 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-free estimation of clinically relevant performance metrics under distribution shifts
Jul 30, 2025



Performance monitoring is essential for safe clinical deployment of image classification models. However, because ground-truth labels are typically unavailable in the target dataset, direct assessment of real-world model performance is infeasible. State-of-the-art performance estimation methods address this by leveraging confidence scores to estimate the target accuracy. Despite being a promising direction, the established methods mainly estimate the model's accuracy and are rarely evaluated in a clinical domain, where strong class imbalances and dataset shifts are common. Our contributions are twofold: First, we introduce generalisations of existing performance prediction methods that directly estimate the full confusion matrix. Then, we benchmark their performance on chest x-ray data in real-world distribution shifts as well as simulated covariate and prevalence shifts. The proposed confusion matrix estimation methods reliably predicted clinically relevant counting metrics on medical images under distribution shifts. However, our simulated shift scenarios exposed important failure modes of current performance estimation techniques, calling for a better understanding of real-world deployment contexts when implementing these performance monitoring techniques for postmarket surveillance of medical AI models.
A Real-Time Digital Twin for Type 1 Diabetes using Simulation-Based Inference
Jul 02, 2025



Accurately estimating parameters of physiological models is essential to achieving reliable digital twins. For Type 1 Diabetes, this is particularly challenging due to the complexity of glucose-insulin interactions. Traditional methods based on Markov Chain Monte Carlo struggle with high-dimensional parameter spaces and fit parameters from scratch at inference time, making them slow and computationally expensive. In this study, we propose a Simulation-Based Inference approach based on Neural Posterior Estimation to efficiently capture the complex relationships between meal intake, insulin, and glucose level, providing faster, amortized inference. Our experiments demonstrate that SBI not only outperforms traditional methods in parameter estimation but also generalizes better to unseen conditions, offering real-time posterior inference with reliable uncertainty quantification.
Subgroup Performance Analysis in Hidden Stratifications
Mar 13, 2025

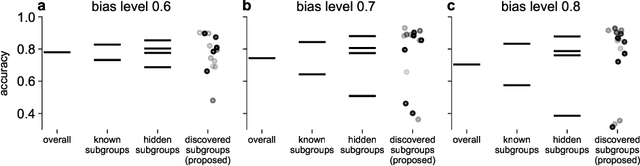

Machine learning (ML) models may suffer from significant performance disparities between patient groups. Identifying such disparities by monitoring performance at a granular level is crucial for safely deploying ML to each patient. Traditional subgroup analysis based on metadata can expose performance disparities only if the available metadata (e.g., patient sex) sufficiently reflects the main reasons for performance variability, which is not common. Subgroup discovery techniques that identify cohesive subgroups based on learned feature representations appear as a potential solution: They could expose hidden stratifications and provide more granular subgroup performance reports. However, subgroup discovery is challenging to evaluate even as a standalone task, as ground truth stratification labels do not exist in real data. Subgroup discovery has thus neither been applied nor evaluated for the application of subgroup performance monitoring. Here, we apply subgroup discovery for performance monitoring in chest x-ray and skin lesion classification. We propose novel evaluation strategies and show that a simplified subgroup discovery method without access to classification labels or metadata can expose larger performance disparities than traditional metadata-based subgroup analysis. We provide the first compelling evidence that subgroup discovery can serve as an important tool for comprehensive performance validation and monitoring of trustworthy AI in medicine.
Benchmarking Dependence Measures to Prevent Shortcut Learning in Medical Imaging
Jul 29, 2024



Medical imaging cohorts are often confounded by factors such as acquisition devices, hospital sites, patient backgrounds, and many more. As a result, deep learning models tend to learn spurious correlations instead of causally related features, limiting their generalizability to new and unseen data. This problem can be addressed by minimizing dependence measures between intermediate representations of task-related and non-task-related variables. These measures include mutual information, distance correlation, and the performance of adversarial classifiers. Here, we benchmark such dependence measures for the task of preventing shortcut learning. We study a simplified setting using Morpho-MNIST and a medical imaging task with CheXpert chest radiographs. Our results provide insights into how to mitigate confounding factors in medical imaging.
Conformal Performance Range Prediction for Segmentation Output Quality Control
Jul 18, 2024



Recent works have introduced methods to estimate segmentation performance without ground truth, relying solely on neural network softmax outputs. These techniques hold potential for intuitive output quality control. However, such performance estimates rely on calibrated softmax outputs, which is often not the case in modern neural networks. Moreover, the estimates do not take into account inherent uncertainty in segmentation tasks. These limitations may render precise performance predictions unattainable, restricting the practical applicability of performance estimation methods. To address these challenges, we develop a novel approach for predicting performance ranges with statistical guarantees of containing the ground truth with a user specified probability. Our method leverages sampling-based segmentation uncertainty estimation to derive heuristic performance ranges, and applies split conformal prediction to transform these estimates into rigorous prediction ranges that meet the desired guarantees. We demonstrate our approach on the FIVES retinal vessel segmentation dataset and compare five commonly used sampling-based uncertainty estimation techniques. Our results show that it is possible to achieve the desired coverage with small prediction ranges, highlighting the potential of performance range prediction as a valuable tool for output quality control.
Attri-Net: A Globally and Locally Inherently Interpretable Model for Multi-Label Classification Using Class-Specific Counterfactuals
Jun 08, 2024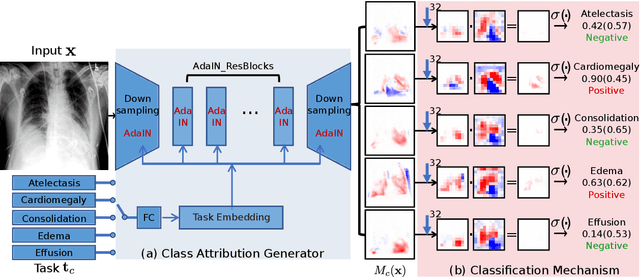
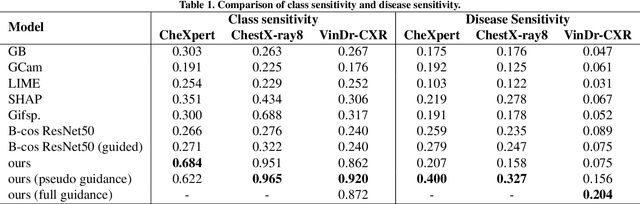
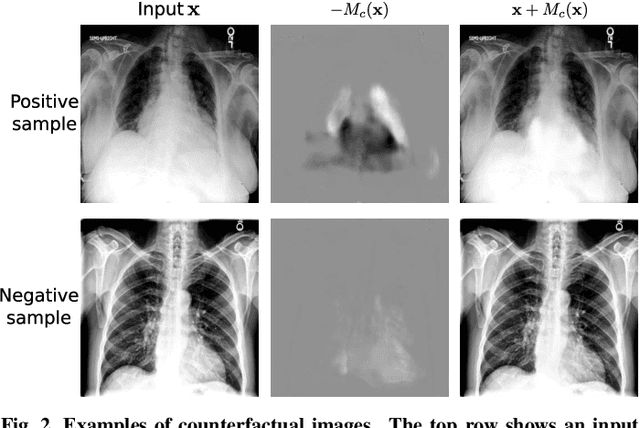

Interpretability is crucial for machine learning algorithms in high-stakes medical applications. However, high-performing neural networks typically cannot explain their predictions. Post-hoc explanation methods provide a way to understand neural networks but have been shown to suffer from conceptual problems. Moreover, current research largely focuses on providing local explanations for individual samples rather than global explanations for the model itself. In this paper, we propose Attri-Net, an inherently interpretable model for multi-label classification that provides local and global explanations. Attri-Net first counterfactually generates class-specific attribution maps to highlight the disease evidence, then performs classification with logistic regression classifiers based solely on the attribution maps. Local explanations for each prediction can be obtained by interpreting the attribution maps weighted by the classifiers' weights. Global explanation of whole model can be obtained by jointly considering learned average representations of the attribution maps for each class (called the class centers) and the weights of the linear classifiers. To ensure the model is ``right for the right reason", we further introduce a mechanism to guide the model's explanations to align with human knowledge. Our comprehensive evaluations show that Attri-Net can generate high-quality explanations consistent with clinical knowledge while not sacrificing classification performance.
Disentangling representations of retinal images with generative models
Feb 29, 2024



Retinal fundus images play a crucial role in the early detection of eye diseases and, using deep learning approaches, recent studies have even demonstrated their potential for detecting cardiovascular risk factors and neurological disorders. However, the impact of technical factors on these images can pose challenges for reliable AI applications in ophthalmology. For example, large fundus cohorts are often confounded by factors like camera type, image quality or illumination level, bearing the risk of learning shortcuts rather than the causal relationships behind the image generation process. Here, we introduce a novel population model for retinal fundus images that effectively disentangles patient attributes from camera effects, thus enabling controllable and highly realistic image generation. To achieve this, we propose a novel disentanglement loss based on distance correlation. Through qualitative and quantitative analyses, we demonstrate the effectiveness of this novel loss function in disentangling the learned subspaces. Our results show that our model provides a new perspective on the complex relationship between patient attributes and technical confounders in retinal fundus image generation.
Right for the Wrong Reason: Can Interpretable ML Techniques Detect Spurious Correlations?
Aug 08, 2023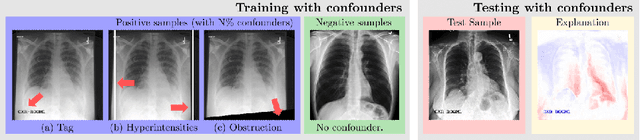
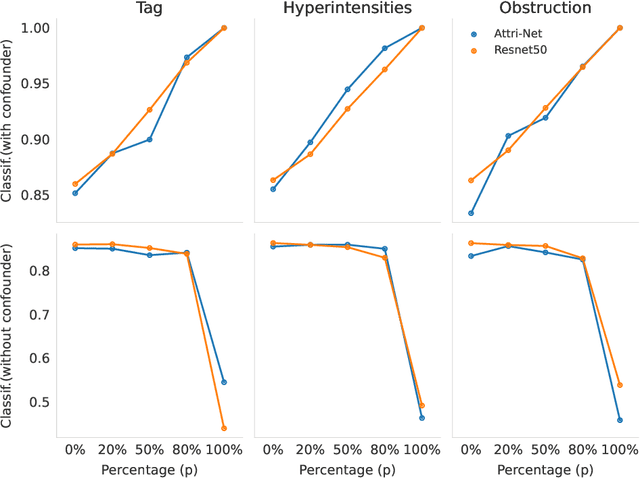
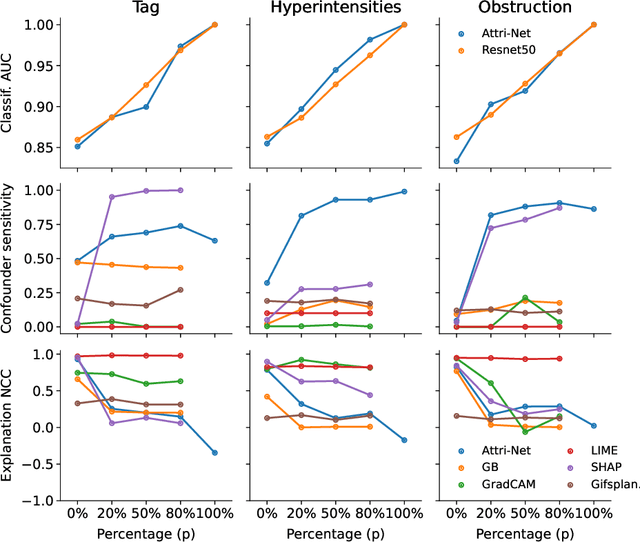
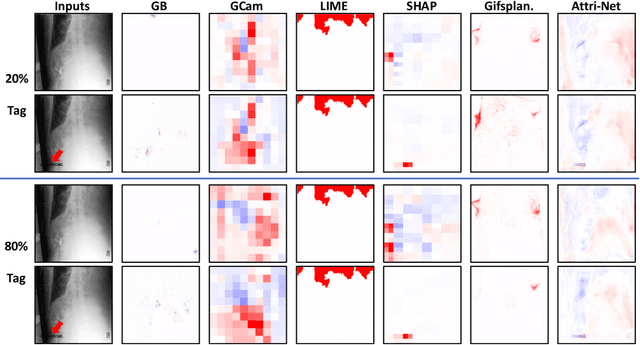
While deep neural network models offer unmatched classification performance, they are prone to learning spurious correlations in the data. Such dependencies on confounding information can be difficult to detect using performance metrics if the test data comes from the same distribution as the training data. Interpretable ML methods such as post-hoc explanations or inherently interpretable classifiers promise to identify faulty model reasoning. However, there is mixed evidence whether many of these techniques are actually able to do so. In this paper, we propose a rigorous evaluation strategy to assess an explanation technique's ability to correctly identify spurious correlations. Using this strategy, we evaluate five post-hoc explanation techniques and one inherently interpretable method for their ability to detect three types of artificially added confounders in a chest x-ray diagnosis task. We find that the post-hoc technique SHAP, as well as the inherently interpretable Attri-Net provide the best performance and can be used to reliably identify faulty model behavior.
Deep Hypothesis Tests Detect Clinically Relevant Subgroup Shifts in Medical Images
Mar 08, 2023



Distribution shifts remain a fundamental problem for the safe application of machine learning systems. If undetected, they may impact the real-world performance of such systems or will at least render original performance claims invalid. In this paper, we focus on the detection of subgroup shifts, a type of distribution shift that can occur when subgroups have a different prevalence during validation compared to the deployment setting. For example, algorithms developed on data from various acquisition settings may be predominantly applied in hospitals with lower quality data acquisition, leading to an inadvertent performance drop. We formulate subgroup shift detection in the framework of statistical hypothesis testing and show that recent state-of-the-art statistical tests can be effectively applied to subgroup shift detection on medical imaging data. We provide synthetic experiments as well as extensive evaluation on clinically meaningful subgroup shifts on histopathology as well as retinal fundus images. We conclude that classifier-based subgroup shift detection tests could be a particularly useful tool for post-market surveillance of deployed ML systems.
Inherently Interpretable Multi-Label Classification Using Class-Specific Counterfactuals
Mar 01, 2023



Interpretability is essential for machine learning algorithms in high-stakes application fields such as medical image analysis. However, high-performing black-box neural networks do not provide explanations for their predictions, which can lead to mistrust and suboptimal human-ML collaboration. Post-hoc explanation techniques, which are widely used in practice, have been shown to suffer from severe conceptual problems. Furthermore, as we show in this paper, current explanation techniques do not perform adequately in the multi-label scenario, in which multiple medical findings may co-occur in a single image. We propose Attri-Net, an inherently interpretable model for multi-label classification. Attri-Net is a powerful classifier that provides transparent, trustworthy, and human-understandable explanations. The model first generates class-specific attribution maps based on counterfactuals to identify which image regions correspond to certain medical findings. Then a simple logistic regression classifier is used to make predictions based solely on these attribution maps. We compare Attri-Net to five post-hoc explanation techniques and one inherently interpretable classifier on three chest X-ray datasets. We find that Attri-Net produces high-quality multi-label explanations consistent with clinical knowledge and has comparable classification performance to state-of-the-art classification models.