 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Sequence Policy Optimization
Jul 24, 2025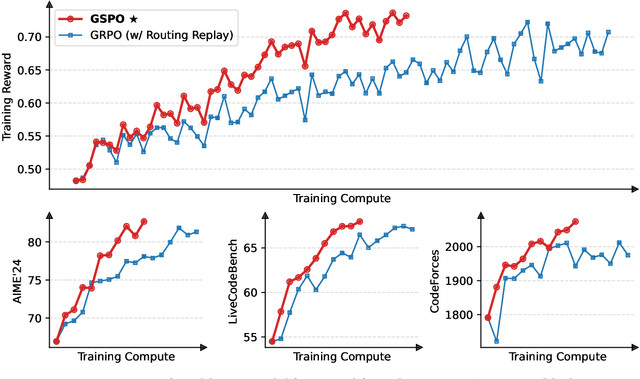
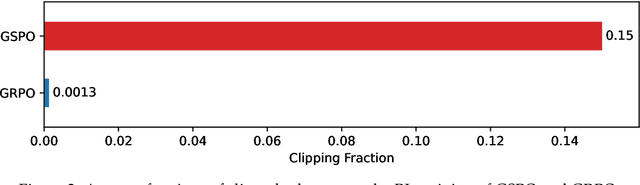
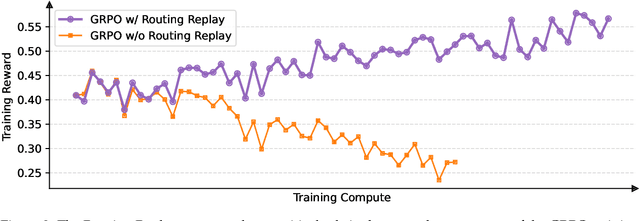
This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training large language models. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models.
NeoRL-2: Near Real-World Benchmarks for Offline Reinforcement Learning with Extended Realistic Scenarios
Mar 25, 2025
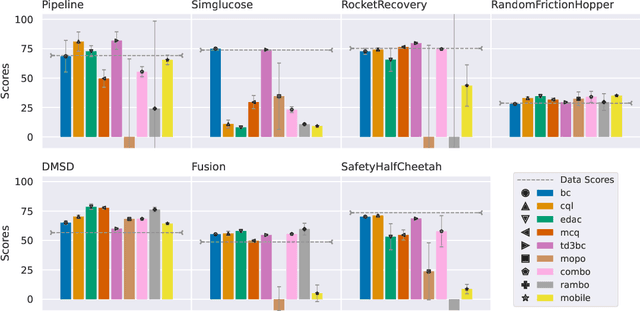
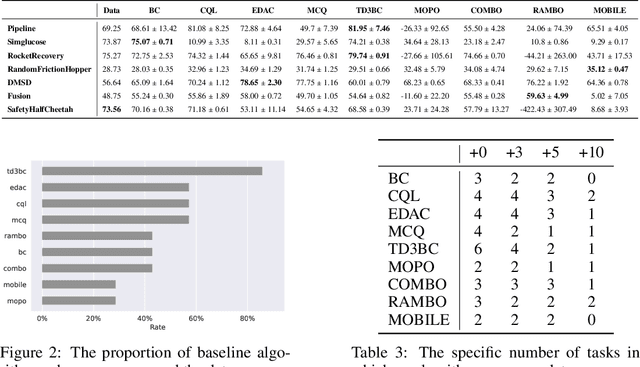
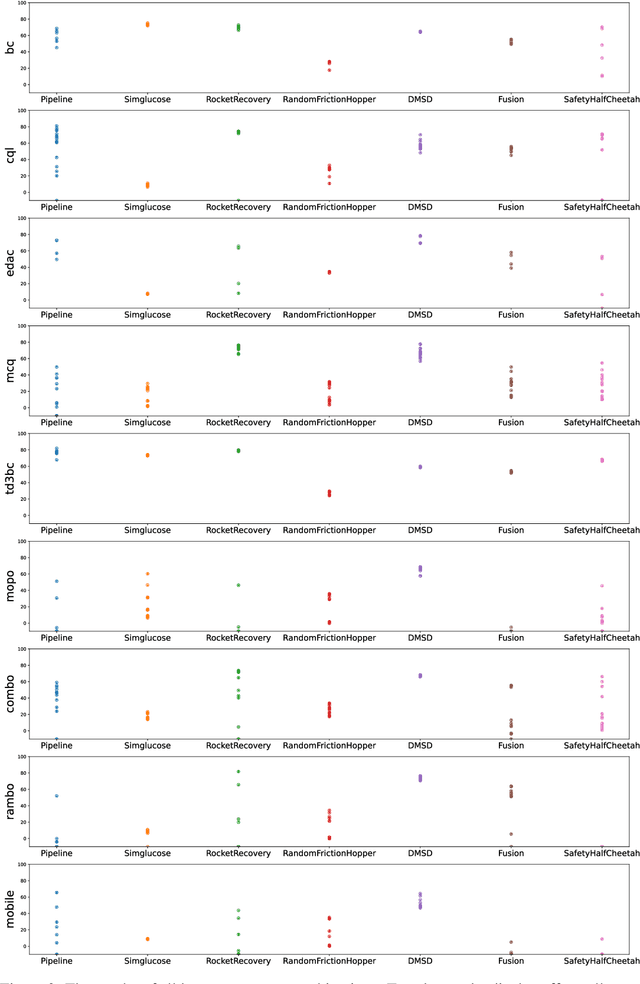
Offline reinforcement learning (RL) aims to learn from historical data without requiring (costly) access to the environment. To facilitate offline RL research, we previously introduced NeoRL, which highlighted that datasets from real-world tasks are often conservative and limited. With years of experience applying offline RL to various domains, we have identified additional real-world challenges. These include extremely conservative data distributions produced by deployed control systems, delayed action effects caused by high-latency transitions, external factors arising from the uncontrollable variance of transitions, and global safety constraints that are difficult to evaluate during the decision-making process. These challenges are underrepresented in previous benchmarks but frequently occur in real-world tasks. To address this, we constructed the extended Near Real-World Offline RL Benchmark (NeoRL-2), which consists of 7 datasets from 7 simulated tasks along with their corresponding evaluation simulators. Benchmarking results from state-of-the-art offline RL approaches demonstrate that current methods often struggle to outperform the data-collection behavior policy, highlighting the need for more effective methods. We hope NeoRL-2 will accelerate the development of reinforcement learning algorithms for real-world applications. The benchmark project page is available at https://github.com/polixir/NeoRL2.
Knowledgeable Agents by Offline Reinforcement Learning from Large Language Model Rollouts
Apr 14, 2024



Reinforcement learning (RL) trains agents to accomplish complex tasks through environmental interaction data, but its capacity is also limited by the scope of the available data. To obtain a knowledgeable agent, a promising approach is to leverage the knowledge from large language models (LLMs). Despite previous studies combining LLMs with RL, seamless integration of the two components remains challenging due to their semantic gap. This paper introduces a novel method, Knowledgeable Agents from Language Model Rollouts (KALM), which extracts knowledge from LLMs in the form of imaginary rollouts that can be easily learned by the agent through offline reinforcement learning methods. The primary challenge of KALM lies in LLM grounding, as LLMs are inherently limited to textual data, whereas environmental data often comprise numerical vectors unseen to LLMs. To address this, KALM fine-tunes the LLM to perform various tasks based on environmental data, including bidirectional translation between natural language descriptions of skills and their corresponding rollout data. This grounding process enhances the LLM's comprehension of environmental dynamics, enabling it to generate diverse and meaningful imaginary rollouts that reflect novel skills. Initial empirical evaluations on the CLEVR-Robot environment demonstrate that KALM enables agents to complete complex rephrasings of task goals and extend their capabilities to novel tasks requiring unprecedented optimal behaviors. KALM achieves a success rate of 46% in executing tasks with unseen goals, substantially surpassing the 26% success rate achieved by baseline methods. Furthermore, KALM effectively enables the LLM to comprehend environmental dynamics, resulting in the generation of meaningful imaginary rollouts that reflect novel skills and demonstrate the seamless integration of large language models and reinforcement learning.
Imitator Learning: Achieve Out-of-the-Box Imitation Ability in Variable Environments
Oct 09, 2023Imitation learning (IL) enables agents to mimic expert behaviors. Most previous IL techniques focus on precisely imitating one policy through mass demonstrations. However, in many applications, what humans require is the ability to perform various tasks directly through a few demonstrations of corresponding tasks, where the agent would meet many unexpected changes when deployed. In this scenario, the agent is expected to not only imitate the demonstration but also adapt to unforeseen environmental changes. This motivates us to propose a new topic called imitator learning (ItorL), which aims to derive an imitator module that can on-the-fly reconstruct the imitation policies based on very limited expert demonstrations for different unseen tasks, without any extra adjustment. In this work, we focus on imitator learning based on only one expert demonstration. To solve ItorL, we propose Demo-Attention Actor-Critic (DAAC), which integrates IL into a reinforcement-learning paradigm that can regularize policies' behaviors in unexpected situations. Besides, for autonomous imitation policy building, we design a demonstration-based attention architecture for imitator policy that can effectively output imitated actions by adaptively tracing the suitable states in demonstrations. We develop a new navigation benchmark and a robot environment for \topic~and show that DAAC~outperforms previous imitation methods \textit{with large margins} both on seen and unseen tasks.
Language Model Self-improvement by Reinforcement Learning Contemplation
May 23, 2023



Large Language Models (LLMs) have exhibited remarkable performance across various natural language processing (NLP) tasks. However, fine-tuning these models often necessitates substantial supervision, which can be expensive and time-consuming to obtain. This paper introduces a novel unsupervised method called LanguageModel Self-Improvement by Reinforcement Learning Contemplation (SIRLC) that improves LLMs without reliance on external labels. Our approach is grounded in the observation that it is simpler for language models to assess text quality than to generate text. Building on this insight, SIRLC assigns LLMs dual roles as both student and teacher. As a student, the LLM generates answers to unlabeled questions, while as a teacher, it evaluates the generated text and assigns scores accordingly. The model parameters are updated using reinforcement learning to maximize the evaluation score. We demonstrate that SIRLC can be applied to various NLP tasks, such as reasoning problems, text generation, and machine translation. Our experiments show that SIRLC effectively improves LLM performance without external supervision, resulting in a 5.6% increase in answering accuracy for reasoning tasks and a rise in BERTScore from 0.82 to 0.86 for translation tasks. Furthermore, SIRLC can be applied to models of different sizes, showcasing its broad applicability.
Sim2Rec: A Simulator-based Decision-making Approach to Optimize Real-World Long-term User Engagement in Sequential Recommender Systems
May 03, 2023Long-term user engagement (LTE) optimization in sequential recommender systems (SRS) is shown to be suited by reinforcement learning (RL) which finds a policy to maximize long-term rewards. Meanwhile, RL has its shortcomings, particularly requiring a large number of online samples for exploration, which is risky in real-world applications. One of the appealing ways to avoid the risk is to build a simulator and learn the optimal recommendation policy in the simulator. In LTE optimization, the simulator is to simulate multiple users' daily feedback for given recommendations. However, building a user simulator with no reality-gap, i.e., can predict user's feedback exactly, is unrealistic because the users' reaction patterns are complex and historical logs for each user are limited, which might mislead the simulator-based recommendation policy. In this paper, we present a practical simulator-based recommender policy training approach, Simulation-to-Recommendation (Sim2Rec) to handle the reality-gap problem for LTE optimization. Specifically, Sim2Rec introduces a simulator set to generate various possibilities of user behavior patterns, then trains an environment-parameter extractor to recognize users' behavior patterns in the simulators. Finally, a context-aware policy is trained to make the optimal decisions on all of the variants of the users based on the inferred environment-parameters. The policy is transferable to unseen environments (e.g., the real world) directly as it has learned to recognize all various user behavior patterns and to make the correct decisions based on the inferred environment-parameters. Experiments are conducted in synthetic environments and a real-world large-scale ride-hailing platform, DidiChuxing. The results show that Sim2Rec achieves significant performance improvement, and produces robust recommendations in unseen environments.
A Survey on Model-based Reinforcement Learning
Jun 19, 2022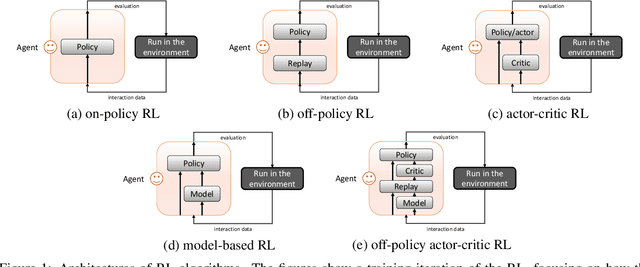
Reinforcement learning (RL) solves sequential decision-making problems via a trial-and-error process interacting with the environment. While RL achieves outstanding success in playing complex video games that allow huge trial-and-error, making errors is always undesired in the real world. To improve the sample efficiency and thus reduce the errors, model-based reinforcement learning (MBRL) is believed to be a promising direction, which builds environment models in which the trial-and-errors can take place without real costs. In this survey, we take a review of MBRL with a focus on the recent progress in deep RL. For non-tabular environments, there is always a generalization error between the learned environment model and the real environment. As such, it is of great importance to analyze the discrepancy between policy training in the environment model and that in the real environment, which in turn guides the algorithm design for better model learning, model usage, and policy training. Besides, we also discuss the recent advances of model-based techniques in other forms of RL, including offline RL, goal-conditioned RL, multi-agent RL, and meta-RL. Moreover, we discuss the applicability and advantages of MBRL in real-world tasks. Finally, we end this survey by discussing the promising prospects for the future development of MBRL. We think that MBRL has great potential and advantages in real-world applications that were overlooked, and we hope this survey could attract more research on MBRL.
Adversarial Counterfactual Environment Model Learning
Jun 10, 2022

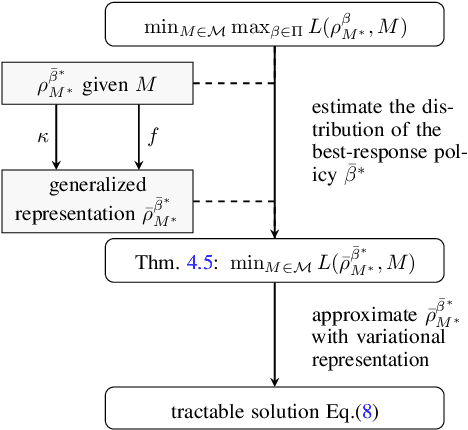

A good model for action-effect prediction, named environment model, is important to achieve sample-efficient decision-making policy learning in many domains like robot control, recommender systems, and patients' treatment selection. We can take unlimited trials with such a model to identify the appropriate actions so that the costs of queries in the real world can be saved. It requires the model to handle unseen data correctly, also called counterfactual data. However, standard data fitting techniques do not automatically achieve such generalization ability and commonly result in unreliable models. In this work, we introduce counterfactual-query risk minimization (CQRM) in model learning for generalizing to a counterfactual dataset queried by a specific target policy. Since the target policies can be various and unknown in policy learning, we propose an adversarial CQRM objective in which the model learns on counterfactual data queried by adversarial policies, and finally derive a tractable solution GALILEO. We also discover that adversarial CQRM is closely related to the adversarial model learning, explaining the effectiveness of the latter. We apply GALILEO in synthetic tasks and a real-world application. The results show that GALILEO makes accurate predictions on counterfactual data and thus significantly improves policies in real-world testing.
Offline Reinforcement Learning with Causal Structured World Models
Jun 03, 2022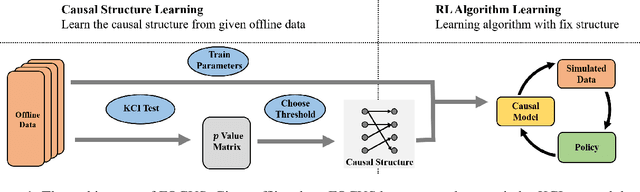

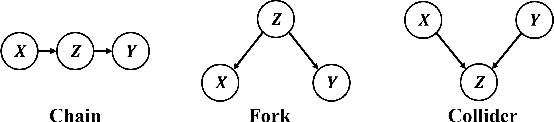
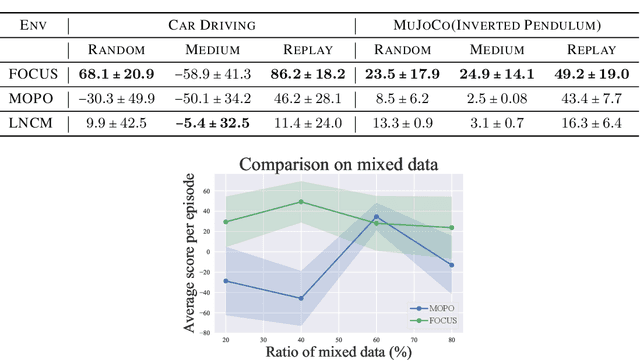
Model-based methods have recently shown promising for offline reinforcement learning (RL), aiming to learn good policies from historical data without interacting with the environment. Previous model-based offline RL methods learn fully connected nets as world-models that map the states and actions to the next-step states. However, it is sensible that a world-model should adhere to the underlying causal effect such that it will support learning an effective policy generalizing well in unseen states. In this paper, We first provide theoretical results that causal world-models can outperform plain world-models for offline RL by incorporating the causal structure into the generalization error bound. We then propose a practical algorithm, oFfline mOdel-based reinforcement learning with CaUsal Structure (FOCUS), to illustrate the feasibility of learning and leveraging causal structure in offline RL. Experimental results on two benchmarks show that FOCUS reconstructs the underlying causal structure accurately and robustly. Consequently, it performs better than the plain model-based offline RL algorithms and other causal model-based RL algorithms.