 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Imitation Learning with General Function Approximation: Theoretical Analysis and Practical Algorithms
May 03, 2026Adversarial imitation learning (AIL), a prominent approach in imitation learning, has achieved significant practical success powered by neural network approximation. However, existing theoretical analyses of AIL are primarily confined to simplified settings, such as tabular and linear function approximation, and involve complex algorithmic designs that impede practical implementation. This creates a substantial gap between theory and practice. This paper bridges this gap by exploring the theoretical underpinnings of online AIL with general function approximation. We introduce a novel framework called optimization-based AIL (OPT-AIL), which performs online optimization for reward learning coupled with optimism-regularized optimization for policy learning. Within this framework, we develop two concrete methods: model-free OPT-AIL and model-based OPT-AIL. Our theoretical analysis demonstrates that both variants achieve polynomial expert sample complexity and interaction complexity for learning near-expert policies. To the best of our knowledge, they represent the first provably efficient AIL methods under general function approximation. From a practical standpoint, OPT-AIL requires only the approximate optimization of two objectives, thereby facilitating practical implementation. Empirical studies demonstrate that OPT-AIL outperforms previous state-of-the-art deep AIL methods across several challenging tasks.
How Can Reinforcement Learning Achieve Expert-level Placement?
Apr 28, 2026Chip placement is a critical step in physical design. While reinforcement learning (RL)-based methods have recently emerged, their training primarily focuses on wirelength optimization, and therefore often fail to achieve expert-quality layouts. We identify the reward design as the primary cause for the performance gap with experts, and instead of formalizing intricate processes, we circumvent this by directly learning from expert layouts to derive a reward model. Our approach starts from the final expert layouts to infer step-by-step expert trajectories. Using these trajectories as demonstrations or preferences, we train a model that captures the latent implicit rewards in expert results. Experiments show that our framework can efficiently learn from even a single design and generalize well to unseen cases.
Off-Policy Value-Based Reinforcement Learning for Large Language Models
Mar 24, 2026Improving data utilization efficiency is critical for scaling reinforcement learning (RL) for long-horizon tasks where generating trajectories is expensive. However, the dominant RL methods for LLMs are largely on-policy: they update each batch of data only once, discard it, and then collect fresh samples, resulting in poor sample efficiency. In this work, we explore an alternative value-based RL framework for LLMs that naturally enables off-policy learning. We propose ReVal, a Bellman-update-based method that combines stepwise signals capturing internal consistency with trajectory-level signals derived from outcome verification. ReVal naturally supports replay-buffer-based training, allowing efficient reuse of past trajectories. Experiments on standard mathematical reasoning benchmarks show that ReVal not only converges faster but also outperforms GRPO in final performance. On DeepSeek-R1-Distill-1.5B, ReVal improves training efficiency and achieves improvement of 2.7% in AIME24 and 4.5% in out-of-domain benchmark GPQA over GRPO. These results suggest that value-based RL is a practical alternative to policy-based methods for LLM training.
Non-Adversarial Imitation Learning Provably Free of Compounding Errors: The Role of Bellman Constraints
Mar 24, 2026Adversarial imitation learning (AIL) achieves high-quality imitation by mitigating compounding errors in behavioral cloning (BC), but often exhibits training instability due to adversarial optimization. To avoid this issue, a class of non-adversarial Q-based imitation learning (IL) methods, represented by IQ-Learn, has emerged and is widely believed to outperform BC by leveraging online environment interactions. However, this paper revisits IQ-Learn and demonstrates that it provably reduces to BC and suffers from an imitation gap lower bound with quadratic dependence on horizon, therefore still suffering from compounding errors. Theoretical analysis reveals that, despite using online interactions, IQ-Learn uniformly suppresses the Q-values for all actions on states uncovered by demonstrations, thereby failing to generalize. To address this limitation, we introduce a primal-dual framework for distribution matching, yielding a new Q-based IL method, Dual Q-DM. The key mechanism in Dual Q-DM is incorporating Bellman constraints to propagate high Q-values from visited states to unvisited ones, thereby achieving generalization beyond demonstrations. We prove that Dual Q-DM is equivalent to AIL and can recover expert actions beyond demonstrations, thereby mitigating compounding errors. To the best of our knowledge, Dual Q-DM is the first non-adversarial IL method that is theoretically guaranteed to eliminate compounding errors. Experimental results further corroborate our theoretical results.
Provably and Practically Efficient Adversarial Imitation Learning with General Function Approximation
Nov 01, 2024



As a prominent category of imitation learning methods, adversarial imitation learning (AIL) has garnered significant practical success powered by neural network approximation. However, existing theoretical studies on AIL are primarily limited to simplified scenarios such as tabular and linear function approximation and involve complex algorithmic designs that hinder practical implementation, highlighting a gap between theory and practice. In this paper, we explore the theoretical underpinnings of online AIL with general function approximation. We introduce a new method called optimization-based AIL (OPT-AIL), which centers on performing online optimization for reward functions and optimism-regularized Bellman error minimization for Q-value functions. Theoretically, we prove that OPT-AIL achieves polynomial expert sample complexity and interaction complexity for learning near-expert policies. To our best knowledge, OPT-AIL is the first provably efficient AIL method with general function approximation. Practically, OPT-AIL only requires the approximate optimization of two objectives, thereby facilitating practical implementation. Empirical studies demonstrate that OPT-AIL outperforms previous state-of-the-art deep AIL methods in several challenging tasks.
Collaborative motion planning for multi-manipulator systems through Reinforcement Learning and Dynamic Movement Primitives
Oct 01, 2024Robotic tasks often require multiple manipulators to enhance task efficiency and speed, but this increases complexity in terms of collaboration, collision avoidance, and the expanded state-action space. To address these challenges, we propose a multi-level approach combining Reinforcement Learning (RL) and Dynamic Movement Primitives (DMP) to generate adaptive, real-time trajectories for new tasks in dynamic environments using a demonstration library. This method ensures collision-free trajectory generation and efficient collaborative motion planning. We validate the approach through experiments in the PyBullet simulation environment with UR5e robotic manipulators.
Entropic Distribution Matching in Supervised Fine-tuning of LLMs: Less Overfitting and Better Diversity
Aug 29, 2024Large language models rely on Supervised Fine-Tuning (SFT) to specialize in downstream tasks. Cross Entropy (CE) loss is the de facto choice in SFT, but it often leads to overfitting and limited output diversity due to its aggressive updates to the data distribution. This paper aim to address these issues by introducing the maximum entropy principle, which favors models with flatter distributions that still effectively capture the data. Specifically, we develop a new distribution matching method called GEM, which solves reverse Kullback-Leibler divergence minimization with an entropy regularizer. For the SFT of Llama-3-8B models, GEM outperforms CE in several aspects. First, when applied to the UltraFeedback dataset to develop general instruction-following abilities, GEM exhibits reduced overfitting, evidenced by lower perplexity and better performance on the IFEval benchmark. Furthermore, GEM enhances output diversity, leading to performance gains of up to 7 points on math reasoning and code generation tasks using best-of-n sampling, even without domain-specific data. Second, when fine-tuning with domain-specific datasets for math reasoning and code generation, GEM also shows less overfitting and improvements of up to 10 points compared with CE.
AI-driven platform for systematic nomenclature and intelligent knowledge acquisition of natural medicinal materials
Dec 27, 2023



Natural Medicinal Materials (NMMs) have a long history of global clinical applications, accompanied by extensive informational records. Despite their significant impact on healthcare, the field faces a major challenge: the non-standardization of NMM knowledge, stemming from historical complexities and causing limitations in broader applications. To address this, we introduce a Systematic Nomenclature for NMMs, underpinned by ShennongAlpha, an AI-driven platform designed for intelligent knowledge acquisition. This nomenclature system enables precise identification and differentiation of NMMs. ShennongAlpha, cataloging over ten thousand NMMs with standardized bilingual information, enhances knowledge management and application capabilities, thereby overcoming traditional barriers. Furthermore, it pioneers AI-empowered conversational knowledge acquisition and standardized machine translation. These synergistic innovations mark the first major advance in integrating domain-specific NMM knowledge with AI, propelling research and applications across both NMM and AI fields while establishing a groundbreaking precedent in this crucial area.
Policy Optimization in RLHF: The Impact of Out-of-preference Data
Dec 17, 2023Aligning intelligent agents with human preferences and values is important. This paper examines two popular alignment methods: Direct Preference Optimization (DPO) and Reward-Model-Based Policy Optimization (RMB-PO). A variant of RMB-PO, referred to as RMB-PO+ is also considered. These methods, either explicitly or implicitly, learn a reward model from preference data and differ in the data used for policy optimization to unlock the generalization ability of the reward model. In particular, compared with DPO, RMB-PO additionally uses policy-generated data, and RMB-PO+ further leverages new, preference-free data. We examine the impact of such out-of-preference data. Our study, conducted through controlled and synthetic experiments, demonstrates that DPO performs poorly, whereas RMB-PO+ performs the best. In particular, even when providing the policy model with a good feature representation, we find that policy optimization with adequate out-of-preference data significantly improves performance by harnessing the reward model's generalization capabilities.
ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Oct 17, 2023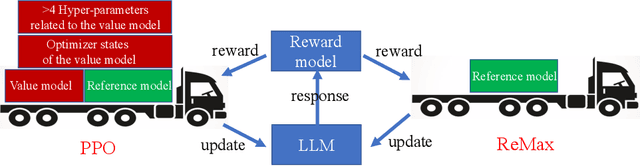

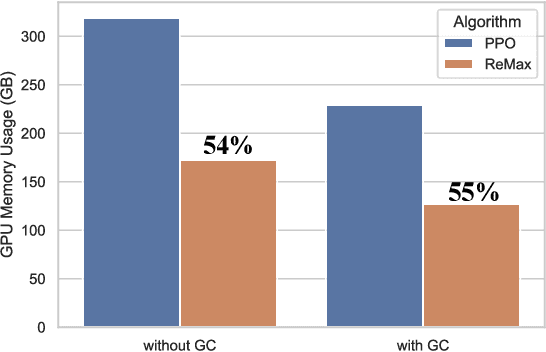
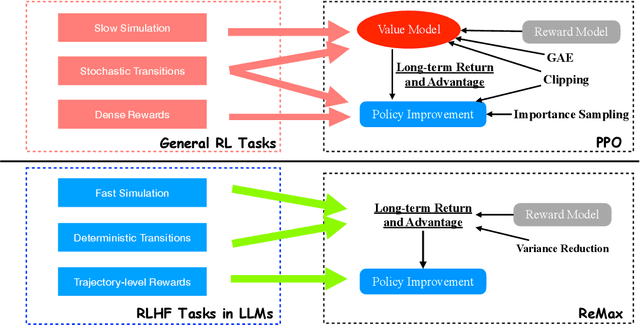
Alignment is of critical importance for training large language models (LLMs). The predominant strategy to address this is through Reinforcement Learning from Human Feedback (RLHF), where PPO serves as the de-facto algorithm. Yet, PPO is known to suffer from computational inefficiency, which is a challenge that this paper aims to address. We identify three important properties in RLHF tasks: fast simulation, deterministic transitions, and trajectory-level rewards, which are not leveraged in PPO. Based on such observations, we develop a new algorithm tailored for RLHF, called ReMax. The algorithm design of ReMax is built on a celebrated algorithm REINFORCE but is equipped with a new variance-reduction technique. Our method has three-fold advantages over PPO: first, ReMax is simple to implement and removes many hyper-parameters in PPO, which are scale-sensitive and laborious to tune. Second, ReMax saves about 50% memory usage in principle. As a result, PPO runs out-of-memory when fine-tuning a Llama2 (7B) model on 8xA100-40GB GPUs, whereas ReMax can afford training. This memory improvement is achieved by removing the value model in PPO. Third, based on our calculations, we find that even assuming PPO can afford the training of Llama2 (7B), it would still run about 2x slower than ReMax. This is due to the computational overhead of the value model, which does not exist in ReMax. Importantly, the above computational improvements do not sacrifice the performance. We hypothesize these advantages can be maintained in larger-scaled models. Our implementation of ReMax is available at https://github.com/liziniu/ReMax