 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCo-SAM3: Harnessing Concept Conflict in Open-Vocabulary Semantic Segmentation
Apr 21, 2026SAM3 advances open-vocabulary semantic segmentation by introducing a prompt-driven mask generation paradigm. However, in multi-class open-vocabulary scenarios, masks generated independently from different category prompts lack a unified and inter-class comparable evidence scale, often resulting in overlapping coverage and unstable competition. Moreover, synonymous expressions of the same concept tend to activate inconsistent semantic and spatial evidence, leading to intra-class drift that exacerbates inter-class conflicts and compromises overall inference stability. To address these issues, we propose CoCo-SAM3 (Concept-Conflict SAM3), which explicitly decouples inference into intra-class enhancement and inter-class competition. Our method first aligns and aggregates evidence from synonymous prompts to strengthen concept consistency. It then performs inter-class competition on a unified comparable scale, enabling direct pixel-wise comparisons among all candidate classes. This mechanism stabilizes multi-class inference and effectively mitigates inter-class conflicts. Without requiring any additional training, CoCo-SAM3 achieves consistent improvements across eight open-vocabulary semantic segmentation benchmarks.
Video-Only ToM: Enhancing Theory of Mind in Multimodal Large Language Models
Mar 25, 2026As large language models (LLMs) continue to advance, there is increasing interest in their ability to infer human mental states and demonstrate a human-like Theory of Mind (ToM). Most existing ToM evaluations, however, are centered on text-based inputs, while scenarios relying solely on visual information receive far less attention. This leaves a gap, since real-world human-AI interaction typically requires multimodal understanding. In addition, many current methods regard the model as a black box and rarely probe how its internal attention behaves in multiple-choice question answering (QA). The impact of LLM hallucinations on such tasks is also underexplored from an interpretability perspective. To address these issues, we introduce VisionToM, a vision-oriented intervention framework designed to strengthen task-aware reasoning. The core idea is to compute intervention vectors that align visual representations with the correct semantic targets, thereby steering the model's attention through different layers of visual features. This guidance reduces the model's reliance on spurious linguistic priors, leading to more reliable multimodal language model (MLLM) outputs and better QA performance. Experiments on the EgoToM benchmark-an egocentric, real-world video dataset for ToM with three multiple-choice QA settings-demonstrate that our method substantially improves the ToM abilities of MLLMs. Furthermore, results on an additional open-ended generation task show that VisionToM enables MLLMs to produce free-form explanations that more accurately capture agents' mental states, pushing machine-human collaboration toward greater alignment.
LEDA: Latent Semantic Distribution Alignment for Multi-domain Graph Pre-training
Feb 26, 2026Recent advances in generic large models, such as GPT and DeepSeek, have motivated the introduction of universality to graph pre-training, aiming to learn rich and generalizable knowledge across diverse domains using graph representations to improve performance in various downstream applications. However, most existing methods face challenges in learning effective knowledge from generic graphs, primarily due to simplistic data alignment and limited training guidance. The issue of simplistic data alignment arises from the use of a straightforward unification for highly diverse graph data, which fails to align semantics and misleads pre-training models. The problem with limited training guidance lies in the arbitrary application of in-domain pre-training paradigms to cross-domain scenarios. While it is effective in enhancing discriminative representation in one data space, it struggles to capture effective knowledge from many graphs. To address these challenges, we propose a novel Latent sEmantic Distribution Alignment (LEDA) model for universal graph pre-training. Specifically, we first introduce a dimension projection unit to adaptively align diverse domain features into a shared semantic space with minimal information loss. Furthermore, we design a variational semantic inference module to obtain the shared latent distribution. The distribution is then adopted to guide the domain projection, aligning it with shared semantics across domains and ensuring cross-domain semantic learning. LEDA exhibits strong performance across a broad range of graphs and downstream tasks. Remarkably, in few-shot cross-domain settings, it significantly outperforms in-domain baselines and advanced universal pre-training models.
Mixed Magnification Aggregation for Generalizable Region-Level Representations in Computational Pathology
Feb 25, 2026In recent years, a standard computational pathology workflow has emerged where whole slide images are cropped into tiles, these tiles are processed using a foundation model, and task-specific models are built using the resulting representations. At least 15 different foundation models have been proposed, and the vast majority are trained exclusively with tiles using the 20$\times$ magnification. However, it is well known that certain histologic features can only be discerned with larger context windows and requires a pathologist to zoom in and out when analyzing a whole slide image. Furthermore, creating 224$\times$224 pixel crops at 20$\times$ leads to a large number of tiles per slide, which can be gigapixel in size. To more accurately capture multi-resolution features and investigate the possibility of reducing the number of representations per slide, we propose a region-level mixing encoder. Our approach jointly fuses image tile representations of a mixed magnification foundation model using a masked embedding modeling pretraining step. We explore a design space for pretraining the proposed mixed-magnification region aggregators and evaluate our models on transfer to biomarker prediction tasks representing various cancer types. Results demonstrate cancer dependent improvements in predictive performance, highlighting the importance of spatial context and understanding.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
PALUM: Part-based Attention Learning for Unified Motion Retargeting
Jan 12, 2026Retargeting motion between characters with different skeleton structures is a fundamental challenge in computer animation. When source and target characters have vastly different bone arrangements, maintaining the original motion's semantics and quality becomes increasingly difficult. We present PALUM, a novel approach that learns common motion representations across diverse skeleton topologies by partitioning joints into semantic body parts and applying attention mechanisms to capture spatio-temporal relationships. Our method transfers motion to target skeletons by leveraging these skeleton-agnostic representations alongside target-specific structural information. To ensure robust learning and preserve motion fidelity, we introduce a cycle consistency mechanism that maintains semantic coherence throughout the retargeting process. Extensive experiments demonstrate superior performance in handling diverse skeletal structures while maintaining motion realism and semantic fidelity, even when generalizing to previously unseen skeleton-motion combinations. We will make our implementation publicly available to support future research.
GraphMMP: A Graph Neural Network Model with Mutual Information and Global Fusion for Multimodal Medical Prognosis
Aug 24, 2025In the field of multimodal medical data analysis, leveraging diverse types of data and understanding their hidden relationships continues to be a research focus. The main challenges lie in effectively modeling the complex interactions between heterogeneous data modalities with distinct characteristics while capturing both local and global dependencies across modalities. To address these challenges, this paper presents a two-stage multimodal prognosis model, GraphMMP, which is based on graph neural networks. The proposed model constructs feature graphs using mutual information and features a global fusion module built on Mamba, which significantly boosts prognosis performance. Empirical results show that GraphMMP surpasses existing methods on datasets related to liver prognosis and the METABRIC study, demonstrating its effectiveness in multimodal medical prognosis tasks.
Rethinking 1-bit Optimization Leveraging Pre-trained Large Language Models
Aug 09, 2025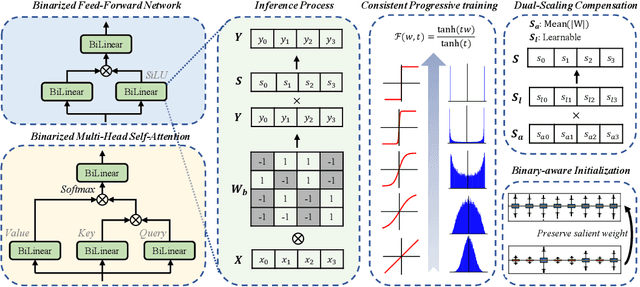

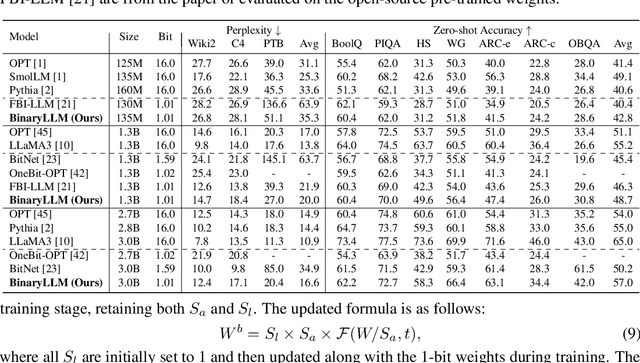
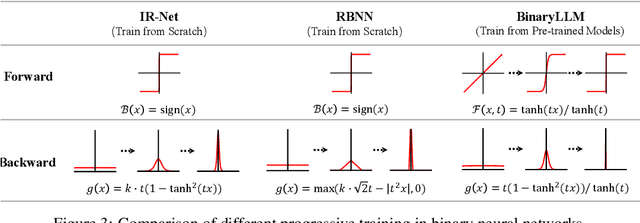
1-bit LLM quantization offers significant advantages in reducing storage and computational costs. However, existing methods typically train 1-bit LLMs from scratch, failing to fully leverage pre-trained models. This results in high training costs and notable accuracy degradation. We identify that the large gap between full precision and 1-bit representations makes direct adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the floating-point weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Introducing Quality Estimation to Machine Translation Post-editing Workflow: An Empirical Study on Its Usefulness
Jul 22, 2025This preliminary study investigates the usefulness of sentence-level Quality Estimation (QE) in English-Chinese Machine Translation Post-Editing (MTPE), focusing on its impact on post-editing speed and student translators' perceptions. It also explores the interaction effects between QE and MT quality, as well as between QE and translation expertise. The findings reveal that QE significantly reduces post-editing time. The examined interaction effects were not significant, suggesting that QE consistently improves MTPE efficiency across medium- and high-quality MT outputs and among student translators with varying levels of expertise. In addition to indicating potentially problematic segments, QE serves multiple functions in MTPE, such as validating translators' evaluations of MT quality and enabling them to double-check translation outputs. However, interview data suggest that inaccurate QE may hinder post-editing processes. This research provides new insights into the strengths and limitations of QE, facilitating its more effective integration into MTPE workflows to enhance translators' productivity.