 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVIS: An Evidence-Grounded Retrieval System for Interpretable Deceptive Reviews Adjudication
Feb 13, 2026Deceptive reviews, refer to fabricated feedback designed to artificially manipulate the perceived quality of products. Within modern e-commerce ecosystems, these reviews remain a critical governance challenge. Despite advances in review-level and graph-based detection methods, two pivotal limitations remain: inadequate generalization and lack of interpretability. To address these challenges, we propose JARVIS, a framework providing Judgment via Augmented Retrieval and eVIdence graph Structures. Starting from the review to be evaluated, it retrieves semantically similar evidence via hybrid dense-sparse multimodal retrieval, expands relational signals through shared entities, and constructs a heterogeneous evidence graph. Large language model then performs evidence-grounded adjudication to produce interpretable risk assessments. Offline experiments demonstrate that JARVIS enhances performance on our constructed review dataset, achieving a precision increase from 0.953 to 0.988 and a recall boost from 0.830 to 0.901. In the production environment, our framework achieves a 27% increase in the recall volume and reduces manual inspection time by 75%. Furthermore, the adoption rate of the model-generated analysis reaches 96.4%.
Contextual Online Uncertainty-Aware Preference Learning for Human Feedback
Apr 29, 2025Reinforcement Learning from Human Feedback (RLHF) has become a pivotal paradigm in artificial intelligence to align large models with human preferences. In this paper, we propose a novel statistical framework to simultaneously conduct the online decision-making and statistical inference on the optimal model using human preference data based on dynamic contextual information. Our approach introduces an efficient decision strategy that achieves both the optimal regret bound and the asymptotic distribution of the estimators. A key challenge in RLHF is handling the dependent online human preference outcomes with dynamic contexts. To address this, in the methodological aspect, we propose a two-stage algorithm starting with $\epsilon$-greedy followed by exploitations; in the theoretical aspect, we tailor anti-concentration inequalities and matrix martingale concentration techniques to derive the uniform estimation rate and asymptotic normality of the estimators using dependent samples from both stages. Extensive simulation results demonstrate that our method outperforms state-of-the-art strategies. We apply the proposed framework to analyze the human preference data for ranking large language models on the Massive Multitask Language Understanding dataset, yielding insightful results on the performance of different large language models for medical anatomy knowledge.
Learning from Ambiguous Data with Hard Labels
Jan 08, 2025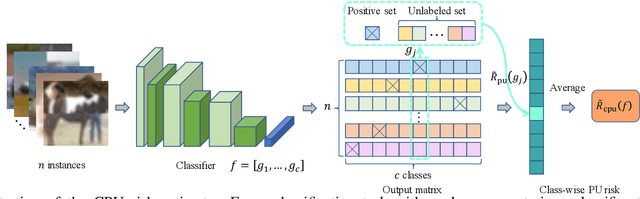

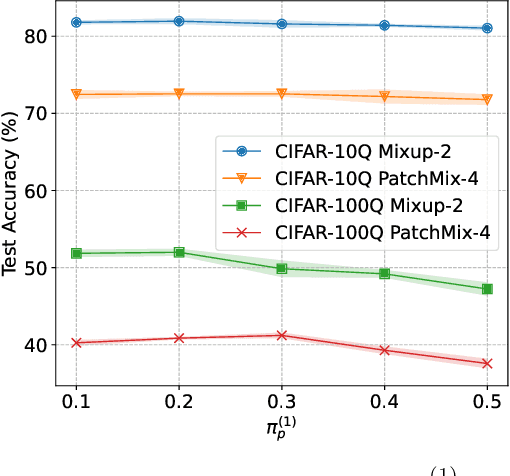
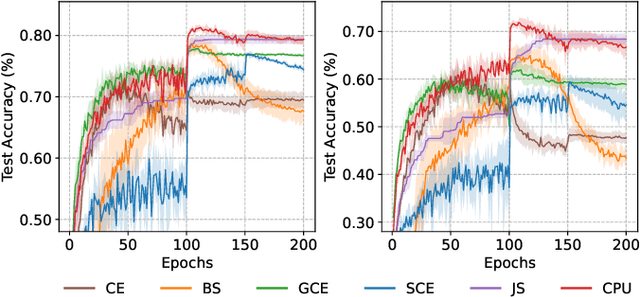
Real-world data often contains intrinsic ambiguity that the common single-hard-label annotation paradigm ignores. Standard training using ambiguous data with these hard labels may produce overly confident models and thus leading to poor generalization. In this paper, we propose a novel framework called Quantized Label Learning (QLL) to alleviate this issue. First, we formulate QLL as learning from (very) ambiguous data with hard labels: ideally, each ambiguous instance should be associated with a ground-truth soft-label distribution describing its corresponding probabilistic weight in each class, however, this is usually not accessible; in practice, we can only observe a quantized label, i.e., a hard label sampled (quantized) from the corresponding ground-truth soft-label distribution, of each instance, which can be seen as a biased approximation of the ground-truth soft-label. Second, we propose a Class-wise Positive-Unlabeled (CPU) risk estimator that allows us to train accurate classifiers from only ambiguous data with quantized labels. Third, to simulate ambiguous datasets with quantized labels in the real world, we design a mixing-based ambiguous data generation procedure for empirical evaluation. Experiments demonstrate that our CPU method can significantly improve model generalization performance and outperform the baselines.
A General Framework for Learning under Corruption: Label Noise, Attribute Noise, and Beyond
Jul 17, 2023Corruption is frequently observed in collected data and has been extensively studied in machine learning under different corruption models. Despite this, there remains a limited understanding of how these models relate such that a unified view of corruptions and their consequences on learning is still lacking. In this work, we formally analyze corruption models at the distribution level through a general, exhaustive framework based on Markov kernels. We highlight the existence of intricate joint and dependent corruptions on both labels and attributes, which are rarely touched by existing research. Further, we show how these corruptions affect standard supervised learning by analyzing the resulting changes in Bayes Risk. Our findings offer qualitative insights into the consequences of "more complex" corruptions on the learning problem, and provide a foundation for future quantitative comparisons. Applications of the framework include corruption-corrected learning, a subcase of which we study in this paper by theoretically analyzing loss correction with respect to different corruption instances.
Generalizing Importance Weighting to A Universal Solver for Distribution Shift Problems
May 24, 2023Distribution shift (DS) may have two levels: the distribution itself changes, and the support (i.e., the set where the probability density is non-zero) also changes. When considering the support change between the training and test distributions, there can be four cases: (i) they exactly match; (ii) the training support is wider (and thus covers the test support); (iii) the test support is wider; (iv) they partially overlap. Existing methods are good at cases (i) and (ii), while cases (iii) and (iv) are more common nowadays but still under-explored. In this paper, we generalize importance weighting (IW), a golden solver for cases (i) and (ii), to a universal solver for all cases. Specifically, we first investigate why IW may fail in cases (iii) and (iv); based on the findings, we propose generalized IW (GIW) that could handle cases (iii) and (iv) and would reduce to IW in cases (i) and (ii). In GIW, the test support is split into an in-training (IT) part and an out-of-training (OOT) part, and the expected risk is decomposed into a weighted classification term over the IT part and a standard classification term over the OOT part, which guarantees the risk consistency of GIW. Then, the implementation of GIW consists of three components: (a) the split of validation data is carried out by the one-class support vector machine, (b) the first term of the empirical risk can be handled by any IW algorithm given training data and IT validation data, and (c) the second term just involves OOT validation data. Experiments demonstrate that GIW is a universal solver for DS problems, outperforming IW methods in cases (iii) and (iv).
Learning from Multiple Unlabeled Datasets with Partial Risk Regularization
Jul 04, 2022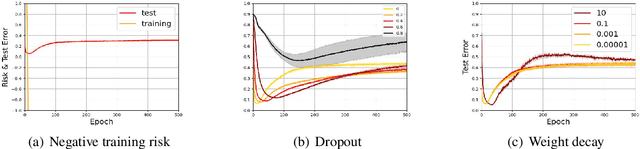
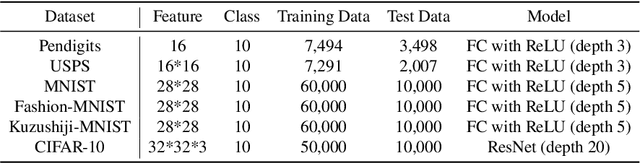
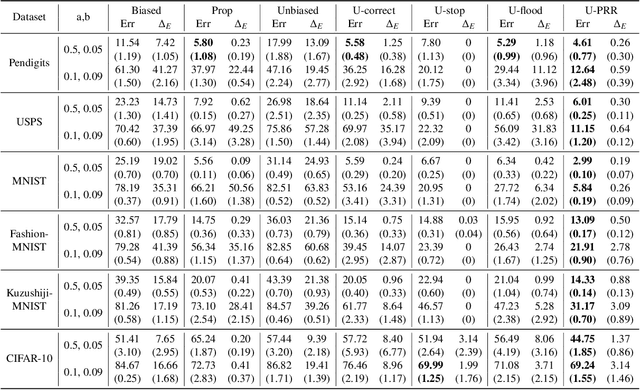
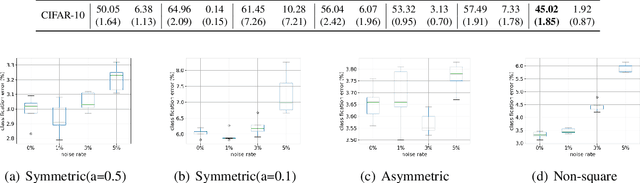
Recent years have witnessed a great success of supervised deep learning, where predictive models were trained from a large amount of fully labeled data. However, in practice, labeling such big data can be very costly and may not even be possible for privacy reasons. Therefore, in this paper, we aim to learn an accurate classifier without any class labels. More specifically, we consider the case where multiple sets of unlabeled data and only their class priors, i.e., the proportions of each class, are available. Under this problem setup, we first derive an unbiased estimator of the classification risk that can be estimated from the given unlabeled sets and theoretically analyze the generalization error of the learned classifier. We then find that the classifier obtained as such tends to cause overfitting as its empirical risks go negative during training. To prevent overfitting, we further propose a partial risk regularization that maintains the partial risks with respect to unlabeled datasets and classes to certain levels. Experiments demonstrate that our method effectively mitigates overfitting and outperforms state-of-the-art methods for learning from multiple unlabeled sets.
Federated Learning from Only Unlabeled Data with Class-Conditional-Sharing Clients
Apr 07, 2022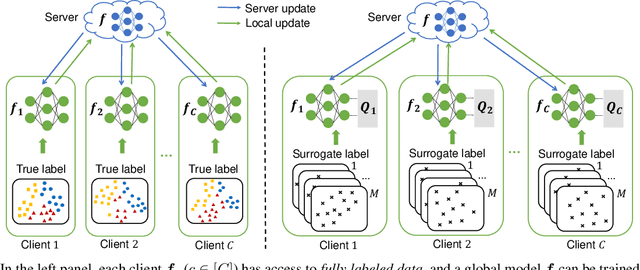
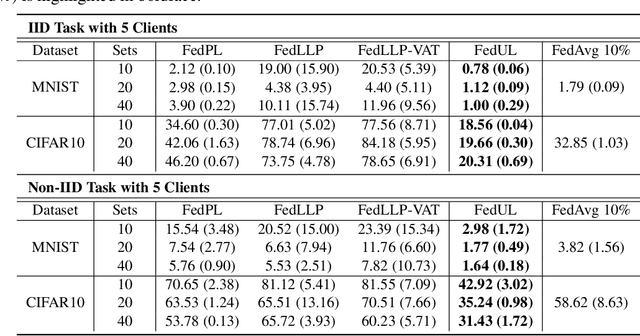
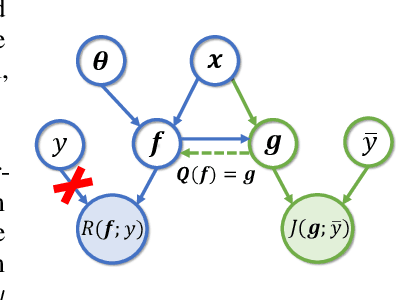
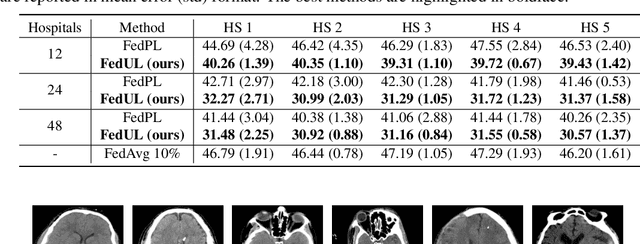
Supervised federated learning (FL) enables multiple clients to share the trained model without sharing their labeled data. However, potential clients might even be reluctant to label their own data, which could limit the applicability of FL in practice. In this paper, we show the possibility of unsupervised FL whose model is still a classifier for predicting class labels, if the class-prior probabilities are shifted while the class-conditional distributions are shared among the unlabeled data owned by the clients. We propose federation of unsupervised learning (FedUL), where the unlabeled data are transformed into surrogate labeled data for each of the clients, a modified model is trained by supervised FL, and the wanted model is recovered from the modified model. FedUL is a very general solution to unsupervised FL: it is compatible with many supervised FL methods, and the recovery of the wanted model can be theoretically guaranteed as if the data have been labeled. Experiments on benchmark and real-world datasets demonstrate the effectiveness of FedUL. Code is available at https://github.com/lunanbit/FedUL.
Rethinking Importance Weighting for Transfer Learning
Dec 19, 2021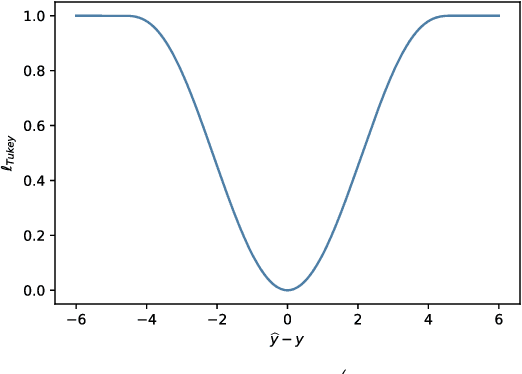
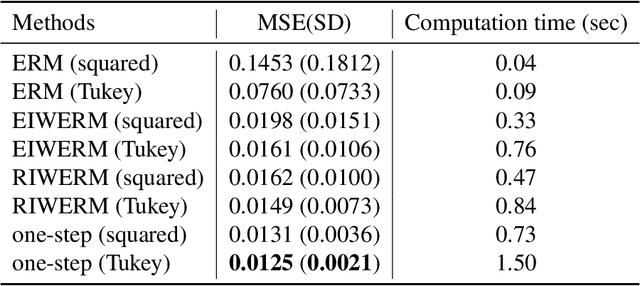

A key assumption in supervised learning is that training and test data follow the same probability distribution. However, this fundamental assumption is not always satisfied in practice, e.g., due to changing environments, sample selection bias, privacy concerns, or high labeling costs. Transfer learning (TL) relaxes this assumption and allows us to learn under distribution shift. Classical TL methods typically rely on importance-weighting -- a predictor is trained based on the training losses weighted according to the importance (i.e., the test-over-training density ratio). However, as real-world machine learning tasks are becoming increasingly complex, high-dimensional, and dynamical, novel approaches are explored to cope with such challenges recently. In this article, after introducing the foundation of TL based on importance-weighting, we review recent advances based on joint and dynamic importance-predictor estimation. Furthermore, we introduce a method of causal mechanism transfer that incorporates causal structure in TL. Finally, we discuss future perspectives of TL research.
Binary Classification from Multiple Unlabeled Datasets via Surrogate Set Classification
Feb 01, 2021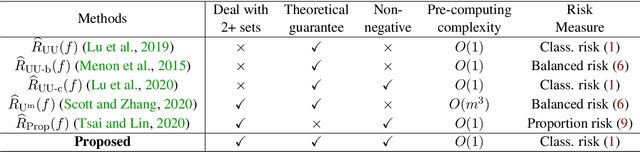
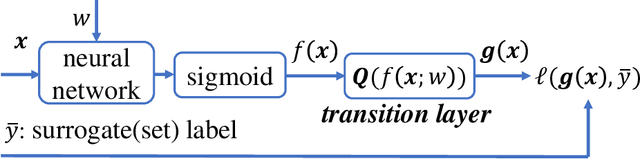

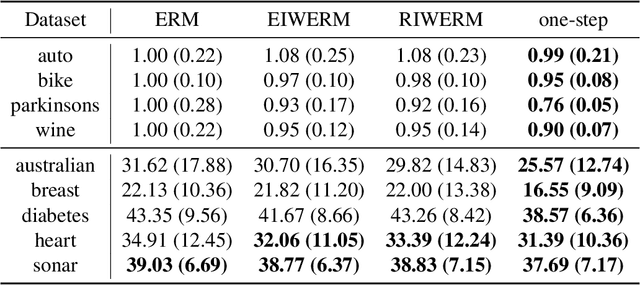
To cope with high annotation costs, training a classifier only from weakly supervised data has attracted a great deal of attention these days. Among various approaches, strengthening supervision from completely unsupervised classification is a promising direction, which typically employs class priors as the only supervision and trains a binary classifier from unlabeled (U) datasets. While existing risk-consistent methods are theoretically grounded with high flexibility, they can learn only from two U sets. In this paper, we propose a new approach for binary classification from m U-sets for $m\ge2$. Our key idea is to consider an auxiliary classification task called surrogate set classification (SSC), which is aimed at predicting from which U set each observed data is drawn. SSC can be solved by a standard (multi-class) classification method, and we use the SSC solution to obtain the final binary classifier through a certain linear-fractional transformation. We built our method in a flexible and efficient end-to-end deep learning framework and prove it to be classifier-consistent. Through experiments, we demonstrate the superiority of our proposed method over state-of-the-art methods.
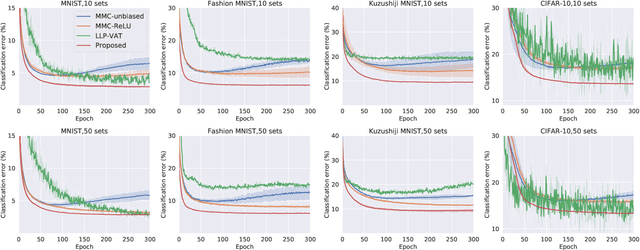
Pointwise Binary Classification with Pairwise Confidence Comparisons
Oct 05, 2020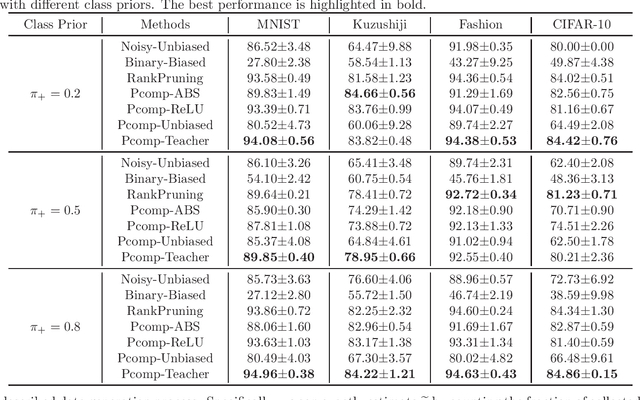
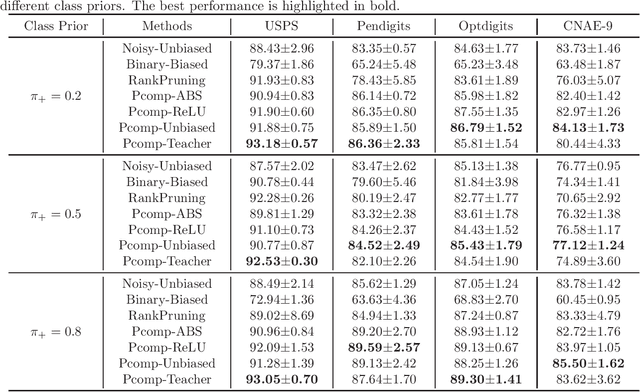

Ordinary (pointwise) binary classification aims to learn a binary classifier from pointwise labeled data. However, such pointwise labels may not be directly accessible due to privacy, confidentiality, or security considerations. In this case, can we still learn an accurate binary classifier? This paper proposes a novel setting, namely pairwise comparison (Pcomp) classification, where we are given only pairs of unlabeled data that we know one is more likely to be positive than the other, instead of pointwise labeled data. Pcomp classification is useful for private or subjective classification tasks. To solve this problem, we present a mathematical formulation for the generation process of pairwise comparison data, based on which we exploit an unbiased risk estimator(URE) to train a binary classifier by empirical risk minimization and establish an estimation error bound. We first prove that a URE can be derived and improve it using correction functions. Then, we start from the noisy-label learning perspective to introduce a progressive URE and improve it by imposing consistency regularization. Finally, experiments validate the effectiveness of our proposed solutions for Pcomp classification.