 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-dependent Exploration for Online Reinforcement Learning from Human Feedback
May 06, 2026Online reinforcement learning from human feedback (RLHF) has emerged as a promising paradigm for aligning large language models (LLMs) by continuously collecting new preference feedback during training. A foundational challenge in this setting is exploration, which requires algorithms that enable the LLMs to generate informative comparisons that improve sample-efficiency in online RLHF. Existing exploration strategies often derive bonuses via on-policy expectations, which are difficult to estimate reliably from the limited historical preference data available during training; as a result, the policy can prematurely down-weight under-explored regions that may contain high-value behaviors. In this paper, we propose data-dependent exploration for preference optimization (DEPO), a simple and scalable method that leverages historical data to construct an extra uncertainty bonus for high-uncertainty regions, encouraging exploration toward potentially high-value data. Theoretically, we provide a data-dependent regret bound for the proposed algorithm, showing that it adapts to the hardness of the learning task itself and can be tighter than worst-case bounds in practice. Empirically, the proposed method consistently outperforms strong baselines across benchmarks, demonstrating improved sample efficiency.
EEG-DLite: Dataset Distillation for Efficient Large EEG Model Training
Dec 13, 2025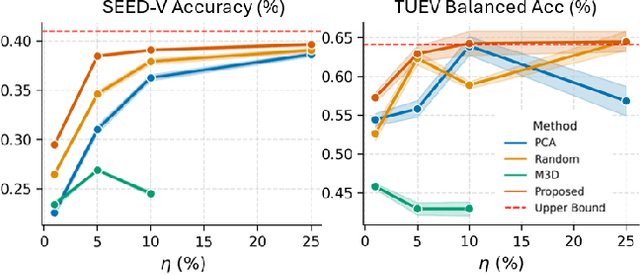
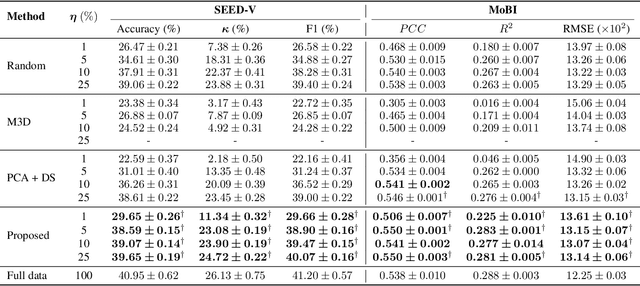
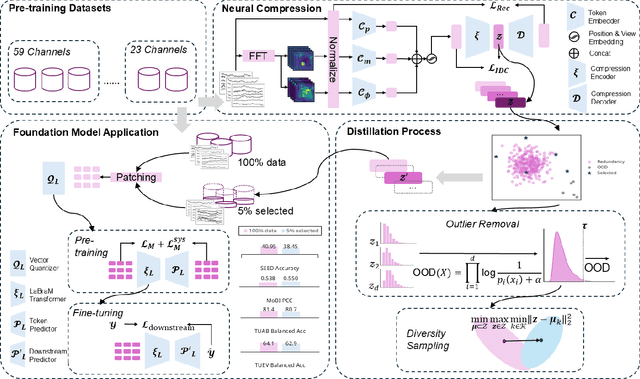
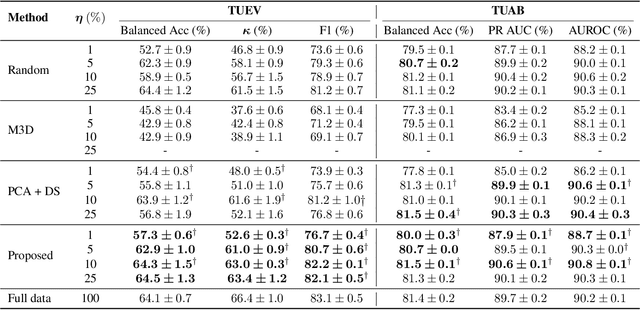
Large-scale EEG foundation models have shown strong generalization across a range of downstream tasks, but their training remains resource-intensive due to the volume and variable quality of EEG data. In this work, we introduce EEG-DLite, a data distillation framework that enables more efficient pre-training by selectively removing noisy and redundant samples from large EEG datasets. EEG-DLite begins by encoding EEG segments into compact latent representations using a self-supervised autoencoder, allowing sample selection to be performed efficiently and with reduced sensitivity to noise. Based on these representations, EEG-DLite filters out outliers and minimizes redundancy, resulting in a smaller yet informative subset that retains the diversity essential for effective foundation model training. Through extensive experiments, we demonstrate that training on only 5 percent of a 2,500-hour dataset curated with EEG-DLite yields performance comparable to, and in some cases better than, training on the full dataset across multiple downstream tasks. To our knowledge, this is the first systematic study of pre-training data distillation in the context of EEG foundation models. EEG-DLite provides a scalable and practical path toward more effective and efficient physiological foundation modeling. The code is available at https://github.com/t170815518/EEG-DLite.
Beyond Simple Sum of Delayed Rewards: Non-Markovian Reward Modeling for Reinforcement Learning
Oct 26, 2024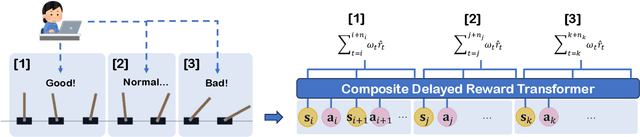
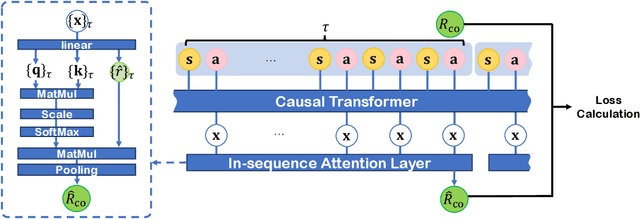
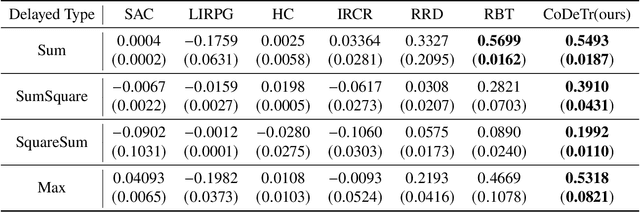
Reinforcement Learning (RL) empowers agents to acquire various skills by learning from reward signals. Unfortunately, designing high-quality instance-level rewards often demands significant effort. An emerging alternative, RL with delayed reward, focuses on learning from rewards presented periodically, which can be obtained from human evaluators assessing the agent's performance over sequences of behaviors. However, traditional methods in this domain assume the existence of underlying Markovian rewards and that the observed delayed reward is simply the sum of instance-level rewards, both of which often do not align well with real-world scenarios. In this paper, we introduce the problem of RL from Composite Delayed Reward (RLCoDe), which generalizes traditional RL from delayed rewards by eliminating the strong assumption. We suggest that the delayed reward may arise from a more complex structure reflecting the overall contribution of the sequence. To address this problem, we present a framework for modeling composite delayed rewards, using a weighted sum of non-Markovian components to capture the different contributions of individual steps. Building on this framework, we propose Composite Delayed Reward Transformer (CoDeTr), which incorporates a specialized in-sequence attention mechanism to effectively model these contributions. We conduct experiments on challenging locomotion tasks where the agent receives delayed rewards computed from composite functions of observable step rewards. The experimental results indicate that CoDeTr consistently outperforms baseline methods across evaluated metrics. Additionally, we demonstrate that it effectively identifies the most significant time steps within the sequence and accurately predicts rewards that closely reflect the environment feedback.
Reinforcement Learning from Bagged Reward: A Transformer-based Approach for Instance-Level Reward Redistribution
Feb 06, 2024In reinforcement Learning (RL), an instant reward signal is generated for each action of the agent, such that the agent learns to maximize the cumulative reward to obtain the optimal policy. However, in many real-world applications, the instant reward signals are not obtainable by the agent. Instead, the learner only obtains rewards at the ends of bags, where a bag is defined as a partial sequence of a complete trajectory. In this situation, the learner has to face the significant difficulty of exploring the unknown instant rewards in the bags, which could not be addressed by existing approaches, including those trajectory-based approaches that consider only complete trajectories and ignore the inner reward distributions. To formally study this situation, we introduce a novel RL setting termed Reinforcement Learning from Bagged Rewards (RLBR), where only the bagged rewards of sequences can be obtained. We provide the theoretical study to establish the connection between RLBR and standard RL in Markov Decision Processes (MDPs). To effectively explore the reward distributions within the bagged rewards, we propose a Transformer-based reward model, the Reward Bag Transformer (RBT), which uses the self-attention mechanism for interpreting the contextual nuances and temporal dependencies within each bag. Extensive experimental analyses demonstrate the superiority of our method, particularly in its ability to mimic the original MDP's reward distribution, highlighting its proficiency in contextual understanding and adaptability to environmental dynamics.
Learning from Multiple Unlabeled Datasets with Partial Risk Regularization
Jul 04, 2022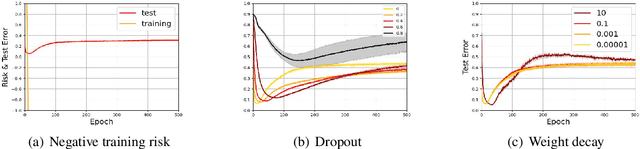
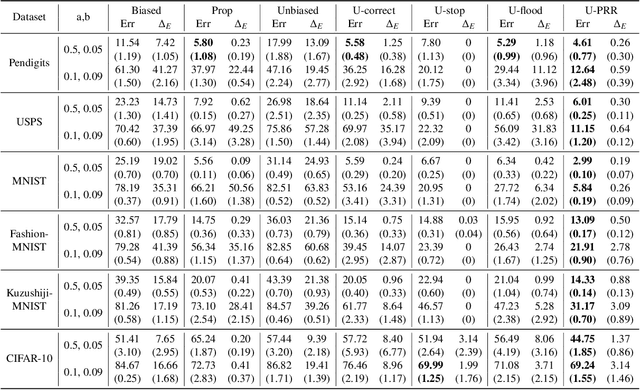
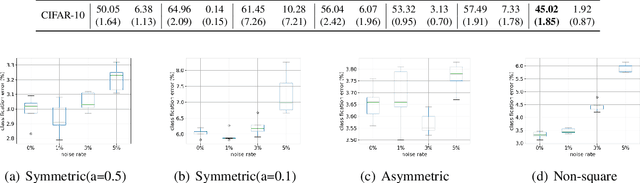
Recent years have witnessed a great success of supervised deep learning, where predictive models were trained from a large amount of fully labeled data. However, in practice, labeling such big data can be very costly and may not even be possible for privacy reasons. Therefore, in this paper, we aim to learn an accurate classifier without any class labels. More specifically, we consider the case where multiple sets of unlabeled data and only their class priors, i.e., the proportions of each class, are available. Under this problem setup, we first derive an unbiased estimator of the classification risk that can be estimated from the given unlabeled sets and theoretically analyze the generalization error of the learned classifier. We then find that the classifier obtained as such tends to cause overfitting as its empirical risks go negative during training. To prevent overfitting, we further propose a partial risk regularization that maintains the partial risks with respect to unlabeled datasets and classes to certain levels. Experiments demonstrate that our method effectively mitigates overfitting and outperforms state-of-the-art methods for learning from multiple unlabeled sets.