 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridSplat: Fast Reflection-baked Gaussian Tracing using Hybrid Splatting
Dec 15, 2025
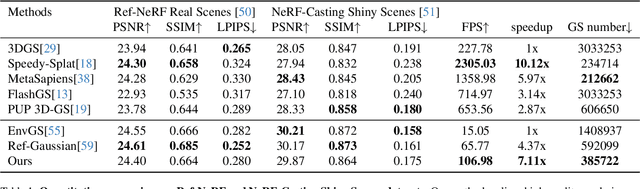


Rendering complex reflection of real-world scenes using 3D Gaussian splatting has been a quite promising solution for photorealistic novel view synthesis, but still faces bottlenecks especially in rendering speed and memory storage. This paper proposes a new Hybrid Splatting(HybridSplat) mechanism for Gaussian primitives. Our key idea is a new reflection-baked Gaussian tracing, which bakes the view-dependent reflection within each Gaussian primitive while rendering the reflection using tile-based Gaussian splatting. Then we integrate the reflective Gaussian primitives with base Gaussian primitives using a unified hybrid splatting framework for high-fidelity scene reconstruction. Moreover, we further introduce a pipeline-level acceleration for the hybrid splatting, and reflection-sensitive Gaussian pruning to reduce the model size, thus achieving much faster rendering speed and lower memory storage while preserving the reflection rendering quality. By extensive evaluation, our HybridSplat accelerates about 7x rendering speed across complex reflective scenes from Ref-NeRF, NeRF-Casting with 4x fewer Gaussian primitives than similar ray-tracing based Gaussian splatting baselines, serving as a new state-of-the-art method especially for complex reflective scenes.
High-Quality Supersampling via Mask-reinforced Deep Learning for Real-time Rendering
Jan 03, 2023To generate high quality rendering images for real time applications, it is often to trace only a few samples-per-pixel (spp) at a lower resolution and then supersample to the high resolution. Based on the observation that the rendered pixels at a low resolution are typically highly aliased, we present a novel method for neural supersampling based on ray tracing 1/4-spp samples at the high resolution. Our key insight is that the ray-traced samples at the target resolution are accurate and reliable, which makes the supersampling an interpolation problem. We present a mask-reinforced neural network to reconstruct and interpolate high-quality image sequences. First, a novel temporal accumulation network is introduced to compute the correlation between current and previous features to significantly improve their temporal stability. Then a reconstruct network based on a multi-scale U-Net with skip connections is adopted for reconstruction and generation of the desired high-resolution image. Experimental results and comparisons have shown that our proposed method can generate higher quality results of supersampling, without increasing the total number of ray-tracing samples, over current state-of-the-art methods.
End-to-End Adaptive Monte Carlo Denoising and Super-Resolution
Aug 16, 2021
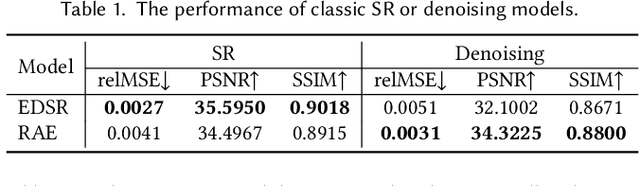
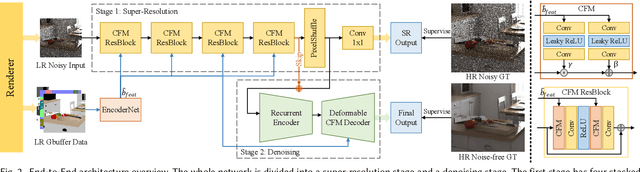
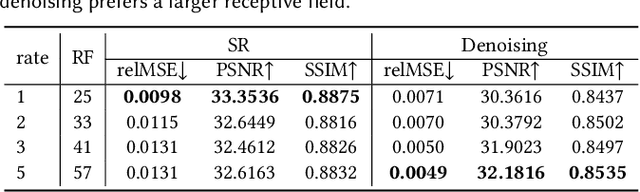
The classic Monte Carlo path tracing can achieve high quality rendering at the cost of heavy computation. Recent works make use of deep neural networks to accelerate this process, by improving either low-resolution or fewer-sample rendering with super-resolution or denoising neural networks in post-processing. However, denoising and super-resolution have only been considered separately in previous work. We show in this work that Monte Carlo path tracing can be further accelerated by joint super-resolution and denoising (SRD) in post-processing. This new type of joint filtering allows only a low-resolution and fewer-sample (thus noisy) image to be rendered by path tracing, which is then fed into a deep neural network to produce a high-resolution and clean image. The main contribution of this work is a new end-to-end network architecture, specifically designed for the SRD task. It contains two cascaded stages with shared components. We discover that denoising and super-resolution require very different receptive fields, a key insight that leads to the introduction of deformable convolution into the network design. Extensive experiments show that the proposed method outperforms previous methods and their variants adopted for the SRD task.
Partial Graph Reasoning for Neural Network Regularization
Jun 03, 2021
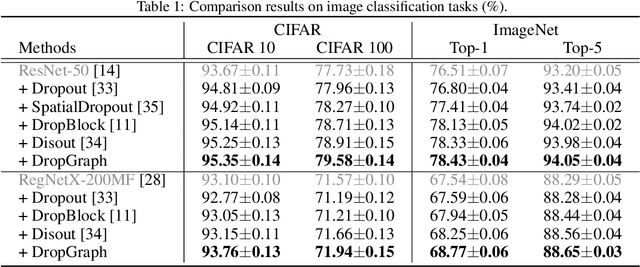
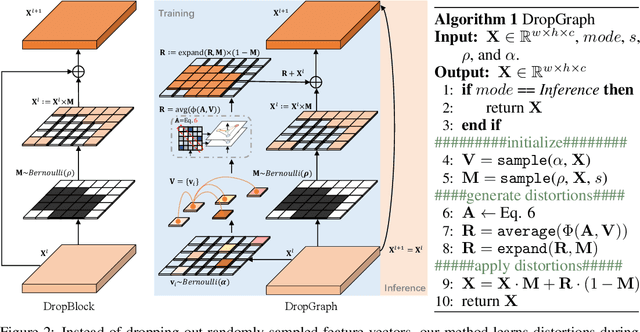
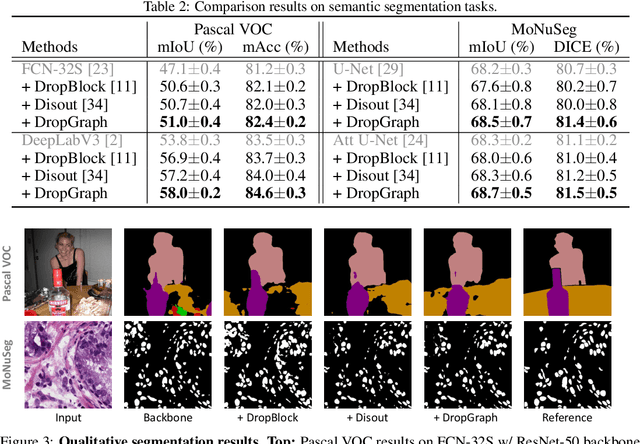
Regularizers helped deep neural networks prevent feature co-adaptations. Dropout,as a commonly used regularization technique, stochastically disables neuron ac-tivations during network optimization. However, such complete feature disposal can affect the feature representation and network understanding. Toward betterdescriptions of latent representations, we present DropGraph that learns regularization function by constructing a stand-alone graph from the backbone features. DropGraph first samples stochastic spatial feature vectors and then incorporates graph reasoning methods to generate feature map distortions. This add-on graph regularizes the network during training and can be completely skipped during inference. We provide intuitions on the linkage between graph reasoning andDropout with further discussions on how partial graph reasoning method reduces feature correlations. To this end, we extensively study the modeling of graphvertex dependencies and the utilization of the graph for distorting backbone featuremaps. DropGraph was validated on four tasks with a total of 7 different datasets.The experimental results show that our method outperforms other state-of-the-art regularizers while leaving the base model structure unmodified during inference.
Two-Stage Monte Carlo Denoising with Adaptive Sampling and Kernel Pool
Mar 30, 2021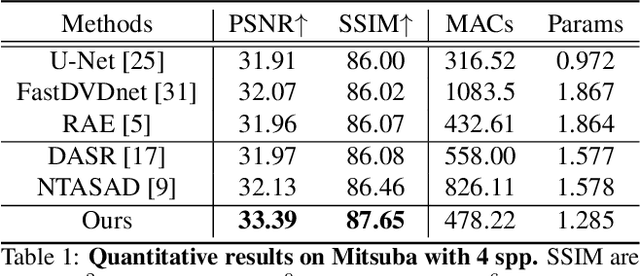
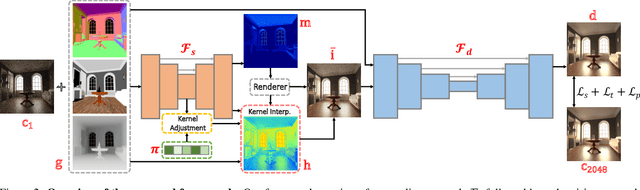
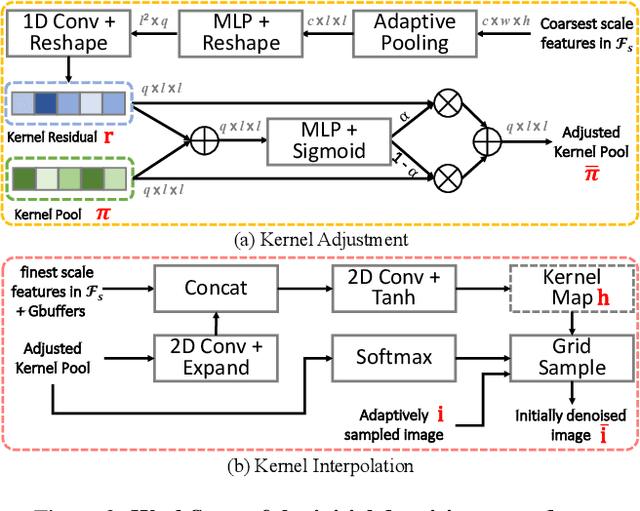

Monte Carlo path tracer renders noisy image sequences at low sampling counts. Although great progress has been made on denoising such sequences, existing methods still suffer from spatial and temporary artifacts. In this paper, we tackle the problems in Monte Carlo rendering by proposing a two-stage denoiser based on the adaptive sampling strategy. In the first stage, concurrent to adjusting samples per pixel (spp) on-the-fly, we reuse the computations to generate extra denoising kernels applying on the adaptively rendered image. Rather than a direct prediction of pixel-wise kernels, we save the overhead complexity by interpolating such kernels from a public kernel pool, which can be dynamically updated to fit input signals. In the second stage, we design the position-aware pooling and semantic alignment operators to improve spatial-temporal stability. Our method was first benchmarked on 10 synthesized scenes rendered from the Mitsuba renderer and then validated on 3 additional scenes rendered from our self-built RTX-based renderer. Our method outperforms state-of-the-art counterparts in terms of both numerical error and visual quality.