 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVAFM: Re-parameterizing Vertical Attention Fusion Module for Handwritten Paragraph Text Recognition
Mar 05, 2025



Handwritten Paragraph Text Recognition (HPTR) is a challenging task in Computer Vision, requiring the transformation of a paragraph text image, rich in handwritten text, into text encoding sequences. One of the most advanced models for this task is Vertical Attention Network (VAN), which utilizes a Vertical Attention Module (VAM) to implicitly segment paragraph text images into text lines, thereby reducing the difficulty of the recognition task. However, from a network structure perspective, VAM is a single-branch module, which is less effective in learning compared to multi-branch modules. In this paper, we propose a new module, named Re-parameterizing Vertical Attention Fusion Module (RVAFM), which incorporates structural re-parameterization techniques. RVAFM decouples the structure of the module during training and inference stages. During training, it uses a multi-branch structure for more effective learning, and during inference, it uses a single-branch structure for faster processing. The features learned by the multi-branch structure are fused into the single-branch structure through a special fusion method named Re-parameterization Fusion (RF) without any loss of information. As a result, we achieve a Character Error Rate (CER) of 4.44% and a Word Error Rate (WER) of 14.37% on the IAM paragraph-level test set. Additionally, the inference speed is slightly faster than VAN.
Enhancing Expressiveness in Dance Generation via Integrating Frequency and Music Style Information
Mar 09, 2024



Dance generation, as a branch of human motion generation, has attracted increasing attention. Recently, a few works attempt to enhance dance expressiveness, which includes genre matching, beat alignment, and dance dynamics, from certain aspects. However, the enhancement is quite limited as they lack comprehensive consideration of the aforementioned three factors. In this paper, we propose ExpressiveBailando, a novel dance generation method designed to generate expressive dances, concurrently taking all three factors into account. Specifically, we mitigate the issue of speed homogenization by incorporating frequency information into VQ-VAE, thus improving dance dynamics. Additionally, we integrate music style information by extracting genre- and beat-related features with a pre-trained music model, hence achieving improvements in the other two factors. Extensive experimental results demonstrate that our proposed method can generate dances with high expressiveness and outperforms existing methods both qualitatively and quantitatively.
AdaMesh: Personalized Facial Expressions and Head Poses for Speech-Driven 3D Facial Animation
Oct 11, 2023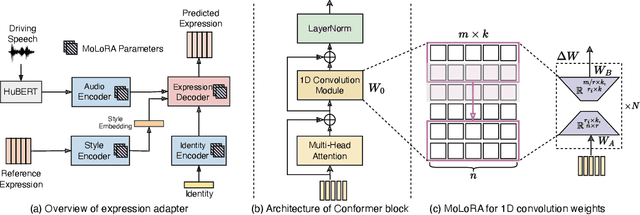
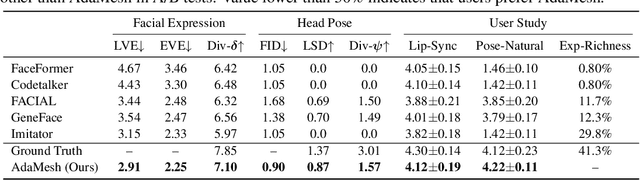
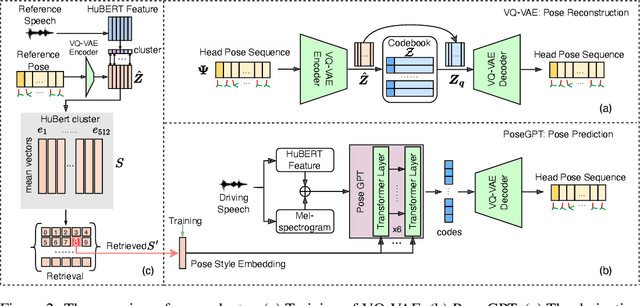

Speech-driven 3D facial animation aims at generating facial movements that are synchronized with the driving speech, which has been widely explored recently. Existing works mostly neglect the person-specific talking style in generation, including facial expression and head pose styles. Several works intend to capture the personalities by fine-tuning modules. However, limited training data leads to the lack of vividness. In this work, we propose AdaMesh, a novel adaptive speech-driven facial animation approach, which learns the personalized talking style from a reference video of about 10 seconds and generates vivid facial expressions and head poses. Specifically, we propose mixture-of-low-rank adaptation (MoLoRA) to fine-tune the expression adapter, which efficiently captures the facial expression style. For the personalized pose style, we propose a pose adapter by building a discrete pose prior and retrieving the appropriate style embedding with a semantic-aware pose style matrix without fine-tuning. Extensive experimental results show that our approach outperforms state-of-the-art methods, preserves the talking style in the reference video, and generates vivid facial animation. The supplementary video and code will be available at https://adamesh.github.io.
End-to-End Adaptive Monte Carlo Denoising and Super-Resolution
Aug 16, 2021
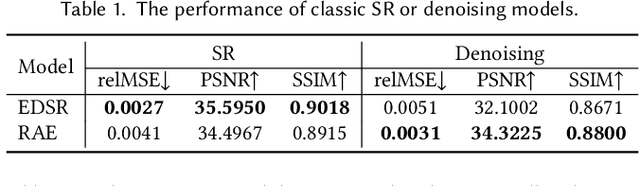
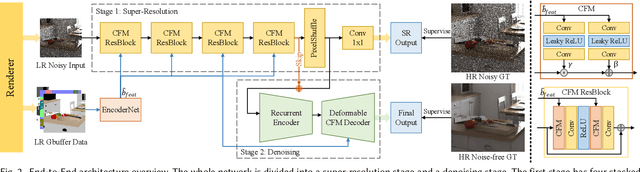
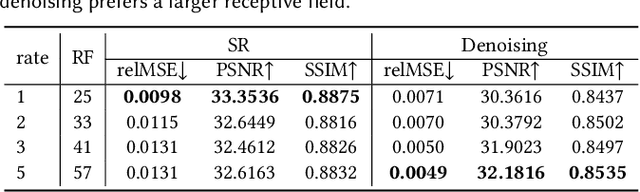
The classic Monte Carlo path tracing can achieve high quality rendering at the cost of heavy computation. Recent works make use of deep neural networks to accelerate this process, by improving either low-resolution or fewer-sample rendering with super-resolution or denoising neural networks in post-processing. However, denoising and super-resolution have only been considered separately in previous work. We show in this work that Monte Carlo path tracing can be further accelerated by joint super-resolution and denoising (SRD) in post-processing. This new type of joint filtering allows only a low-resolution and fewer-sample (thus noisy) image to be rendered by path tracing, which is then fed into a deep neural network to produce a high-resolution and clean image. The main contribution of this work is a new end-to-end network architecture, specifically designed for the SRD task. It contains two cascaded stages with shared components. We discover that denoising and super-resolution require very different receptive fields, a key insight that leads to the introduction of deformable convolution into the network design. Extensive experiments show that the proposed method outperforms previous methods and their variants adopted for the SRD task.
UniFaceGAN: A Unified Framework for Temporally Consistent Facial Video Editing
Aug 12, 2021



Recent research has witnessed advances in facial image editing tasks including face swapping and face reenactment. However, these methods are confined to dealing with one specific task at a time. In addition, for video facial editing, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In this paper, we propose a unified temporally consistent facial video editing framework termed UniFaceGAN. Based on a 3D reconstruction model and a simple yet efficient dynamic training sample selection mechanism, our framework is designed to handle face swapping and face reenactment simultaneously. To enforce the temporal consistency, a novel 3D temporal loss constraint is introduced based on the barycentric coordinate interpolation. Besides, we propose a region-aware conditional normalization layer to replace the traditional AdaIN or SPADE to synthesize more context-harmonious results. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Lightweight Image Super-Resolution with Hierarchical and Differentiable Neural Architecture Search
May 09, 2021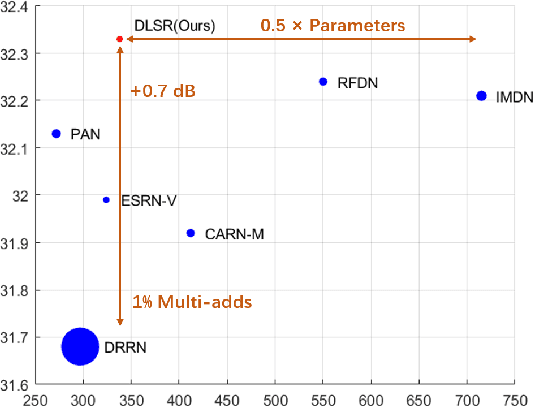
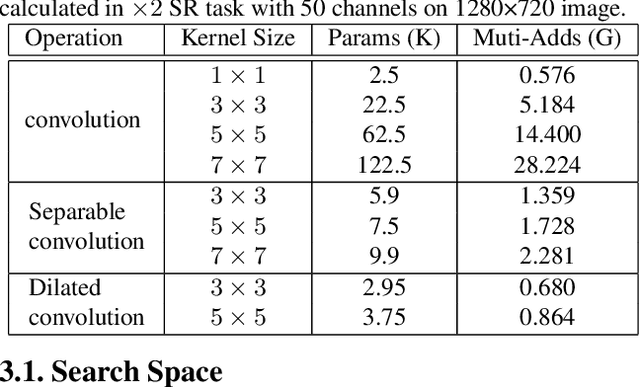
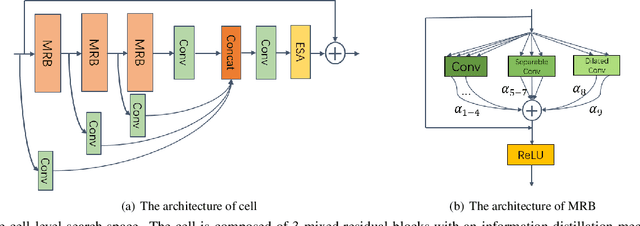
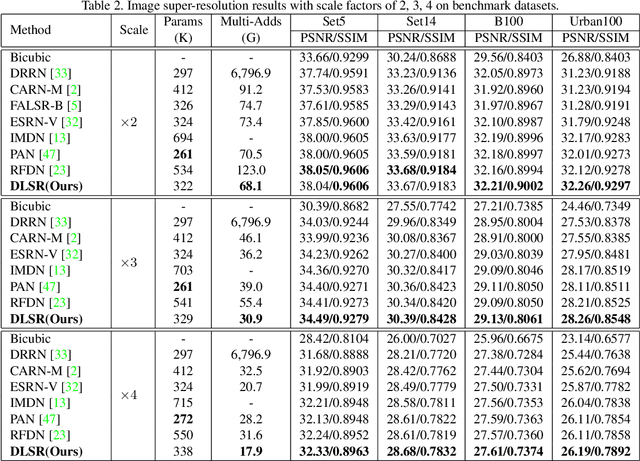
Single Image Super-Resolution (SISR) tasks have achieved significant performance with deep neural networks. However, the large number of parameters in CNN-based methods for SISR tasks require heavy computations. Although several efficient SISR models have been recently proposed, most are handcrafted and thus lack flexibility. In this work, we propose a novel differentiable Neural Architecture Search (NAS) approach on both the cell-level and network-level to search for lightweight SISR models. Specifically, the cell-level search space is designed based on an information distillation mechanism, focusing on the combinations of lightweight operations and aiming to build a more lightweight and accurate SR structure. The network-level search space is designed to consider the feature connections among the cells and aims to find which information flow benefits the cell most to boost the performance. Unlike the existing Reinforcement Learning (RL) or Evolutionary Algorithm (EA) based NAS methods for SISR tasks, our search pipeline is fully differentiable, and the lightweight SISR models can be efficiently searched on both the cell-level and network-level jointly on a single GPU. Experiments show that our methods can achieve state-of-the-art performance on the benchmark datasets in terms of PSNR, SSIM, and model complexity with merely 68G Multi-Adds for $\times 2$ and 18G Multi-Adds for $\times 4$ SR tasks. Code will be available at \url{https://github.com/DawnHH/DLSR-PyTorch}.
Two-Stage Monte Carlo Denoising with Adaptive Sampling and Kernel Pool
Mar 30, 2021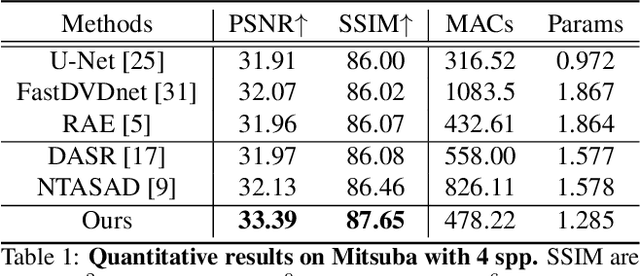
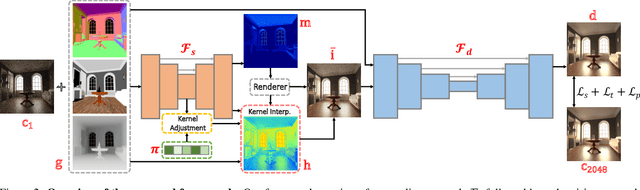
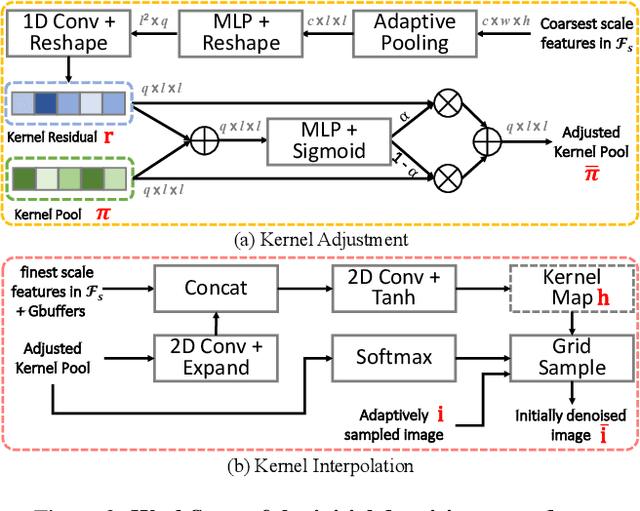

Monte Carlo path tracer renders noisy image sequences at low sampling counts. Although great progress has been made on denoising such sequences, existing methods still suffer from spatial and temporary artifacts. In this paper, we tackle the problems in Monte Carlo rendering by proposing a two-stage denoiser based on the adaptive sampling strategy. In the first stage, concurrent to adjusting samples per pixel (spp) on-the-fly, we reuse the computations to generate extra denoising kernels applying on the adaptively rendered image. Rather than a direct prediction of pixel-wise kernels, we save the overhead complexity by interpolating such kernels from a public kernel pool, which can be dynamically updated to fit input signals. In the second stage, we design the position-aware pooling and semantic alignment operators to improve spatial-temporal stability. Our method was first benchmarked on 10 synthesized scenes rendered from the Mitsuba renderer and then validated on 3 additional scenes rendered from our self-built RTX-based renderer. Our method outperforms state-of-the-art counterparts in terms of both numerical error and visual quality.
Task-agnostic Temporally Consistent Facial Video Editing
Jul 03, 2020
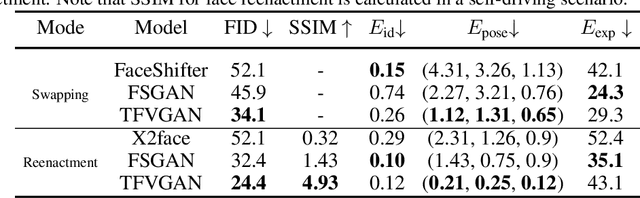
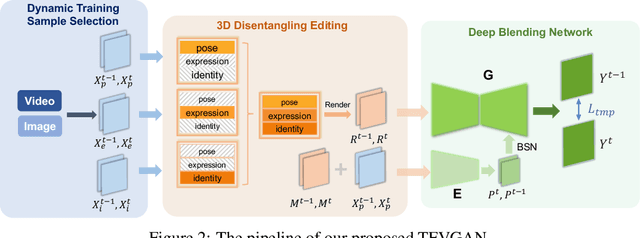
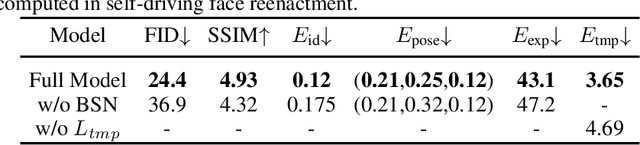
Recent research has witnessed the advances in facial image editing tasks. For video editing, however, previous methods either simply apply transformations frame by frame or utilize multiple frames in a concatenated or iterative fashion, which leads to noticeable visual flickers. In addition, these methods are confined to dealing with one specific task at a time without any extensibility. In this paper, we propose a task-agnostic temporally consistent facial video editing framework. Based on a 3D reconstruction model, our framework is designed to handle several editing tasks in a more unified and disentangled manner. The core design includes a dynamic training sample selection mechanism and a novel 3D temporal loss constraint that fully exploits both image and video datasets and enforces temporal consistency. Compared with the state-of-the-art facial image editing methods, our framework generates video portraits that are more photo-realistic and temporally smooth.
Real-time Universal Style Transfer on High-resolution Images via Zero-channel Pruning
Jun 23, 2020
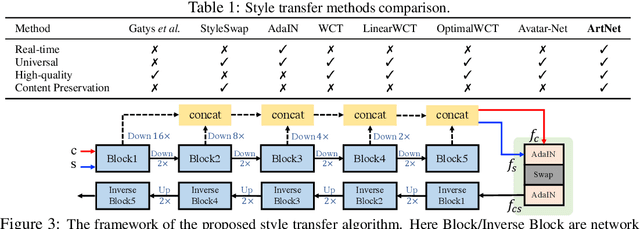


Extracting effective deep features to represent content and style information is the key to universal style transfer. Most existing algorithms use VGG19 as the feature extractor, which incurs a high computational cost and impedes real-time style transfer on high-resolution images. In this work, we propose a lightweight alternative architecture - ArtNet, which is based on GoogLeNet, and later pruned by a novel channel pruning method named Zero-channel Pruning specially designed for style transfer approaches. Besides, we propose a theoretically sound sandwich swap transform (S2) module to transfer deep features, which can create a pleasing holistic appearance and good local textures with an improved content preservation ability. By using ArtNet and S2, our method is 2.3 to 107.4 times faster than state-of-the-art approaches. The comprehensive experiments demonstrate that ArtNet can achieve universal, real-time, and high-quality style transfer on high-resolution images simultaneously, (68.03 FPS on 512 times 512 images).
Quantized Adam with Error Feedback
Apr 29, 2020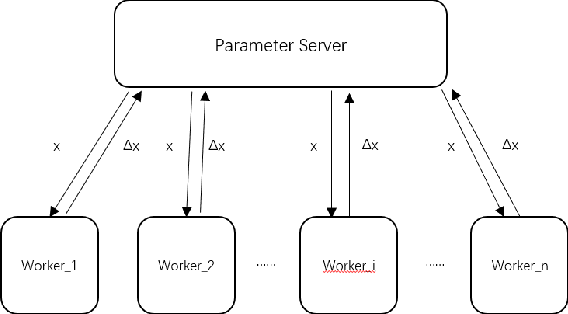
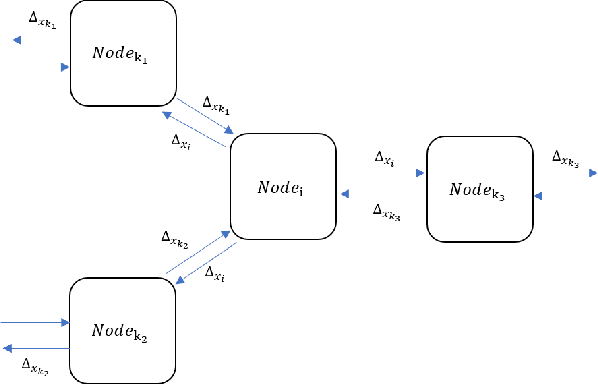
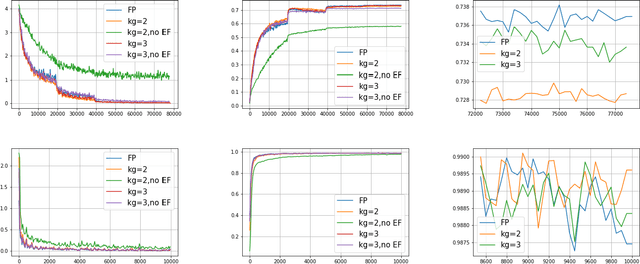
In this paper, we present a distributed variant of adaptive stochastic gradient method for training deep neural networks in the parameter-server model. To reduce the communication cost among the workers and server, we incorporate two types of quantization schemes, i.e., gradient quantization and weight quantization, into the proposed distributed Adam. Besides, to reduce the bias introduced by quantization operations, we propose an error-feedback technique to compensate for the quantized gradient. Theoretically, in the stochastic nonconvex setting, we show that the distributed adaptive gradient method with gradient quantization and error-feedback converges to the first-order stationary point, and that the distributed adaptive gradient method with weight quantization and error-feedback converges to the point related to the quantized level under both the single-worker and multi-worker modes. At last, we apply the proposed distributed adaptive gradient methods to train deep neural networks. Experimental results demonstrate the efficacy of our methods.