 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScreen Them All: High-Throughput Pan-Cancer Genetic and Phenotypic Biomarker Screening from H&E Whole Slide Images
Aug 20, 2024Many molecular alterations serve as clinically prognostic or therapy-predictive biomarkers, typically detected using single or multi-gene molecular assays. However, these assays are expensive, tissue destructive and often take weeks to complete. Using AI on routine H&E WSIs offers a fast and economical approach to screen for multiple molecular biomarkers. We present a high-throughput AI-based system leveraging Virchow2, a foundation model pre-trained on 3 million slides, to interrogate genomic features previously determined by an next-generation sequencing (NGS) assay, using 47,960 scanned hematoxylin and eosin (H&E) whole slide images (WSIs) from 38,984 cancer patients. Unlike traditional methods that train individual models for each biomarker or cancer type, our system employs a unified model to simultaneously predict a wide range of clinically relevant molecular biomarkers across cancer types. By training the network to replicate the MSK-IMPACT targeted biomarker panel of 505 genes, it identified 80 high performing biomarkers with a mean AU-ROC of 0.89 in 15 most common cancer types. In addition, 40 biomarkers demonstrated strong associations with specific cancer histologic subtypes. Furthermore, 58 biomarkers were associated with targets frequently assayed clinically for therapy selection and response prediction. The model can also predict the activity of five canonical signaling pathways, identify defects in DNA repair mechanisms, and predict genomic instability measured by tumor mutation burden, microsatellite instability (MSI), and chromosomal instability (CIN). The proposed model can offer potential to guide therapy selection, improve treatment efficacy, accelerate patient screening for clinical trials and provoke the interrogation of new therapeutic targets.
Virchow: A Million-Slide Digital Pathology Foundation Model
Sep 21, 2023Computational pathology uses artificial intelligence to enable precision medicine and decision support systems through the analysis of whole slide images. It has the potential to revolutionize the diagnosis and treatment of cancer. However, a major challenge to this objective is that for many specific computational pathology tasks the amount of data is inadequate for development. To address this challenge, we created Virchow, a 632 million parameter deep neural network foundation model for computational pathology. Using self-supervised learning, Virchow is trained on 1.5 million hematoxylin and eosin stained whole slide images from diverse tissue groups, which is orders of magnitude more data than previous works. When evaluated on downstream tasks including tile-level pan-cancer detection and subtyping and slide-level biomarker prediction, Virchow outperforms state-of-the-art systems both on internal datasets drawn from the same population as the pretraining data as well as external public datasets. Virchow achieves 93% balanced accuracy for pancancer tile classification, and AUCs of 0.983 for colon microsatellite instability status prediction and 0.967 for breast CDH1 status prediction. The gains in performance highlight the importance of pretraining on massive pathology image datasets, suggesting pretraining on even larger datasets could continue improving performance for many high-impact applications where limited amounts of training data are available, such as drug outcome prediction.
Image-and-Spatial Transformer Networks for Structure-Guided Image Registration
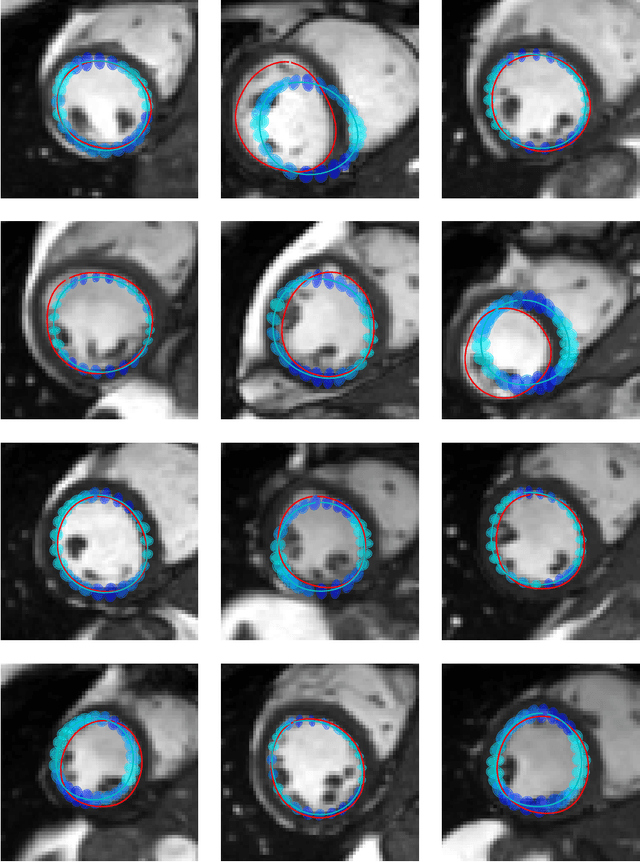
Jul 22, 2019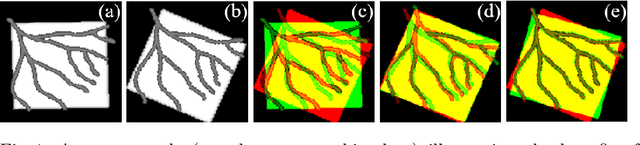
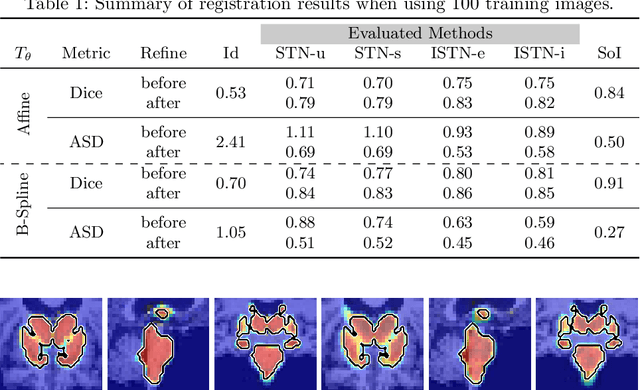
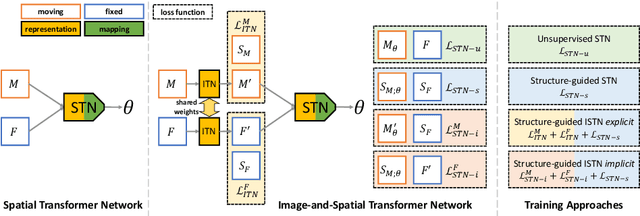

Image registration with deep neural networks has become an active field of research and exciting avenue for a long standing problem in medical imaging. The goal is to learn a complex function that maps the appearance of input image pairs to parameters of a spatial transformation in order to align corresponding anatomical structures. We argue and show that the current direct, non-iterative approaches are sub-optimal, in particular if we seek accurate alignment of Structures-of-Interest (SoI). Information about SoI is often available at training time, for example, in form of segmentations or landmarks. We introduce a novel, generic framework, Image-and-Spatial Transformer Networks (ISTNs), to leverage SoI information allowing us to learn new image representations that are optimised for the downstream registration task. Thanks to these representations we can employ a test-specific, iterative refinement over the transformation parameters which yields highly accurate registration even with very limited training data. Performance is demonstrated on pairwise 3D brain registration and illustrative synthetic data.
Uncertainty Quantification in CNN-Based Surface Prediction Using Shape Priors
Jul 30, 2018
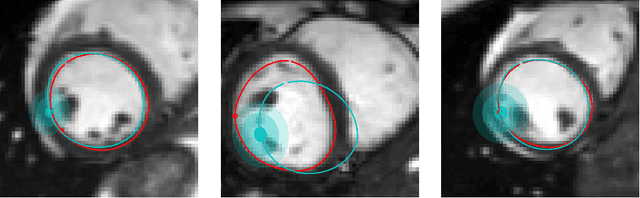
Surface reconstruction is a vital tool in a wide range of areas of medical image analysis and clinical research. Despite the fact that many methods have proposed solutions to the reconstruction problem, most, due to their deterministic nature, do not directly address the issue of quantifying uncertainty associated with their predictions. We remedy this by proposing a novel probabilistic deep learning approach capable of simultaneous surface reconstruction and associated uncertainty prediction. The method incorporates prior shape information in the form of a principal component analysis (PCA) model. Experiments using the UK Biobank data show that our probabilistic approach outperforms an analogous deterministic PCA-based method in the task of 2D organ delineation and quantifies uncertainty by formulating distributions over predicted surface vertex positions.
Computing CNN Loss and Gradients for Pose Estimation with Riemannian Geometry
Jul 17, 2018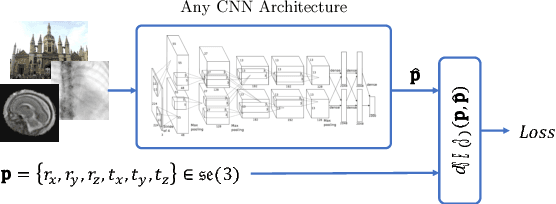
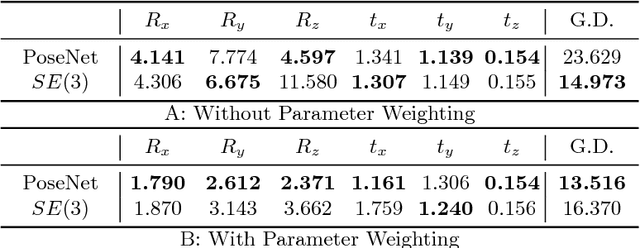
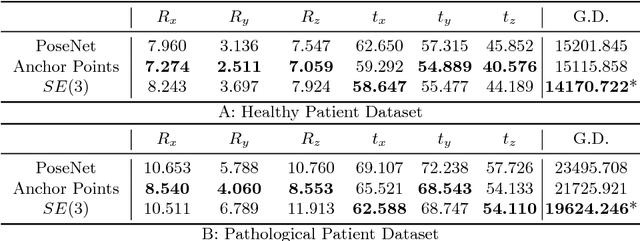

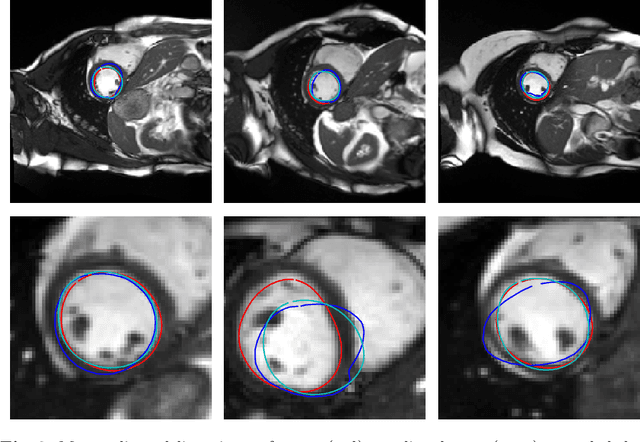
Pose estimation, i.e. predicting a 3D rigid transformation with respect to a fixed co-ordinate frame in, SE(3), is an omnipresent problem in medical image analysis with applications such as: image rigid registration, anatomical standard plane detection, tracking and device/camera pose estimation. Deep learning methods often parameterise a pose with a representation that separates rotation and translation. As commonly available frameworks do not provide means to calculate loss on a manifold, regression is usually performed using the L2-norm independently on the rotation's and the translation's parameterisations, which is a metric for linear spaces that does not take into account the Lie group structure of SE(3). In this paper, we propose a general Riemannian formulation of the pose estimation problem. We propose to train the CNN directly on SE(3) equipped with a left-invariant Riemannian metric, coupling the prediction of the translation and rotation defining the pose. At each training step, the ground truth and predicted pose are elements of the manifold, where the loss is calculated as the Riemannian geodesic distance. We then compute the optimisation direction by back-propagating the gradient with respect to the predicted pose on the tangent space of the manifold SE(3) and update the network weights. We thoroughly evaluate the effectiveness of our loss function by comparing its performance with popular and most commonly used existing methods, on tasks such as image-based localisation and intensity-based 2D/3D registration. We also show that hyper-parameters, used in our loss function to weight the contribution between rotations and translations, can be intrinsically calculated from the dataset to achieve greater performance margins.
Implicit Weight Uncertainty in Neural Networks
May 25, 2018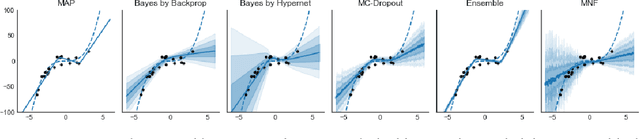

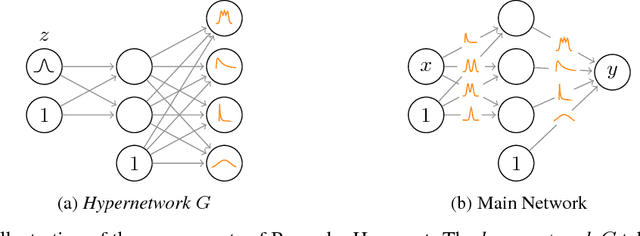

Modern neural networks tend to be overconfident on unseen, noisy or incorrectly labelled data and do not produce meaningful uncertainty measures. Bayesian deep learning aims to address this shortcoming with variational approximations (such as Bayes by Backprop or Multiplicative Normalising Flows). However, current approaches have limitations regarding flexibility and scalability. We introduce Bayes by Hypernet (BbH), a new method of variational approximation that interprets hypernetworks as implicit distributions. It naturally uses neural networks to model arbitrarily complex distributions and scales to modern deep learning architectures. In our experiments, we demonstrate that our method achieves competitive accuracies and predictive uncertainties on MNIST and a CIFAR5 task, while being the most robust against adversarial attacks.
DLTK: State of the Art Reference Implementations for Deep Learning on Medical Images
Nov 18, 2017
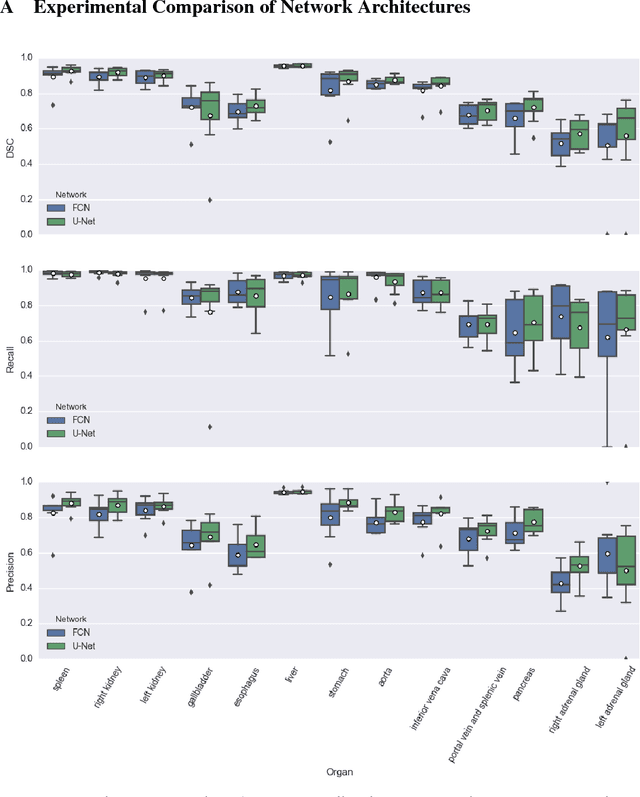
We present DLTK, a toolkit providing baseline implementations for efficient experimentation with deep learning methods on biomedical images. It builds on top of TensorFlow and its high modularity and easy-to-use examples allow for a low-threshold access to state-of-the-art implementations for typical medical imaging problems. A comparison of DLTK's reference implementations of popular network architectures for image segmentation demonstrates new top performance on the publicly available challenge data "Multi-Atlas Labeling Beyond the Cranial Vault". The average test Dice similarity coefficient of $81.5$ exceeds the previously best performing CNN ($75.7$) and the accuracy of the challenge winning method ($79.0$).
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders
Jan 13, 2017
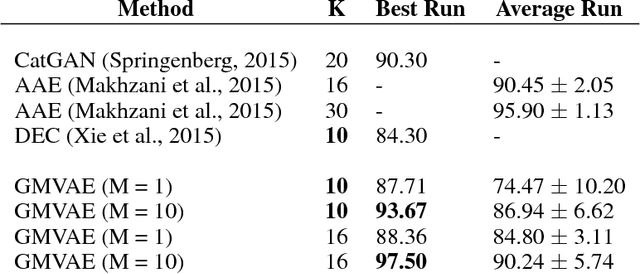
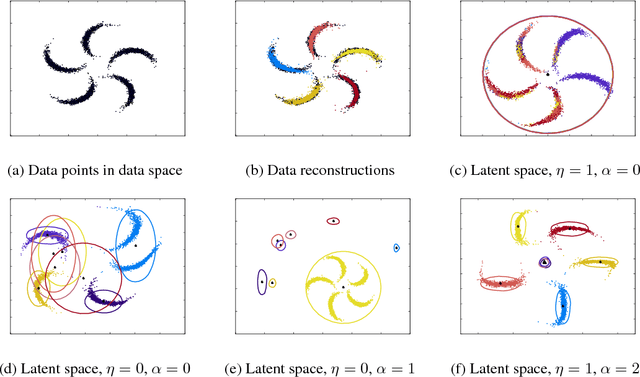

We study a variant of the variational autoencoder model (VAE) with a Gaussian mixture as a prior distribution, with the goal of performing unsupervised clustering through deep generative models. We observe that the known problem of over-regularisation that has been shown to arise in regular VAEs also manifests itself in our model and leads to cluster degeneracy. We show that a heuristic called minimum information constraint that has been shown to mitigate this effect in VAEs can also be applied to improve unsupervised clustering performance with our model. Furthermore we analyse the effect of this heuristic and provide an intuition of the various processes with the help of visualizations. Finally, we demonstrate the performance of our model on synthetic data, MNIST and SVHN, showing that the obtained clusters are distinct, interpretable and result in achieving competitive performance on unsupervised clustering to the state-of-the-art results.
DeepCut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks
Jun 05, 2016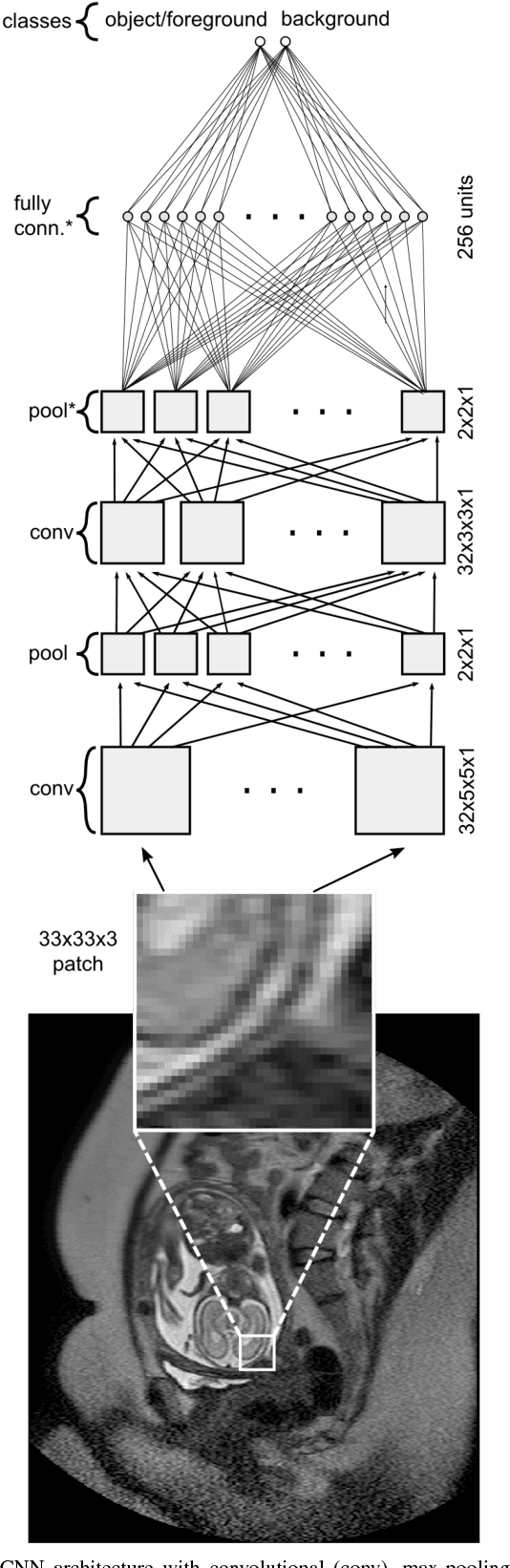
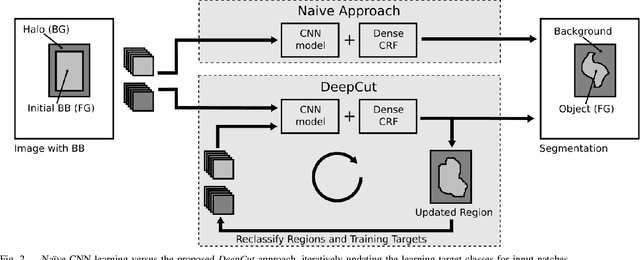
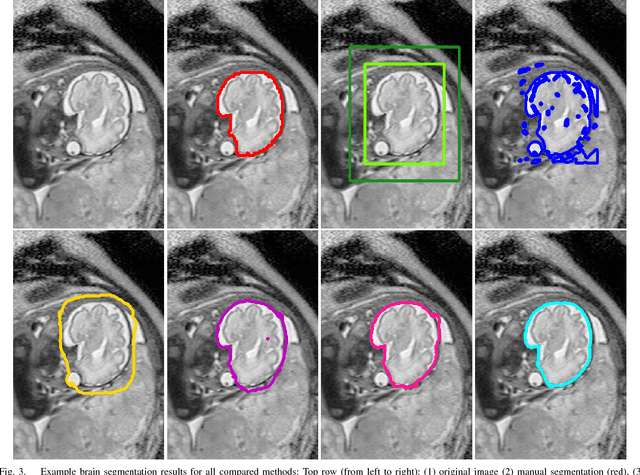
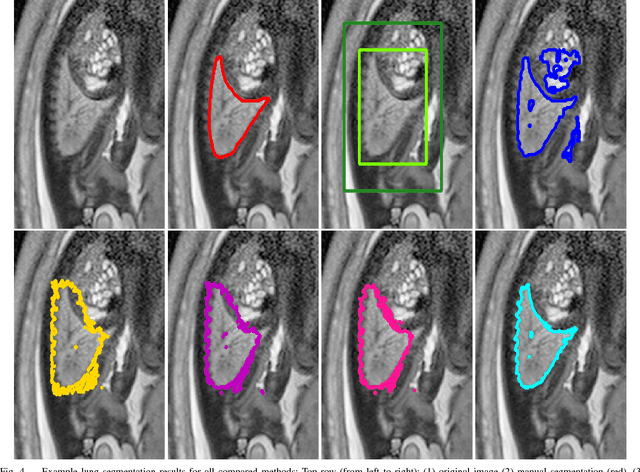
In this paper, we propose DeepCut, a method to obtain pixelwise object segmentations given an image dataset labelled with bounding box annotations. It extends the approach of the well-known GrabCut method to include machine learning by training a neural network classifier from bounding box annotations. We formulate the problem as an energy minimisation problem over a densely-connected conditional random field and iteratively update the training targets to obtain pixelwise object segmentations. Additionally, we propose variants of the DeepCut method and compare those to a naive approach to CNN training under weak supervision. We test its applicability to solve brain and lung segmentation problems on a challenging fetal magnetic resonance dataset and obtain encouraging results in terms of accuracy.
Learning under Distributed Weak Supervision
Jun 03, 2016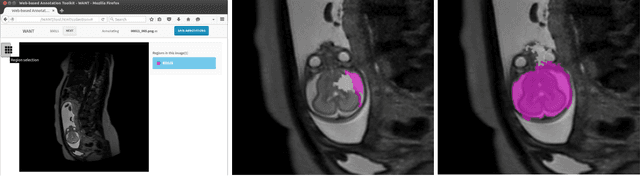
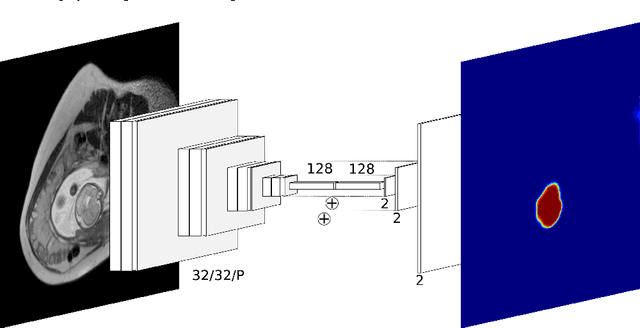
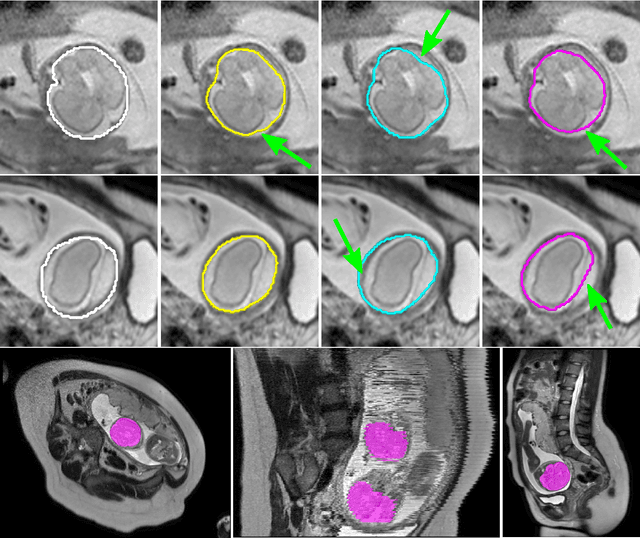
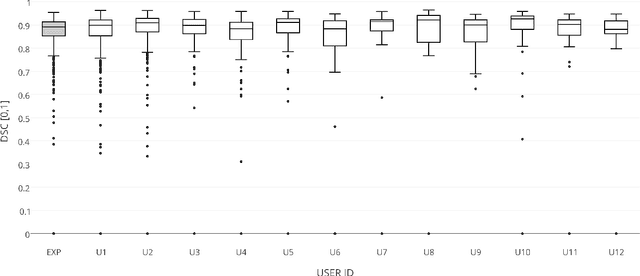
The availability of training data for supervision is a frequently encountered bottleneck of medical image analysis methods. While typically established by a clinical expert rater, the increase in acquired imaging data renders traditional pixel-wise segmentations less feasible. In this paper, we examine the use of a crowdsourcing platform for the distribution of super-pixel weak annotation tasks and collect such annotations from a crowd of non-expert raters. The crowd annotations are subsequently used for training a fully convolutional neural network to address the problem of fetal brain segmentation in T2-weighted MR images. Using this approach we report encouraging results compared to highly targeted, fully supervised methods and potentially address a frequent problem impeding image analysis research.