 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Value-Based Reinforcement Learning for Large Language Models
Mar 24, 2026Improving data utilization efficiency is critical for scaling reinforcement learning (RL) for long-horizon tasks where generating trajectories is expensive. However, the dominant RL methods for LLMs are largely on-policy: they update each batch of data only once, discard it, and then collect fresh samples, resulting in poor sample efficiency. In this work, we explore an alternative value-based RL framework for LLMs that naturally enables off-policy learning. We propose ReVal, a Bellman-update-based method that combines stepwise signals capturing internal consistency with trajectory-level signals derived from outcome verification. ReVal naturally supports replay-buffer-based training, allowing efficient reuse of past trajectories. Experiments on standard mathematical reasoning benchmarks show that ReVal not only converges faster but also outperforms GRPO in final performance. On DeepSeek-R1-Distill-1.5B, ReVal improves training efficiency and achieves improvement of 2.7% in AIME24 and 4.5% in out-of-domain benchmark GPQA over GRPO. These results suggest that value-based RL is a practical alternative to policy-based methods for LLM training.
Adam Converges Without Any Modification On Update Rules
Mar 02, 2026Adam is the default algorithm for training neural networks, including large language models (LLMs). However, \citet{reddi2019convergence} provided an example that Adam diverges, raising concerns for its deployment in AI model training. We identify a key mismatch between the divergence example and practice: \citet{reddi2019convergence} pick the problem after picking the hyperparameters of Adam, i.e., $(β_1,β_2)$; while practical applications often fix the problem first and then tune $(β_1,β_2)$. In this work, we prove that Adam converges with proper problem-dependent hyperparameters. First, we prove that Adam converges when $β_2$ is large and $β_1 < \sqrt{β_2}$. Second, when $β_2$ is small, we point out a region of $(β_1,β_2)$ combinations where Adam can diverge to infinity. Our results indicate a phase transition for Adam from divergence to convergence when changing the $(β_1, β_2)$ combination. To our knowledge, this is the first phase transition in $(β_1,β_2)$ 2D-plane reported in the literature, providing rigorous theoretical guarantees for Adam optimizer. We further point out that the critical boundary $(β_1^*, β_2^*)$ is problem-dependent, and particularly, dependent on batch size. This provides suggestions on how to tune $β_1$ and $β_2$: when Adam does not work well, we suggest tuning up $β_2$ inversely with batch size to surpass the threshold $β_2^*$, and then trying $β_1< \sqrt{β_2}$. Our suggestions are supported by reports from several empirical studies, which observe improved LLM training performance when applying them.
ORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
Oct 31, 2025Formulating optimization problems for industrial applications demands significant manual effort and domain expertise. While Large Language Models (LLMs) show promise in automating this process, evaluating their performance remains difficult due to the absence of robust metrics. Existing solver-based approaches often face inconsistency, infeasibility issues, and high computational costs. To address these issues, we propose ORGEval, a graph-theoretic evaluation framework for assessing LLMs' capabilities in formulating linear and mixed-integer linear programs. ORGEval represents optimization models as graphs, reducing equivalence detection to graph isomorphism testing. We identify and prove a sufficient condition, when the tested graphs are symmetric decomposable (SD), under which the Weisfeiler-Lehman (WL) test is guaranteed to correctly detect isomorphism. Building on this, ORGEval integrates a tailored variant of the WL-test with an SD detection algorithm to evaluate model equivalence. By focusing on structural equivalence rather than instance-level configurations, ORGEval is robust to numerical variations. Experimental results show that our method can successfully detect model equivalence and produce 100\% consistent results across random parameter configurations, while significantly outperforming solver-based methods in runtime, especially on difficult problems. Leveraging ORGEval, we construct the Bench4Opt dataset and benchmark state-of-the-art LLMs on optimization modeling. Our results reveal that although optimization modeling remains challenging for all LLMs, DeepSeek-V3 and Claude-Opus-4 achieve the highest accuracies under direct prompting, outperforming even leading reasoning models.
Rethinking Data Mixture for Large Language Models: A Comprehensive Survey and New Perspectives
May 27, 2025Training large language models with data collected from various domains can improve their performance on downstream tasks. However, given a fixed training budget, the sampling proportions of these different domains significantly impact the model's performance. How can we determine the domain weights across different data domains to train the best-performing model within constrained computational resources? In this paper, we provide a comprehensive overview of existing data mixture methods. First, we propose a fine-grained categorization of existing methods, extending beyond the previous offline and online classification. Offline methods are further grouped into heuristic-based, algorithm-based, and function fitting-based methods. For online methods, we categorize them into three groups: online min-max optimization, online mixing law, and other approaches by drawing connections with the optimization frameworks underlying offline methods. Second, we summarize the problem formulations, representative algorithms for each subtype of offline and online methods, and clarify the relationships and distinctions among them. Finally, we discuss the advantages and disadvantages of each method and highlight key challenges in the field of data mixture.
Exploring the Generalization Capabilities of AID-based Bi-level Optimization
Nov 25, 2024Bi-level optimization has achieved considerable success in contemporary machine learning applications, especially for given proper hyperparameters. However, due to the two-level optimization structure, commonly, researchers focus on two types of bi-level optimization methods: approximate implicit differentiation (AID)-based and iterative differentiation (ITD)-based approaches. ITD-based methods can be readily transformed into single-level optimization problems, facilitating the study of their generalization capabilities. In contrast, AID-based methods cannot be easily transformed similarly but must stay in the two-level structure, leaving their generalization properties enigmatic. In this paper, although the outer-level function is nonconvex, we ascertain the uniform stability of AID-based methods, which achieves similar results to a single-level nonconvex problem. We conduct a convergence analysis for a carefully chosen step size to maintain stability. Combining the convergence and stability results, we give the generalization ability of AID-based bi-level optimization methods. Furthermore, we carry out an ablation study of the parameters and assess the performance of these methods on real-world tasks. Our experimental results corroborate the theoretical findings, demonstrating the effectiveness and potential applications of these methods.
Entropic Distribution Matching in Supervised Fine-tuning of LLMs: Less Overfitting and Better Diversity
Aug 29, 2024Large language models rely on Supervised Fine-Tuning (SFT) to specialize in downstream tasks. Cross Entropy (CE) loss is the de facto choice in SFT, but it often leads to overfitting and limited output diversity due to its aggressive updates to the data distribution. This paper aim to address these issues by introducing the maximum entropy principle, which favors models with flatter distributions that still effectively capture the data. Specifically, we develop a new distribution matching method called GEM, which solves reverse Kullback-Leibler divergence minimization with an entropy regularizer. For the SFT of Llama-3-8B models, GEM outperforms CE in several aspects. First, when applied to the UltraFeedback dataset to develop general instruction-following abilities, GEM exhibits reduced overfitting, evidenced by lower perplexity and better performance on the IFEval benchmark. Furthermore, GEM enhances output diversity, leading to performance gains of up to 7 points on math reasoning and code generation tasks using best-of-n sampling, even without domain-specific data. Second, when fine-tuning with domain-specific datasets for math reasoning and code generation, GEM also shows less overfitting and improvements of up to 10 points compared with CE.
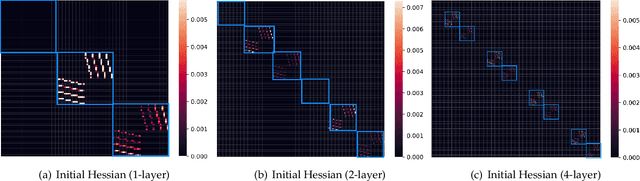
Adam-mini: Use Fewer Learning Rates To Gain More
Jun 26, 2024We propose Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in Adam (i.e., $1/\sqrt{v}$). We find that $\geq$ 90% of these learning rates in $v$ could be harmlessly removed if we (1) carefully partition the parameters into blocks following our proposed principle on Hessian structure; (2) assign a single but good learning rate to each parameter block. We further find that, for each of these parameter blocks, there exists a single high-quality learning rate that can outperform Adam, provided that sufficient resources are available to search it out. We then provide one cost-effective way to find good learning rates and propose Adam-mini. Empirically, we verify that Adam-mini performs on par or better than AdamW on various language models sized from 125M to 7B for pre-training, supervised fine-tuning, and RLHF. The reduced memory footprint of Adam-mini also alleviates communication overheads among GPUs and CPUs, thereby increasing throughput. For instance, Adam-mini achieves 49.6% higher throughput than AdamW when pre-training Llama2-7B on $2\times$ A800-80GB GPUs, which saves 33% wall-clock time for pre-training.
Why Transformers Need Adam: A Hessian Perspective
Feb 26, 2024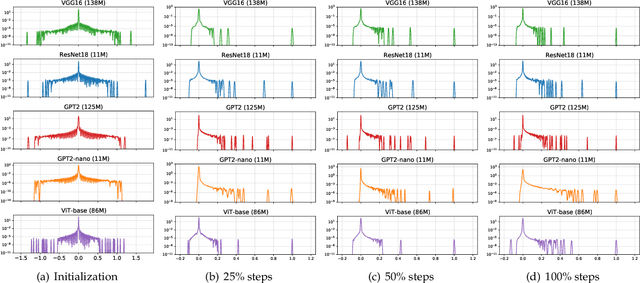

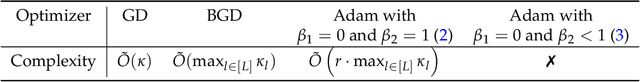
SGD performs worse than Adam by a significant margin on Transformers, but the reason remains unclear. In this work, we provide an explanation of SGD's failure on Transformers through the lens of Hessian: (i) Transformers are ``heterogeneous'': the Hessian spectrum across parameter blocks vary dramatically, a phenomenon we call ``block heterogeneity"; (ii) Heterogeneity hampers SGD: SGD performs badly on problems with block heterogeneity. To validate that heterogeneity hampers SGD, we check various Transformers, CNNs, MLPs, and quadratic problems, and find that SGD works well on problems without block heterogeneity but performs badly when the heterogeneity exists. Our initial theoretical analysis indicates that SGD fails because it applies one single learning rate for all blocks, which cannot handle the heterogeneity among blocks. The failure could be rescued if we could assign different learning rates across blocks, as designed in Adam.
Rethinking SIGN Training: Provable Nonconvex Acceleration without First- and Second-Order Gradient Lipschitz
Oct 23, 2023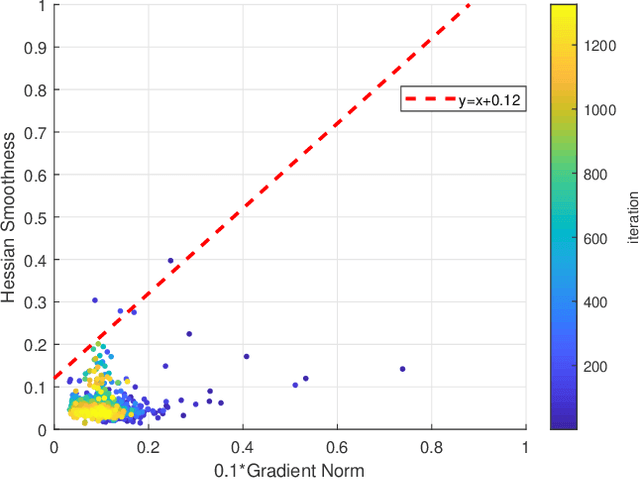
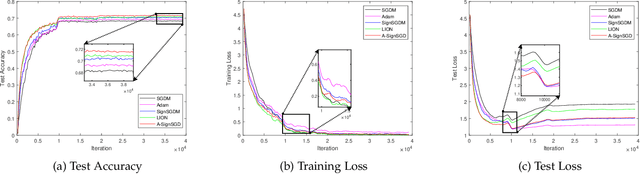
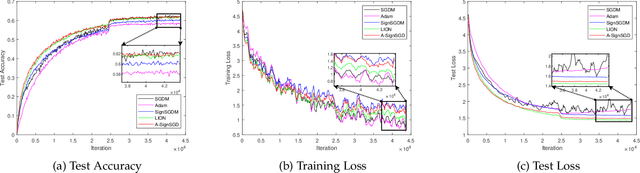
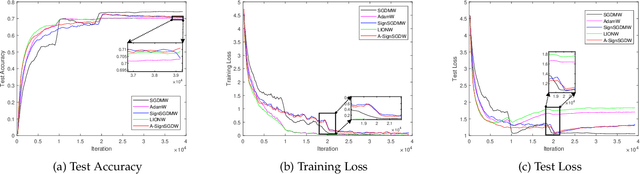
Sign-based stochastic methods have gained attention due to their ability to achieve robust performance despite using only the sign information for parameter updates. However, the current convergence analysis of sign-based methods relies on the strong assumptions of first-order gradient Lipschitz and second-order gradient Lipschitz, which may not hold in practical tasks like deep neural network training that involve high non-smoothness. In this paper, we revisit sign-based methods and analyze their convergence under more realistic assumptions of first- and second-order smoothness. We first establish the convergence of the sign-based method under weak first-order Lipschitz. Motivated by the weak first-order Lipschitz, we propose a relaxed second-order condition that still allows for nonconvex acceleration in sign-based methods. Based on our theoretical results, we gain insights into the computational advantages of the recently developed LION algorithm. In distributed settings, we prove that this nonconvex acceleration persists with linear speedup in the number of nodes, when utilizing fast communication compression gossip protocols. The novelty of our theoretical results lies in that they are derived under much weaker assumptions, thereby expanding the provable applicability of sign-based algorithms to a wider range of problems.
Adam Can Converge Without Any Modification on Update Rules
Aug 23, 2022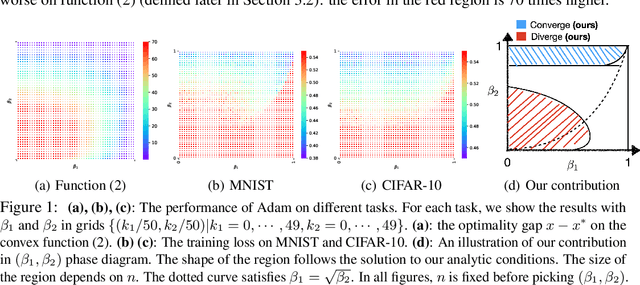

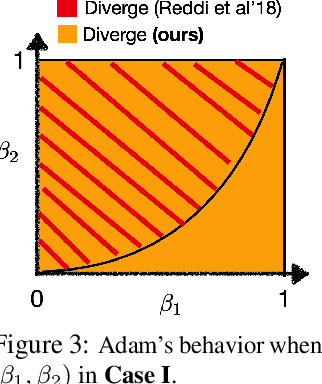
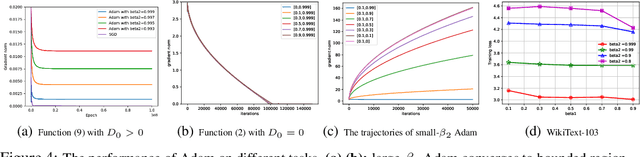
Ever since Reddi et al. 2018 pointed out the divergence issue of Adam, many new variants have been designed to obtain convergence. However, vanilla Adam remains exceptionally popular and it works well in practice. Why is there a gap between theory and practice? We point out there is a mismatch between the settings of theory and practice: Reddi et al. 2018 pick the problem after picking the hyperparameters of Adam, i.e., $(\beta_1, \beta_2)$; while practical applications often fix the problem first and then tune $(\beta_1, \beta_2)$. Due to this observation, we conjecture that the empirical convergence can be theoretically justified, only if we change the order of picking the problem and hyperparameter. In this work, we confirm this conjecture. We prove that, when $\beta_2$ is large and $\beta_1 < \sqrt{\beta_2}<1$, Adam converges to the neighborhood of critical points. The size of the neighborhood is propositional to the variance of stochastic gradients. Under an extra condition (strong growth condition), Adam converges to critical points. As $\beta_2$ increases, our convergence result can cover any $\beta_1 \in [0,1)$ including $\beta_1=0.9$, which is the default setting in deep learning libraries. To our knowledge, this is the first result showing that Adam can converge under a wide range of hyperparameters {\it without any modification} on its update rules. Further, our analysis does not require assumptions of bounded gradients or bounded 2nd-order momentum. When $\beta_2$ is small, we further point out a large region of $(\beta_1,\beta_2)$ where Adam can diverge to infinity. Our divergence result considers the same setting as our convergence result, indicating a phase transition from divergence to convergence when increasing $\beta_2$. These positive and negative results can provide suggestions on how to tune Adam hyperparameters.