 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASTA: A Unified Framework for Offline Assortment Learning
Oct 02, 2025We study a broad class of assortment optimization problems in an offline and data-driven setting. In such problems, a firm lacks prior knowledge of the underlying choice model, and aims to determine an optimal assortment based on historical customer choice data. The combinatorial nature of assortment optimization often results in insufficient data coverage, posing a significant challenge in designing provably effective solutions. To address this, we introduce a novel Pessimistic Assortment Optimization (PASTA) framework that leverages the principle of pessimism to achieve optimal expected revenue under general choice models. Notably, PASTA requires only that the offline data distribution contains an optimal assortment, rather than providing the full coverage of all feasible assortments. Theoretically, we establish the first finite-sample regret bounds for offline assortment optimization across several widely used choice models, including the multinomial logit and nested logit models. Additionally, we derive a minimax regret lower bound, proving that PASTA is minimax optimal in terms of sample and model complexity. Numerical experiments further demonstrate that our method outperforms existing baseline approaches.
Minimax Regret Learning for Data with Heterogeneous Subgroups
May 02, 2024Modern complex datasets often consist of various sub-populations. To develop robust and generalizable methods in the presence of sub-population heterogeneity, it is important to guarantee a uniform learning performance instead of an average one. In many applications, prior information is often available on which sub-population or group the data points belong to. Given the observed groups of data, we develop a min-max-regret (MMR) learning framework for general supervised learning, which targets to minimize the worst-group regret. Motivated from the regret-based decision theoretic framework, the proposed MMR is distinguished from the value-based or risk-based robust learning methods in the existing literature. The regret criterion features several robustness and invariance properties simultaneously. In terms of generalizability, we develop the theoretical guarantee for the worst-case regret over a super-population of the meta data, which incorporates the observed sub-populations, their mixtures, as well as other unseen sub-populations that could be approximated by the observed ones. We demonstrate the effectiveness of our method through extensive simulation studies and an application to kidney transplantation data from hundreds of transplant centers.
PASTA: Pessimistic Assortment Optimization
Feb 08, 2023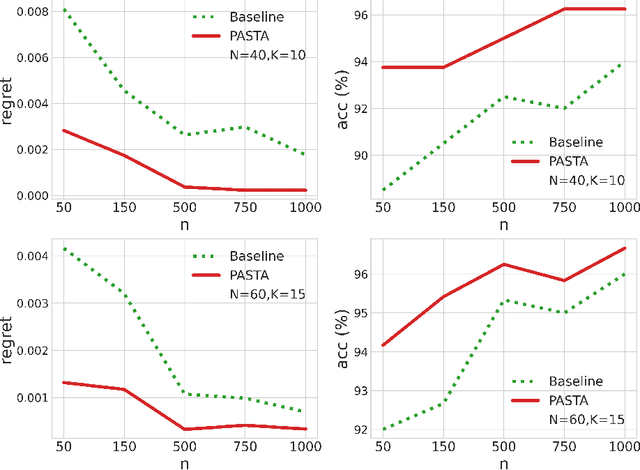
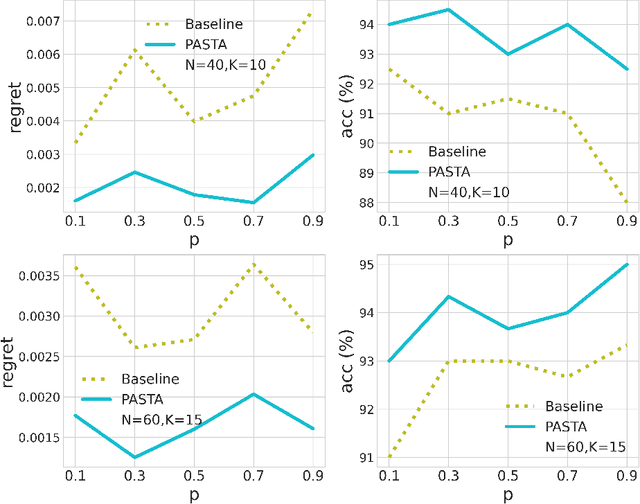
We consider a class of assortment optimization problems in an offline data-driven setting. A firm does not know the underlying customer choice model but has access to an offline dataset consisting of the historically offered assortment set, customer choice, and revenue. The objective is to use the offline dataset to find an optimal assortment. Due to the combinatorial nature of assortment optimization, the problem of insufficient data coverage is likely to occur in the offline dataset. Therefore, designing a provably efficient offline learning algorithm becomes a significant challenge. To this end, we propose an algorithm referred to as Pessimistic ASsortment opTimizAtion (PASTA for short) designed based on the principle of pessimism, that can correctly identify the optimal assortment by only requiring the offline data to cover the optimal assortment under general settings. In particular, we establish a regret bound for the offline assortment optimization problem under the celebrated multinomial logit model. We also propose an efficient computational procedure to solve our pessimistic assortment optimization problem. Numerical studies demonstrate the superiority of the proposed method over the existing baseline method.
Rejoinder: Learning Optimal Distributionally Robust Individualized Treatment Rules
Oct 17, 2021We thank the opportunity offered by editors for this discussion and the discussants for their insightful comments and thoughtful contributions. We also want to congratulate Kallus (2020) for his inspiring work in improving the efficiency of policy learning by retargeting. Motivated from the discussion in Dukes and Vansteelandt (2020), we first point out interesting connections and distinctions between our work and Kallus (2020) in Section 1. In particular, the assumptions and sources of variation for consideration in these two papers lead to different research problems with different scopes and focuses. In Section 2, following the discussions in Li et al. (2020); Liang and Zhao (2020), we also consider the efficient policy evaluation problem when we have some data from the testing distribution available at the training stage. We show that under the assumption that the sample sizes from training and testing are growing in the same order, efficient value function estimates can deliver competitive performance. We further show some connections of these estimates with existing literature. However, when the growth of testing sample size available for training is in a slower order, efficient value function estimates may not perform well anymore. In contrast, the requirement of the testing sample size for DRITR is not as strong as that of efficient policy evaluation using the combined data. Finally, we highlight the general applicability and usefulness of DRITR in Section 3.
Efficient Learning of Optimal Individualized Treatment Rules for Heteroscedastic or Misspecified Treatment-Free Effect Models
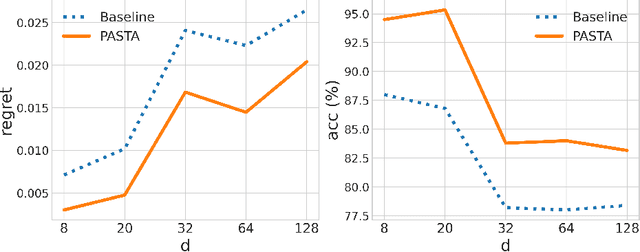
Sep 06, 2021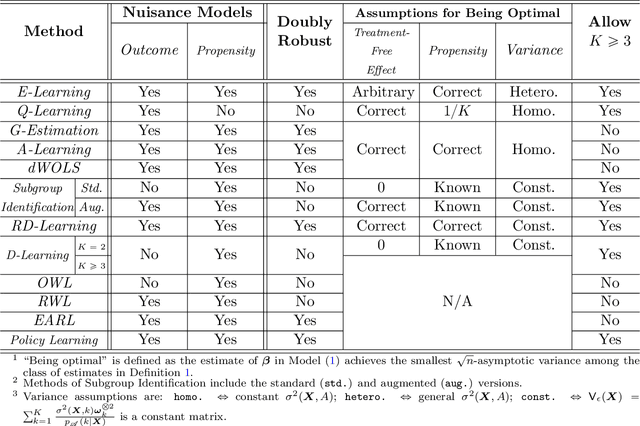
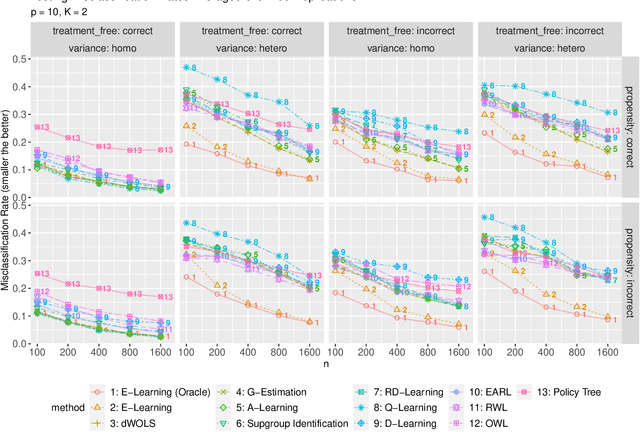

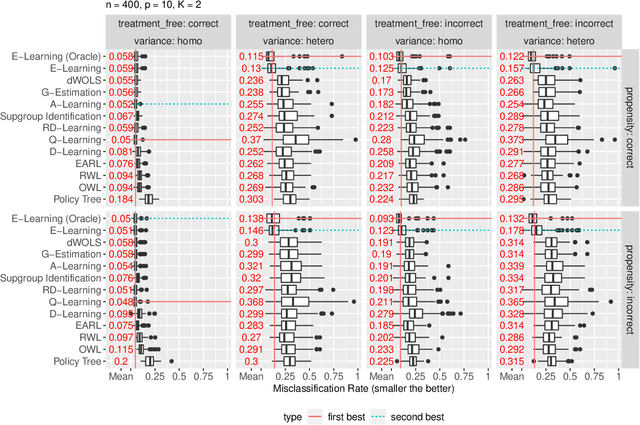
Recent development in data-driven decision science has seen great advances in individualized decision making. Given data with individual covariates, treatment assignments and outcomes, researchers can search for the optimal individualized treatment rule (ITR) that maximizes the expected outcome. Existing methods typically require initial estimation of some nuisance models. The double robustness property that can protect from misspecification of either the treatment-free effect or the propensity score has been widely advocated. However, when model misspecification exists, a doubly robust estimate can be consistent but may suffer from downgraded efficiency. Other than potential misspecified nuisance models, most existing methods do not account for the potential problem when the variance of outcome is heterogeneous among covariates and treatment. We observe that such heteroscedasticity can greatly affect the estimation efficiency of the optimal ITR. In this paper, we demonstrate that the consequences of misspecified treatment-free effect and heteroscedasticity can be unified as a covariate-treatment dependent variance of residuals. To improve efficiency of the estimated ITR, we propose an Efficient Learning (E-Learning) framework for finding an optimal ITR in the multi-armed treatment setting. We show that the proposed E-Learning is optimal among a regular class of semiparametric estimates that can allow treatment-free effect misspecification. In our simulation study, E-Learning demonstrates its effectiveness if one of or both misspecified treatment-free effect and heteroscedasticity exist. Our analysis of a Type 2 Diabetes Mellitus (T2DM) observational study also suggests the improved efficiency of E-Learning.
Learning Optimal Distributionally Robust Individualized Treatment Rules
Jun 26, 2020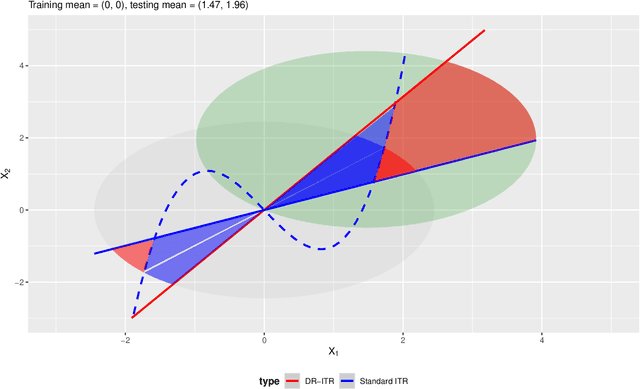
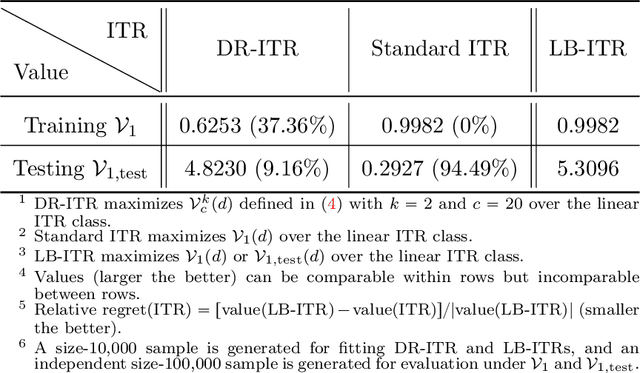
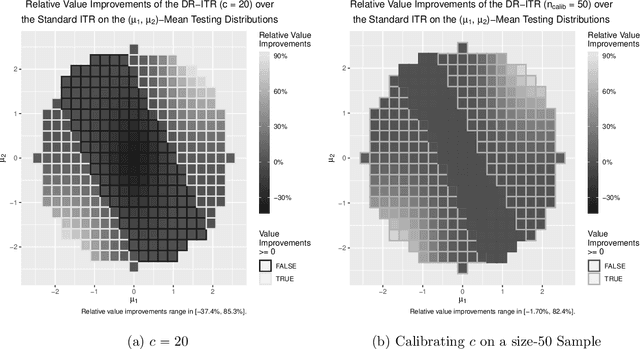
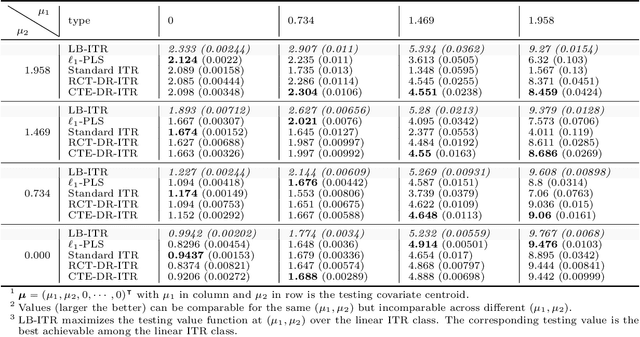
Recent development in the data-driven decision science has seen great advances in individualized decision making. Given data with individual covariates, treatment assignments and outcomes, policy makers best individualized treatment rule (ITR) that maximizes the expected outcome, known as the value function. Many existing methods assume that the training and testing distributions are the same. However, the estimated optimal ITR may have poor generalizability when the training and testing distributions are not identical. In this paper, we consider the problem of finding an optimal ITR from a restricted ITR class where there is some unknown covariate changes between the training and testing distributions. We propose a novel distributionally robust ITR (DR-ITR) framework that maximizes the worst-case value function across the values under a set of underlying distributions that are "close" to the training distribution. The resulting DR-ITR can guarantee the performance among all such distributions reasonably well. We further propose a calibrating procedure that tunes the DR-ITR adaptively to a small amount of calibration data from a target population. In this way, the calibrated DR-ITR can be shown to enjoy better generalizability than the standard ITR based on our numerical studies.