 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam Can Converge Without Any Modification on Update Rules
Paper and Code
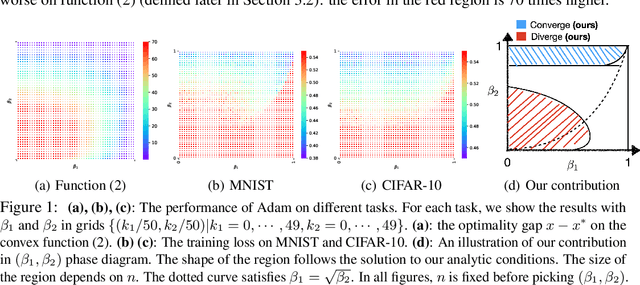

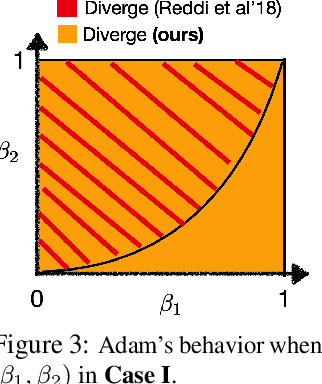
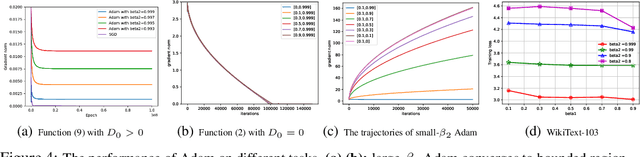
Ever since Reddi et al. 2018 pointed out the divergence issue of Adam, many new variants have been designed to obtain convergence. However, vanilla Adam remains exceptionally popular and it works well in practice. Why is there a gap between theory and practice? We point out there is a mismatch between the settings of theory and practice: Reddi et al. 2018 pick the problem after picking the hyperparameters of Adam, i.e., $(\beta_1, \beta_2)$; while practical applications often fix the problem first and then tune $(\beta_1, \beta_2)$. Due to this observation, we conjecture that the empirical convergence can be theoretically justified, only if we change the order of picking the problem and hyperparameter. In this work, we confirm this conjecture. We prove that, when $\beta_2$ is large and $\beta_1 < \sqrt{\beta_2}<1$, Adam converges to the neighborhood of critical points. The size of the neighborhood is propositional to the variance of stochastic gradients. Under an extra condition (strong growth condition), Adam converges to critical points. As $\beta_2$ increases, our convergence result can cover any $\beta_1 \in [0,1)$ including $\beta_1=0.9$, which is the default setting in deep learning libraries. To our knowledge, this is the first result showing that Adam can converge under a wide range of hyperparameters {\it without any modification} on its update rules. Further, our analysis does not require assumptions of bounded gradients or bounded 2nd-order momentum. When $\beta_2$ is small, we further point out a large region of $(\beta_1,\beta_2)$ where Adam can diverge to infinity. Our divergence result considers the same setting as our convergence result, indicating a phase transition from divergence to convergence when increasing $\beta_2$. These positive and negative results can provide suggestions on how to tune Adam hyperparameters.