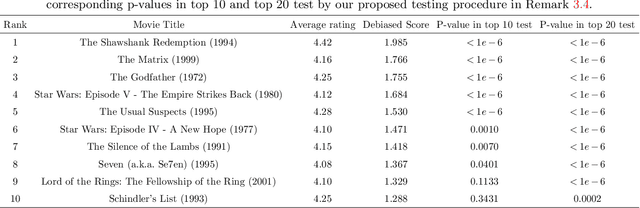
We propose a novel combinatorial inference framework to conduct general uncertainty quantification in ranking problems. We consider the widely adopted Bradley-Terry-Luce (BTL) model, where each item is assigned a positive preference score that determines the Bernoulli distributions of pairwise comparisons' outcomes. Our proposed method aims to infer general ranking properties of the BTL model. The general ranking properties include the "local" properties such as if an item is preferred over another and the "global" properties such as if an item is among the top $K$-ranked items. We further generalize our inferential framework to multiple testing problems where we control the false discovery rate (FDR), and apply the method to infer the top-$K$ ranked items. We also derive the information-theoretic lower bound to justify the minimax optimality of the proposed method. We conduct extensive numerical studies using both synthetic and real datasets to back up our theory.