 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLGOR: Visual-Language Knowledge Guided Offline Reinforcement Learning for Generalizable Agents
Mar 24, 2026Combining Large Language Models (LLMs) with Reinforcement Learning (RL) enables agents to interpret language instructions more effectively for task execution. However, LLMs typically lack direct perception of the physical environment, which limits their understanding of environmental dynamics and their ability to generalize to unseen tasks. To address this limitation, we propose Visual-Language Knowledge-Guided Offline Reinforcement Learning (VLGOR), a framework that integrates visual and language knowledge to generate imaginary rollouts, thereby enriching the interaction data. The core premise of VLGOR is to fine-tune a vision-language model to predict future states and actions conditioned on an initial visual observation and high-level instructions, ensuring that the generated rollouts remain temporally coherent and spatially plausible. Furthermore, we employ counterfactual prompts to produce more diverse rollouts for offline RL training, enabling the agent to acquire knowledge that facilitates following language instructions while grounding in environments based on visual cues. Experiments on robotic manipulation benchmarks demonstrate that VLGOR significantly improves performance on unseen tasks requiring novel optimal policies, achieving a success rate over 24% higher than the baseline methods.
RLVR Training of LLMs Does Not Improve Thinking Ability for General QA: Evaluation Method and a Simple Solution
Mar 21, 2026Reinforcement learning from verifiable rewards (RLVR) stimulates the thinking processes of large language models (LLMs), substantially enhancing their reasoning abilities on verifiable tasks. It is often assumed that similar gains should transfer to general question answering (GQA), but this assumption has not been thoroughly validated. To assess whether RLVR automatically improves LLM performance on GQA, we propose a Cross-Generation evaluation framework that measures the quality of intermediate reasoning by feeding the generated thinking context into LLMs of varying capabilities. Our evaluation leads to a discouraging finding: the efficacy of the thinking process on GQA tasks is markedly lower than on verifiable tasks, suggesting that explicit training on GQA remains necessary in addition to training on verifiable tasks. We further observe that direct RL training on GQA is less effective than RLVR. Our hypothesis is that, whereas verifiable tasks demand robust logical chains to obtain high rewards, GQA tasks often admit shortcuts to high rewards without cultivating high-quality thinking. To avoid possible shortcuts, we introduce a simple method, Separated Thinking And Response Training (START), which first trains only the thinking process, using rewards defined on the final answer. We show that START improves both the quality of thinking and the final answer across several GQA benchmarks and RL algorithms.
Reinforcement Learning with Promising Tokens for Large Language Models
Feb 03, 2026Reinforcement learning (RL) has emerged as a key paradigm for aligning and optimizing large language models (LLMs). Standard approaches treat the LLM as the policy and apply RL directly over the full vocabulary space. However, this formulation includes the massive tail of contextually irrelevant tokens in the action space, which could distract the policy from focusing on decision-making among the truly reasonable tokens. In this work, we verify that valid reasoning paths could inherently concentrate within a low-rank subspace. Based on this insight, we introduce Reinforcement Learning with Promising Tokens (RLPT), a framework that mitigates the action space issue by decoupling strategic decision-making from token generation. Specifically, RLPT leverages the semantic priors of the base model to identify a dynamic set of \emph{promising tokens} and constrains policy optimization exclusively to this refined subset via masking. Theoretical analysis and empirical results demonstrate that RLPT effectively reduces gradient variance, stabilizes the training process, and improves sample efficiency. Experiment results on math, coding, and telecom reasoning show that RLPT outperforms standard RL baselines and integrates effectively across various model sizes (4B and 8B) and RL algorithms (GRPO and DAPO).
EDCO: Dynamic Curriculum Orchestration for Domain-specific Large Language Model Fine-tuning
Jan 07, 2026Domain-specific large language models (LLMs), typically developed by fine-tuning a pre-trained general-purpose LLM on specialized datasets, represent a significant advancement in applied AI. A common strategy in LLM fine-tuning is curriculum learning, which pre-orders training samples based on metrics like difficulty to improve learning efficiency compared to a random sampling strategy. However, most existing methods for LLM fine-tuning rely on a static curriculum, designed prior to training, which lacks adaptability to the model's evolving needs during fine-tuning. To address this, we propose EDCO, a novel framework based on two key concepts: inference entropy and dynamic curriculum orchestration. Inspired by recent findings that maintaining high answer entropy benefits long-term reasoning gains, EDCO prioritizes samples with high inference entropy in a continuously adapted curriculum. EDCO integrates three core components: an efficient entropy estimator that uses prefix tokens to approximate full-sequence entropy, an entropy-based curriculum generator that selects data points with the highest inference entropy, and an LLM trainer that optimizes the model on the selected curriculum. Comprehensive experiments in communication, medicine and law domains, EDCO outperforms traditional curriculum strategies for fine-tuning Qwen3-4B and Llama3.2-3B models under supervised and reinforcement learning settings. Furthermore, the proposed efficient entropy estimation reduces computational time by 83.5% while maintaining high accuracy.
ReLAM: Learning Anticipation Model for Rewarding Visual Robotic Manipulation
Sep 26, 2025Reward design remains a critical bottleneck in visual reinforcement learning (RL) for robotic manipulation. In simulated environments, rewards are conventionally designed based on the distance to a target position. However, such precise positional information is often unavailable in real-world visual settings due to sensory and perceptual limitations. In this study, we propose a method that implicitly infers spatial distances through keypoints extracted from images. Building on this, we introduce Reward Learning with Anticipation Model (ReLAM), a novel framework that automatically generates dense, structured rewards from action-free video demonstrations. ReLAM first learns an anticipation model that serves as a planner and proposes intermediate keypoint-based subgoals on the optimal path to the final goal, creating a structured learning curriculum directly aligned with the task's geometric objectives. Based on the anticipated subgoals, a continuous reward signal is provided to train a low-level, goal-conditioned policy under the hierarchical reinforcement learning (HRL) framework with provable sub-optimality bound. Extensive experiments on complex, long-horizon manipulation tasks show that ReLAM significantly accelerates learning and achieves superior performance compared to state-of-the-art methods.
ImagineBench: Evaluating Reinforcement Learning with Large Language Model Rollouts
May 15, 2025A central challenge in reinforcement learning (RL) is its dependence on extensive real-world interaction data to learn task-specific policies. While recent work demonstrates that large language models (LLMs) can mitigate this limitation by generating synthetic experience (noted as imaginary rollouts) for mastering novel tasks, progress in this emerging field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ImagineBench, the first comprehensive benchmark for evaluating offline RL algorithms that leverage both real rollouts and LLM-imaginary rollouts. The key features of ImagineBench include: (1) datasets comprising environment-collected and LLM-imaginary rollouts; (2) diverse domains of environments covering locomotion, robotic manipulation, and navigation tasks; and (3) natural language task instructions with varying complexity levels to facilitate language-conditioned policy learning. Through systematic evaluation of state-of-the-art offline RL algorithms, we observe that simply applying existing offline RL algorithms leads to suboptimal performance on unseen tasks, achieving 35.44% success rate in hard tasks in contrast to 64.37% of method training on real rollouts for hard tasks. This result highlights the need for algorithm advancements to better leverage LLM-imaginary rollouts. Additionally, we identify key opportunities for future research: including better utilization of imaginary rollouts, fast online adaptation and continual learning, and extension to multi-modal tasks. Our code is publicly available at https://github.com/LAMDA-RL/ImagineBench.
Beyond Simple Sum of Delayed Rewards: Non-Markovian Reward Modeling for Reinforcement Learning
Oct 26, 2024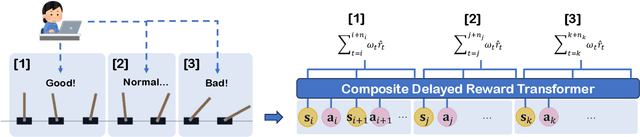
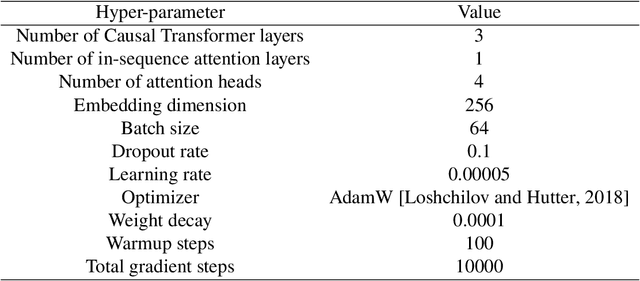
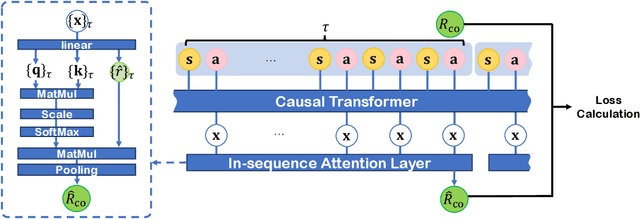
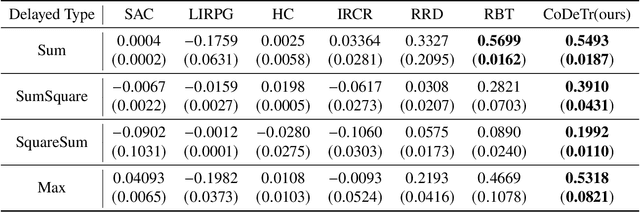
Reinforcement Learning (RL) empowers agents to acquire various skills by learning from reward signals. Unfortunately, designing high-quality instance-level rewards often demands significant effort. An emerging alternative, RL with delayed reward, focuses on learning from rewards presented periodically, which can be obtained from human evaluators assessing the agent's performance over sequences of behaviors. However, traditional methods in this domain assume the existence of underlying Markovian rewards and that the observed delayed reward is simply the sum of instance-level rewards, both of which often do not align well with real-world scenarios. In this paper, we introduce the problem of RL from Composite Delayed Reward (RLCoDe), which generalizes traditional RL from delayed rewards by eliminating the strong assumption. We suggest that the delayed reward may arise from a more complex structure reflecting the overall contribution of the sequence. To address this problem, we present a framework for modeling composite delayed rewards, using a weighted sum of non-Markovian components to capture the different contributions of individual steps. Building on this framework, we propose Composite Delayed Reward Transformer (CoDeTr), which incorporates a specialized in-sequence attention mechanism to effectively model these contributions. We conduct experiments on challenging locomotion tasks where the agent receives delayed rewards computed from composite functions of observable step rewards. The experimental results indicate that CoDeTr consistently outperforms baseline methods across evaluated metrics. Additionally, we demonstrate that it effectively identifies the most significant time steps within the sequence and accurately predicts rewards that closely reflect the environment feedback.
Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
Apr 14, 2024



Reinforcement learning (RL) trains agents to accomplish complex tasks through environmental interaction data, but its capacity is also limited by the scope of the available data. To obtain a knowledgeable agent, a promising approach is to leverage the knowledge from large language models (LLMs). Despite previous studies combining LLMs with RL, seamless integration of the two components remains challenging due to their semantic gap. This paper introduces a novel method, Knowledgeable Agents from Language Model Rollouts (KALM), which extracts knowledge from LLMs in the form of imaginary rollouts that can be easily learned by the agent through offline reinforcement learning methods. The primary challenge of KALM lies in LLM grounding, as LLMs are inherently limited to textual data, whereas environmental data often comprise numerical vectors unseen to LLMs. To address this, KALM fine-tunes the LLM to perform various tasks based on environmental data, including bidirectional translation between natural language descriptions of skills and their corresponding rollout data. This grounding process enhances the LLM's comprehension of environmental dynamics, enabling it to generate diverse and meaningful imaginary rollouts that reflect novel skills. Initial empirical evaluations on the CLEVR-Robot environment demonstrate that KALM enables agents to complete complex rephrasings of task goals and extend their capabilities to novel tasks requiring unprecedented optimal behaviors. KALM achieves a success rate of 46% in executing tasks with unseen goals, substantially surpassing the 26% success rate achieved by baseline methods. Furthermore, KALM effectively enables the LLM to comprehend environmental dynamics, resulting in the generation of meaningful imaginary rollouts that reflect novel skills and demonstrate the seamless integration of large language models and reinforcement learning.
Empowering Language Models with Active Inquiry for Deeper Understanding
Feb 06, 2024The rise of large language models (LLMs) has revolutionized the way that we interact with artificial intelligence systems through natural language. However, LLMs often misinterpret user queries because of their uncertain intention, leading to less helpful responses. In natural human interactions, clarification is sought through targeted questioning to uncover obscure information. Thus, in this paper, we introduce LaMAI (Language Model with Active Inquiry), designed to endow LLMs with this same level of interactive engagement. LaMAI leverages active learning techniques to raise the most informative questions, fostering a dynamic bidirectional dialogue. This approach not only narrows the contextual gap but also refines the output of the LLMs, aligning it more closely with user expectations. Our empirical studies, across a variety of complex datasets where LLMs have limited conversational context, demonstrate the effectiveness of LaMAI. The method improves answer accuracy from 31.9% to 50.9%, outperforming other leading question-answering frameworks. Moreover, in scenarios involving human participants, LaMAI consistently generates responses that are superior or comparable to baseline methods in more than 82% of the cases. The applicability of LaMAI is further evidenced by its successful integration with various LLMs, highlighting its potential for the future of interactive language models.
Language Model Self-improvement by Reinforcement Learning Contemplation
May 23, 2023



Large Language Models (LLMs) have exhibited remarkable performance across various natural language processing (NLP) tasks. However, fine-tuning these models often necessitates substantial supervision, which can be expensive and time-consuming to obtain. This paper introduces a novel unsupervised method called LanguageModel Self-Improvement by Reinforcement Learning Contemplation (SIRLC) that improves LLMs without reliance on external labels. Our approach is grounded in the observation that it is simpler for language models to assess text quality than to generate text. Building on this insight, SIRLC assigns LLMs dual roles as both student and teacher. As a student, the LLM generates answers to unlabeled questions, while as a teacher, it evaluates the generated text and assigns scores accordingly. The model parameters are updated using reinforcement learning to maximize the evaluation score. We demonstrate that SIRLC can be applied to various NLP tasks, such as reasoning problems, text generation, and machine translation. Our experiments show that SIRLC effectively improves LLM performance without external supervision, resulting in a 5.6% increase in answering accuracy for reasoning tasks and a rise in BERTScore from 0.82 to 0.86 for translation tasks. Furthermore, SIRLC can be applied to models of different sizes, showcasing its broad applicability.