 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning with Causal Structured World Models
Jun 03, 2022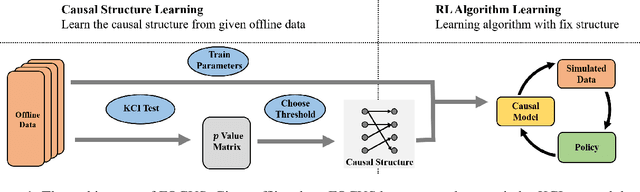

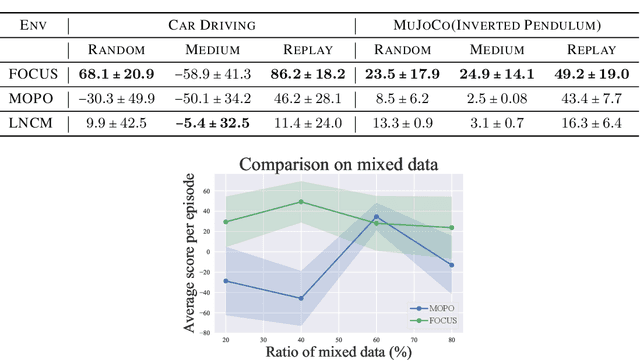
Model-based methods have recently shown promising for offline reinforcement learning (RL), aiming to learn good policies from historical data without interacting with the environment. Previous model-based offline RL methods learn fully connected nets as world-models that map the states and actions to the next-step states. However, it is sensible that a world-model should adhere to the underlying causal effect such that it will support learning an effective policy generalizing well in unseen states. In this paper, We first provide theoretical results that causal world-models can outperform plain world-models for offline RL by incorporating the causal structure into the generalization error bound. We then propose a practical algorithm, oFfline mOdel-based reinforcement learning with CaUsal Structure (FOCUS), to illustrate the feasibility of learning and leveraging causal structure in offline RL. Experimental results on two benchmarks show that FOCUS reconstructs the underlying causal structure accurately and robustly. Consequently, it performs better than the plain model-based offline RL algorithms and other causal model-based RL algorithms.