 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Learning under Corruption: Label Noise, Attribute Noise, and Beyond
Jul 17, 2023Corruption is frequently observed in collected data and has been extensively studied in machine learning under different corruption models. Despite this, there remains a limited understanding of how these models relate such that a unified view of corruptions and their consequences on learning is still lacking. In this work, we formally analyze corruption models at the distribution level through a general, exhaustive framework based on Markov kernels. We highlight the existence of intricate joint and dependent corruptions on both labels and attributes, which are rarely touched by existing research. Further, we show how these corruptions affect standard supervised learning by analyzing the resulting changes in Bayes Risk. Our findings offer qualitative insights into the consequences of "more complex" corruptions on the learning problem, and provide a foundation for future quantitative comparisons. Applications of the framework include corruption-corrected learning, a subcase of which we study in this paper by theoretically analyzing loss correction with respect to different corruption instances.
The interplay between ranking and communities in networks
Dec 23, 2021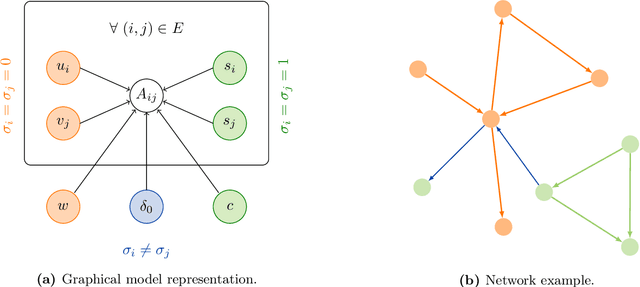
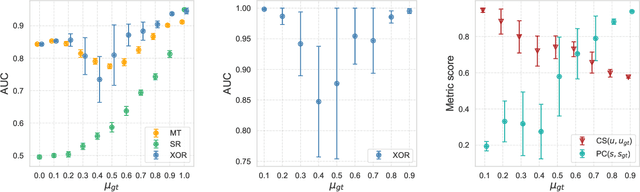
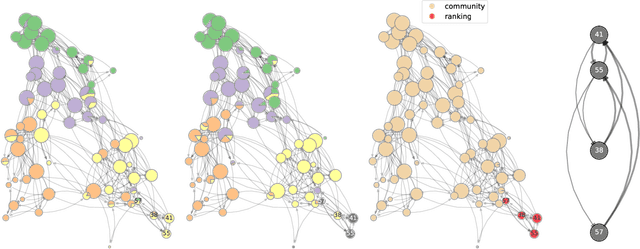
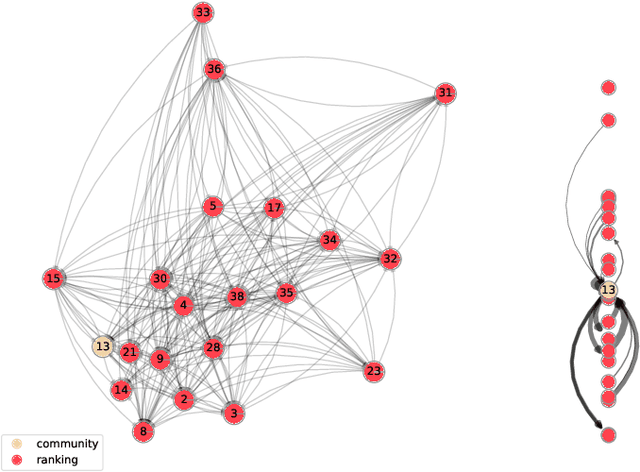
Community detection and hierarchy extraction are usually thought of as separate inference tasks on networks. Considering only one of the two when studying real-world data can be an oversimplification. In this work, we present a generative model based on an interplay between community and hierarchical structures. It assumes that each node has a preference in the interaction mechanism and nodes with the same preference are more likely to interact, while heterogeneous interactions are still allowed. The algorithmic implementation is efficient, as it exploits the sparsity of network datasets. We demonstrate our method on synthetic and real-world data and compare performance with two standard approaches for community detection and ranking extraction. We find that the algorithm accurately retrieves each node's preference in different scenarios and we show that it can distinguish small subsets of nodes that behave differently than the majority. As a consequence, the model can recognise whether a network has an overall preferred interaction mechanism. This is relevant in situations where there is no clear "a priori" information about what structure explains the observed network datasets well. Our model allows practitioners to learn this automatically from the data.