 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Adaptive Monte Carlo Denoising and Super-Resolution
Aug 16, 2021
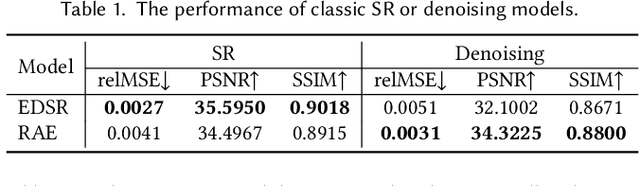
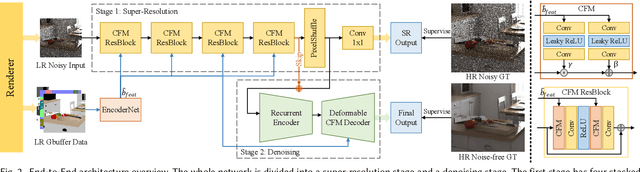
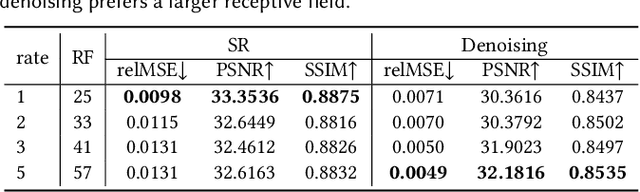
The classic Monte Carlo path tracing can achieve high quality rendering at the cost of heavy computation. Recent works make use of deep neural networks to accelerate this process, by improving either low-resolution or fewer-sample rendering with super-resolution or denoising neural networks in post-processing. However, denoising and super-resolution have only been considered separately in previous work. We show in this work that Monte Carlo path tracing can be further accelerated by joint super-resolution and denoising (SRD) in post-processing. This new type of joint filtering allows only a low-resolution and fewer-sample (thus noisy) image to be rendered by path tracing, which is then fed into a deep neural network to produce a high-resolution and clean image. The main contribution of this work is a new end-to-end network architecture, specifically designed for the SRD task. It contains two cascaded stages with shared components. We discover that denoising and super-resolution require very different receptive fields, a key insight that leads to the introduction of deformable convolution into the network design. Extensive experiments show that the proposed method outperforms previous methods and their variants adopted for the SRD task.
Two-Stage Monte Carlo Denoising with Adaptive Sampling and Kernel Pool
Mar 30, 2021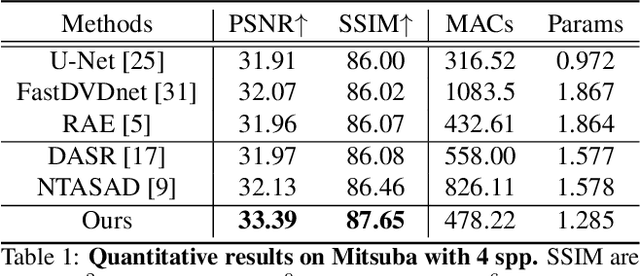
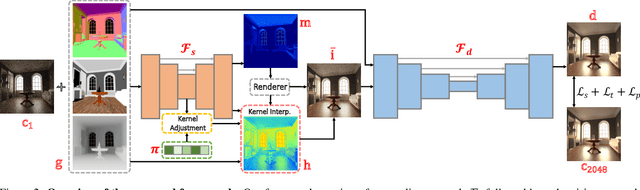
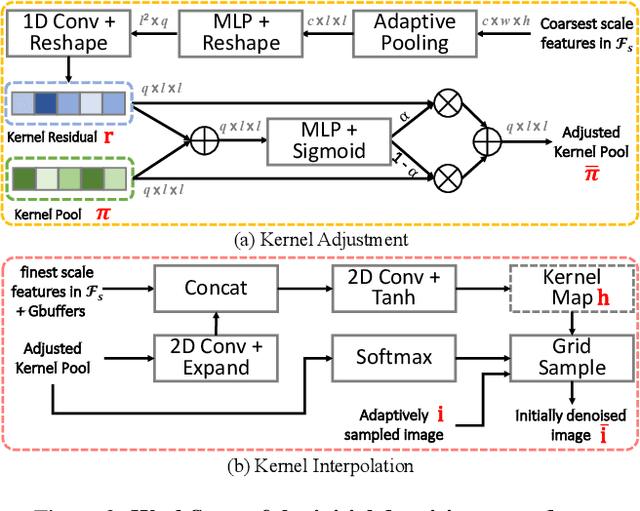

Monte Carlo path tracer renders noisy image sequences at low sampling counts. Although great progress has been made on denoising such sequences, existing methods still suffer from spatial and temporary artifacts. In this paper, we tackle the problems in Monte Carlo rendering by proposing a two-stage denoiser based on the adaptive sampling strategy. In the first stage, concurrent to adjusting samples per pixel (spp) on-the-fly, we reuse the computations to generate extra denoising kernels applying on the adaptively rendered image. Rather than a direct prediction of pixel-wise kernels, we save the overhead complexity by interpolating such kernels from a public kernel pool, which can be dynamically updated to fit input signals. In the second stage, we design the position-aware pooling and semantic alignment operators to improve spatial-temporal stability. Our method was first benchmarked on 10 synthesized scenes rendered from the Mitsuba renderer and then validated on 3 additional scenes rendered from our self-built RTX-based renderer. Our method outperforms state-of-the-art counterparts in terms of both numerical error and visual quality.