 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking of Large Language Model with Nonparametric Prompts
Dec 07, 2024
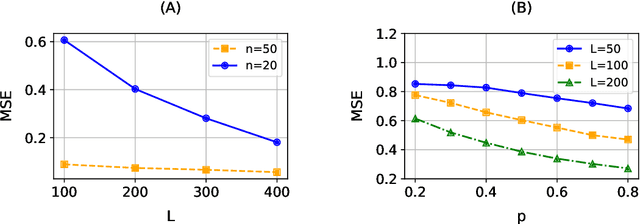
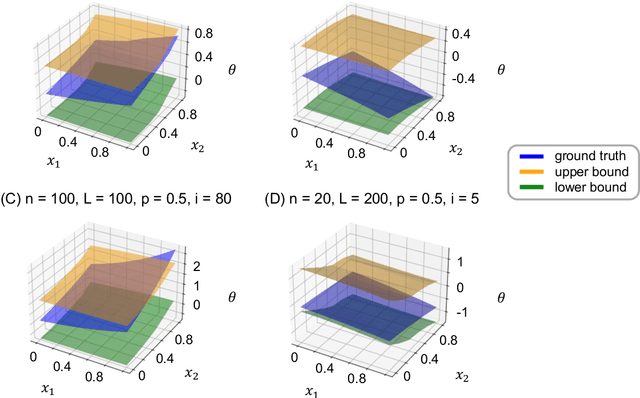
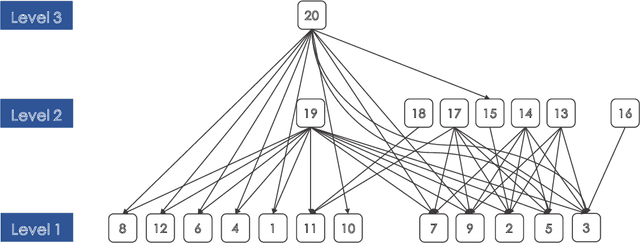
We consider the inference for the ranking of large language models (LLMs). Alignment arises as a big challenge to mitigate hallucinations in the use of LLMs. Ranking LLMs has been shown as a well-performing tool to improve alignment based on the best-of-$N$ policy. In this paper, we propose a new inferential framework for testing hypotheses and constructing confidence intervals of the ranking of language models. We consider the widely adopted Bradley-Terry-Luce (BTL) model, where each item is assigned a positive preference score that determines its pairwise comparisons' outcomes. We further extend it into the contextual setting, where the score of each model varies with the prompt. We show the convergence rate of our estimator. By extending the current Gaussian multiplier bootstrap theory to accommodate the supremum of not identically distributed empirical processes, we construct the confidence interval for ranking and propose a valid testing procedure. We also introduce the confidence diagram as a global ranking property. We conduct numerical experiments to assess the performance of our method.