 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models
Paper and Code
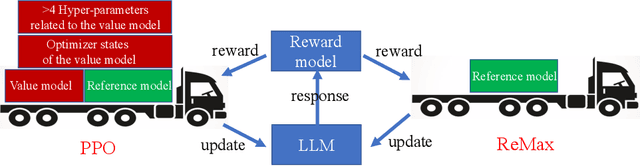

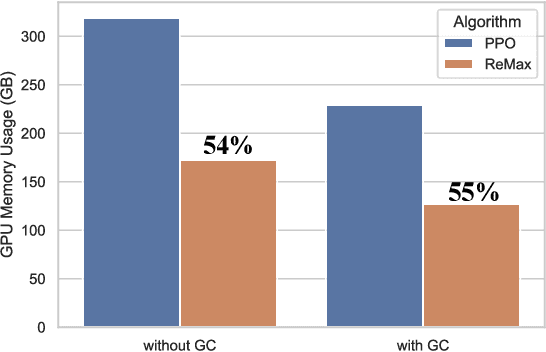
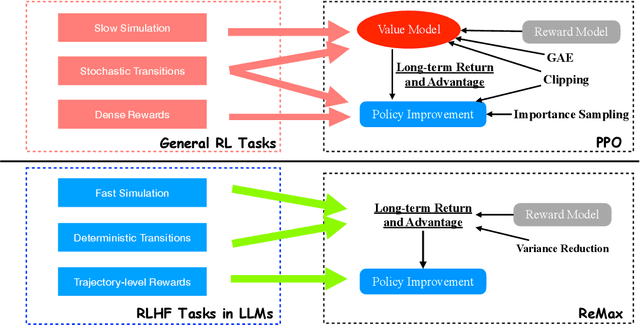
Alignment is of critical importance for training large language models (LLMs). The predominant strategy to address this is through Reinforcement Learning from Human Feedback (RLHF), where PPO serves as the de-facto algorithm. Yet, PPO is known to suffer from computational inefficiency, which is a challenge that this paper aims to address. We identify three important properties in RLHF tasks: fast simulation, deterministic transitions, and trajectory-level rewards, which are not leveraged in PPO. Based on such observations, we develop a new algorithm tailored for RLHF, called ReMax. The algorithm design of ReMax is built on a celebrated algorithm REINFORCE but is equipped with a new variance-reduction technique. Our method has three-fold advantages over PPO: first, ReMax is simple to implement and removes many hyper-parameters in PPO, which are scale-sensitive and laborious to tune. Second, ReMax saves about 50% memory usage in principle. As a result, PPO runs out-of-memory when fine-tuning a Llama2 (7B) model on 8xA100-40GB GPUs, whereas ReMax can afford training. This memory improvement is achieved by removing the value model in PPO. Third, based on our calculations, we find that even assuming PPO can afford the training of Llama2 (7B), it would still run about 2x slower than ReMax. This is due to the computational overhead of the value model, which does not exist in ReMax. Importantly, the above computational improvements do not sacrifice the performance. We hypothesize these advantages can be maintained in larger-scaled models. Our implementation of ReMax is available at https://github.com/liziniu/ReMax