 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEGAN: Mixture of Experts for Robust Uncertainty Estimation in Endoscopy Videos
Sep 16, 2025


Reliable uncertainty quantification (UQ) is essential in medical AI. Evidential Deep Learning (EDL) offers a computationally efficient way to quantify model uncertainty alongside predictions, unlike traditional methods such as Monte Carlo (MC) Dropout and Deep Ensembles (DE). However, all these methods often rely on a single expert's annotations as ground truth for model training, overlooking the inter-rater variability in healthcare. To address this issue, we propose MEGAN, a Multi-Expert Gating Network that aggregates uncertainty estimates and predictions from multiple AI experts via EDL models trained with diverse ground truths and modeling strategies. MEGAN's gating network optimally combines predictions and uncertainties from each EDL model, enhancing overall prediction confidence and calibration. We extensively benchmark MEGAN on endoscopy videos for Ulcerative colitis (UC) disease severity estimation, assessed by visual labeling of Mayo Endoscopic Subscore (MES), where inter-rater variability is prevalent. In large-scale prospective UC clinical trial, MEGAN achieved a 3.5% improvement in F1-score and a 30.5% reduction in Expected Calibration Error (ECE) compared to existing methods. Furthermore, MEGAN facilitated uncertainty-guided sample stratification, reducing the annotation burden and potentially increasing efficiency and consistency in UC trials.
Arges: Spatio-Temporal Transformer for Ulcerative Colitis Severity Assessment in Endoscopy Videos
Oct 01, 2024Accurate assessment of disease severity from endoscopy videos in ulcerative colitis (UC) is crucial for evaluating drug efficacy in clinical trials. Severity is often measured by the Mayo Endoscopic Subscore (MES) and Ulcerative Colitis Endoscopic Index of Severity (UCEIS) score. However, expert MES/UCEIS annotation is time-consuming and susceptible to inter-rater variability, factors addressable by automation. Automation attempts with frame-level labels face challenges in fully-supervised solutions due to the prevalence of video-level labels in clinical trials. CNN-based weakly-supervised models (WSL) with end-to-end (e2e) training lack generalization to new disease scores and ignore spatio-temporal information crucial for accurate scoring. To address these limitations, we propose "Arges", a deep learning framework that utilizes a transformer with positional encoding to incorporate spatio-temporal information from frame features to estimate disease severity scores in endoscopy video. Extracted features are derived from a foundation model (ArgesFM), pre-trained on a large diverse dataset from multiple clinical trials (61M frames, 3927 videos). We evaluate four UC disease severity scores, including MES and three UCEIS component scores. Test set evaluation indicates significant improvements, with F1 scores increasing by 4.1% for MES and 18.8%, 6.6%, 3.8% for the three UCEIS component scores compared to state-of-the-art methods. Prospective validation on previously unseen clinical trial data further demonstrates the model's successful generalization.
Explicitly Minimizing the Blur Error of Variational Autoencoders
Apr 12, 2023



Variational autoencoders (VAEs) are powerful generative modelling methods, however they suffer from blurry generated samples and reconstructions compared to the images they have been trained on. Significant research effort has been spent to increase the generative capabilities by creating more flexible models but often flexibility comes at the cost of higher complexity and computational cost. Several works have focused on altering the reconstruction term of the evidence lower bound (ELBO), however, often at the expense of losing the mathematical link to maximizing the likelihood of the samples under the modeled distribution. Here we propose a new formulation of the reconstruction term for the VAE that specifically penalizes the generation of blurry images while at the same time still maximizing the ELBO under the modeled distribution. We show the potential of the proposed loss on three different data sets, where it outperforms several recently proposed reconstruction losses for VAEs.
A Field of Experts Prior for Adapting Neural Networks at Test Time
Feb 10, 2022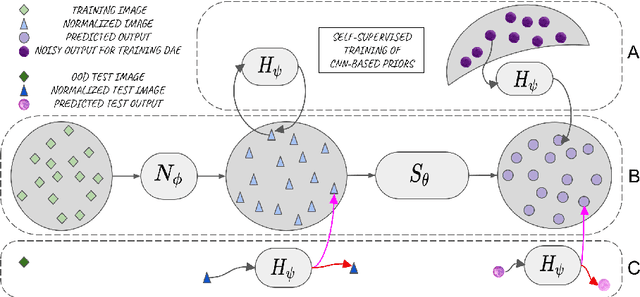
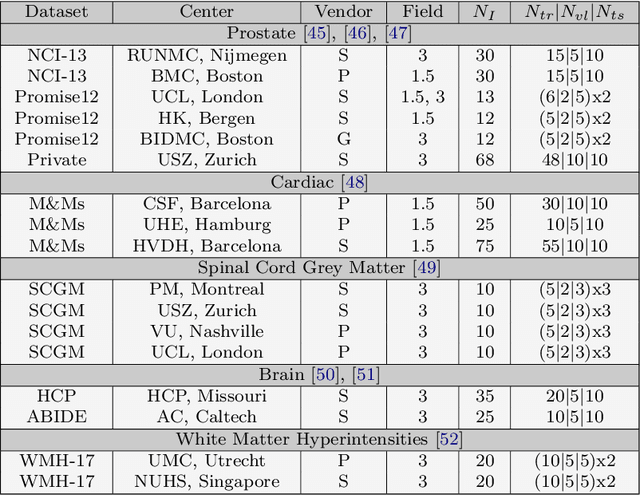
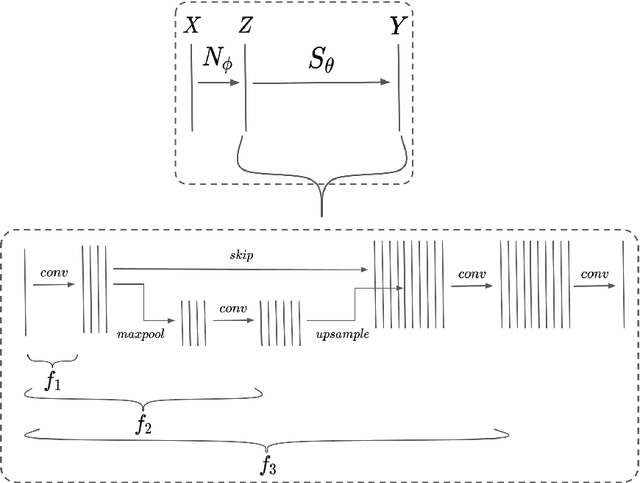
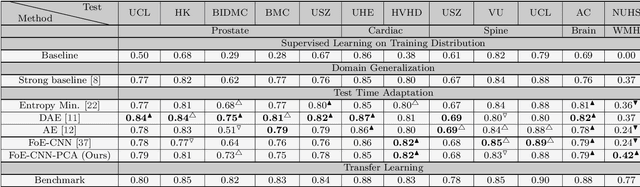
Performance of convolutional neural networks (CNNs) in image analysis tasks is often marred in the presence of acquisition-related distribution shifts between training and test images. Recently, it has been proposed to tackle this problem by fine-tuning trained CNNs for each test image. Such test-time-adaptation (TTA) is a promising and practical strategy for improving robustness to distribution shifts as it requires neither data sharing between institutions nor annotating additional data. Previous TTA methods use a helper model to increase similarity between outputs and/or features extracted from a test image with those of the training images. Such helpers, which are typically modeled using CNNs, can be task-specific and themselves vulnerable to distribution shifts in their inputs. To overcome these problems, we propose to carry out TTA by matching the feature distributions of test and training images, as modelled by a field-of-experts (FoE) prior. FoEs model complicated probability distributions as products of many simpler expert distributions. We use 1D marginal distributions of a trained task CNN's features as experts in the FoE model. Further, we compute principal components of patches of the task CNN's features, and consider the distributions of PCA loadings as additional experts. We validate the method on 5 MRI segmentation tasks (healthy tissues in 4 anatomical regions and lesions in 1 one anatomy), using data from 17 clinics, and on a MRI registration task, using data from 3 clinics. We find that the proposed FoE-based TTA is generically applicable in multiple tasks, and outperforms all previous TTA methods for lesion segmentation. For healthy tissue segmentation, the proposed method outperforms other task-agnostic methods, but a previous TTA method which is specifically designed for segmentation performs the best for most of the tested datasets. Our code is publicly available.
Local contrastive loss with pseudo-label based self-training for semi-supervised medical image segmentation
Dec 17, 2021
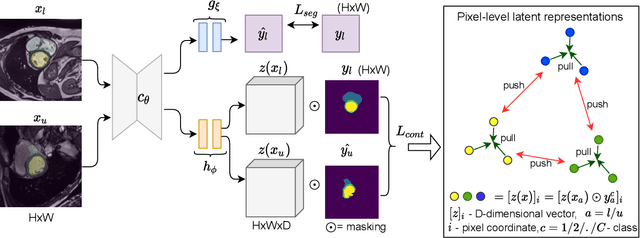
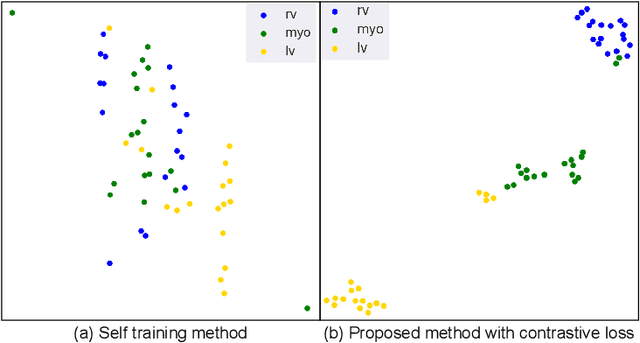

Supervised deep learning-based methods yield accurate results for medical image segmentation. However, they require large labeled datasets for this, and obtaining them is a laborious task that requires clinical expertise. Semi/self-supervised learning-based approaches address this limitation by exploiting unlabeled data along with limited annotated data. Recent self-supervised learning methods use contrastive loss to learn good global level representations from unlabeled images and achieve high performance in classification tasks on popular natural image datasets like ImageNet. In pixel-level prediction tasks such as segmentation, it is crucial to also learn good local level representations along with global representations to achieve better accuracy. However, the impact of the existing local contrastive loss-based methods remains limited for learning good local representations because similar and dissimilar local regions are defined based on random augmentations and spatial proximity; not based on the semantic label of local regions due to lack of large-scale expert annotations in the semi/self-supervised setting. In this paper, we propose a local contrastive loss to learn good pixel level features useful for segmentation by exploiting semantic label information obtained from pseudo-labels of unlabeled images alongside limited annotated images. In particular, we define the proposed loss to encourage similar representations for the pixels that have the same pseudo-label/ label while being dissimilar to the representation of pixels with different pseudo-label/label in the dataset. We perform pseudo-label based self-training and train the network by jointly optimizing the proposed contrastive loss on both labeled and unlabeled sets and segmentation loss on only the limited labeled set. We evaluated on three public cardiac and prostate datasets, and obtain high segmentation performance.
Contrastive Learning of Single-Cell Phenotypic Representations for Treatment Classification
Mar 30, 2021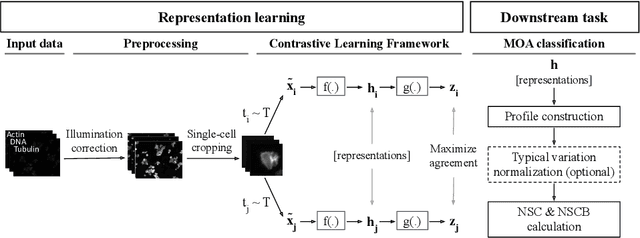

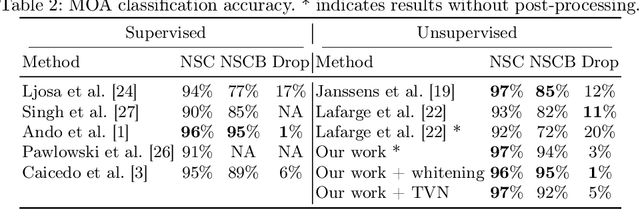

Learning robust representations to discriminate cell phenotypes based on microscopy images is important for drug discovery. Drug development efforts typically analyse thousands of cell images to screen for potential treatments. Early works focus on creating hand-engineered features from these images or learn such features with deep neural networks in a fully or weakly-supervised framework. Both require prior knowledge or labelled datasets. Therefore, subsequent works propose unsupervised approaches based on generative models to learn these representations. Recently, representations learned with self-supervised contrastive loss-based methods have yielded state-of-the-art results on various imaging tasks compared to earlier unsupervised approaches. In this work, we leverage a contrastive learning framework to learn appropriate representations from single-cell fluorescent microscopy images for the task of Mechanism-of-Action classification. The proposed work is evaluated on the annotated BBBC021 dataset, and we obtain state-of-the-art results in NSC, NCSB and drop metrics for an unsupervised approach. We observe an improvement of 10% in NCSB accuracy and 11% in NSC-NSCB drop over the previously best unsupervised method. Moreover, the performance of our unsupervised approach ties with the best supervised approach. Additionally, we observe that our framework performs well even without post-processing, unlike earlier methods. With this, we conclude that one can learn robust cell representations with contrastive learning.
Imbalance-Aware Self-Supervised Learning for 3D Radiomic Representations
Mar 06, 2021

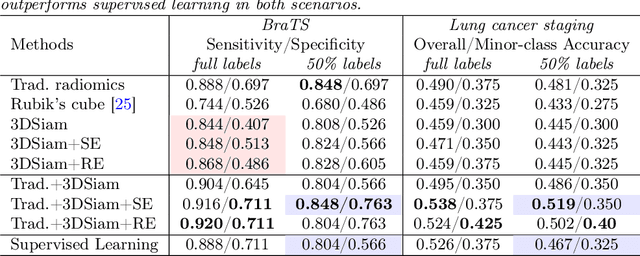

Radiomic representations can quantify properties of regions of interest in medical image data. Classically, they account for pre-defined statistics of shape, texture, and other low-level image features. Alternatively, deep learning-based representations are derived from supervised learning but require expensive annotations from experts and often suffer from overfitting and data imbalance issues. In this work, we address the challenge of learning representations of 3D medical images for an effective quantification under data imbalance. We propose a \emph{self-supervised} representation learning framework to learn high-level features of 3D volumes as a complement to existing radiomics features. Specifically, we demonstrate how to learn image representations in a self-supervised fashion using a 3D Siamese network. More importantly, we deal with data imbalance by exploiting two unsupervised strategies: a) sample re-weighting, and b) balancing the composition of training batches. When combining our learned self-supervised feature with traditional radiomics, we show significant improvement in brain tumor classification and lung cancer staging tasks covering MRI and CT imaging modalities.
Semi-supervised Task-driven Data Augmentation for Medical Image Segmentation
Jul 09, 2020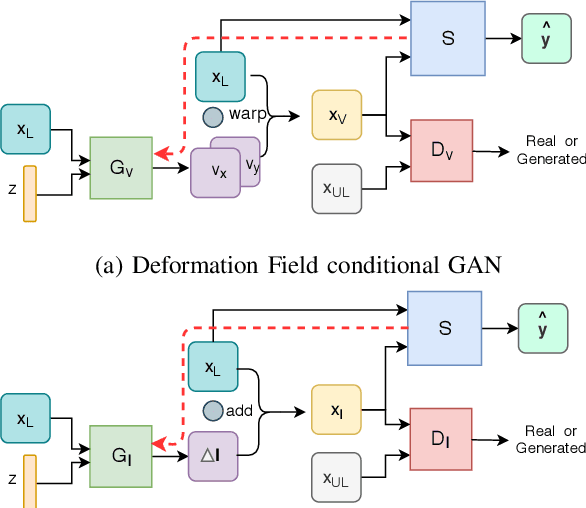
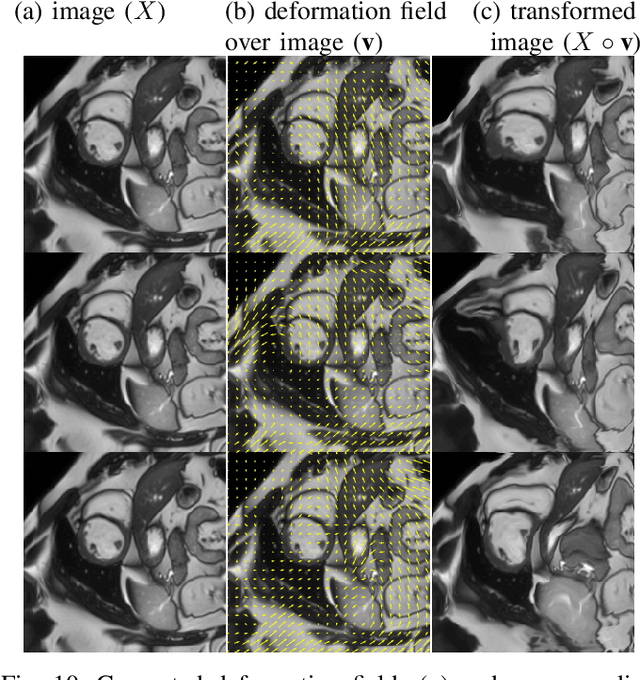
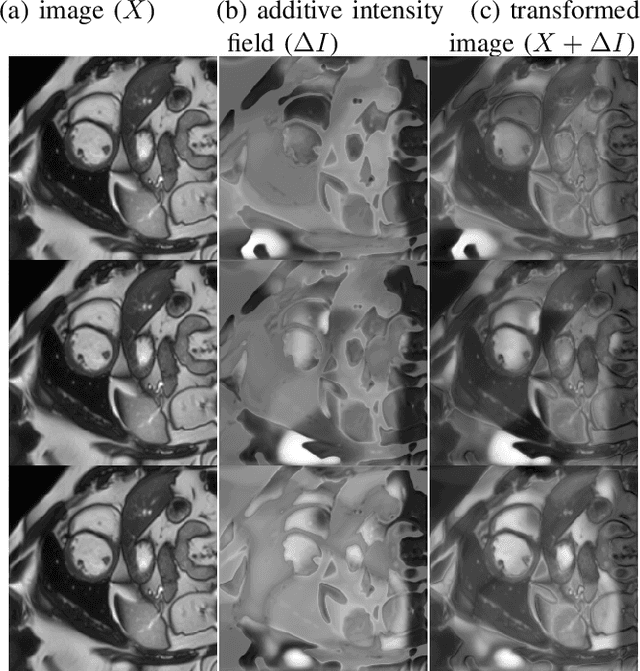
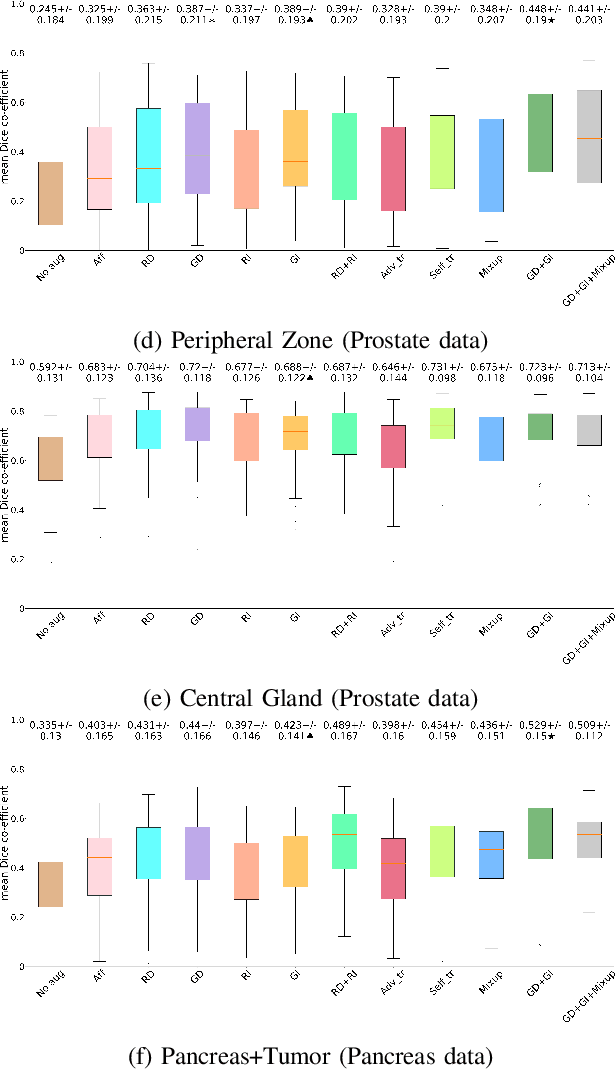
Supervised learning-based segmentation methods typically require a large number of annotated training data to generalize well at test time. In medical applications, curating such datasets is not a favourable option because acquiring a large number of annotated samples from experts is time-consuming and expensive. Consequently, numerous methods have been proposed in the literature for learning with limited annotated examples. Unfortunately, the proposed approaches in the literature have not yet yielded significant gains over random data augmentation for image segmentation, where random augmentations themselves do not yield high accuracy. In this work, we propose a novel task-driven data augmentation method for learning with limited labeled data where the synthetic data generator, is optimized for the segmentation task. The generator of the proposed method models intensity and shape variations using two sets of transformations, as additive intensity transformations and deformation fields. Both transformations are optimized using labeled as well as unlabeled examples in a semi-supervised framework. Our experiments on three medical datasets, namely cardic, prostate and pancreas, show that the proposed approach significantly outperforms standard augmentation and semi-supervised approaches for image segmentation in the limited annotation setting. The code is made publicly available at https://github.com/krishnabits001/task$\_$driven$\_$data$\_$augmentation.
Unsupervised out-of-distribution detection using kernel density estimation
Jun 18, 2020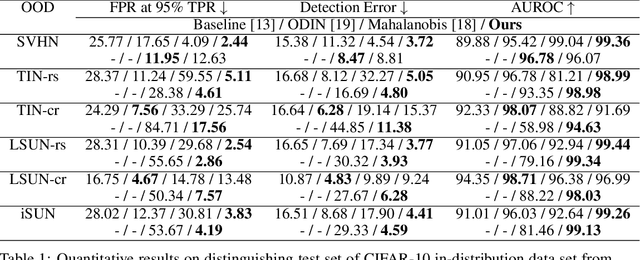
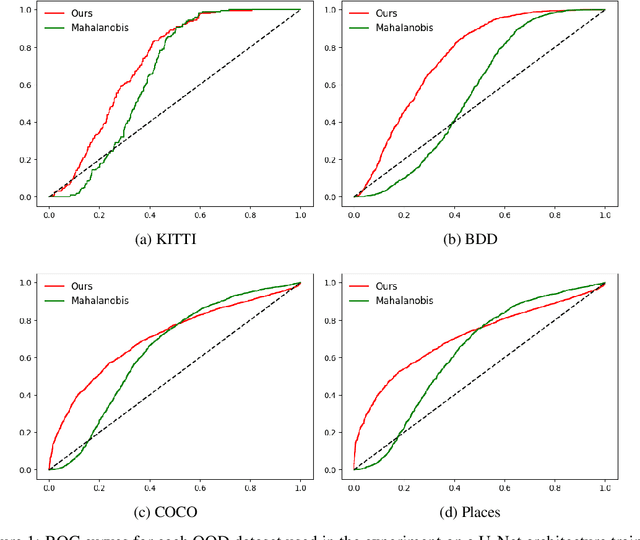
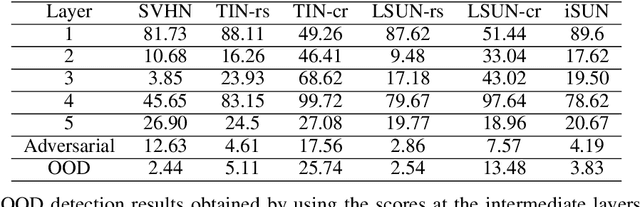
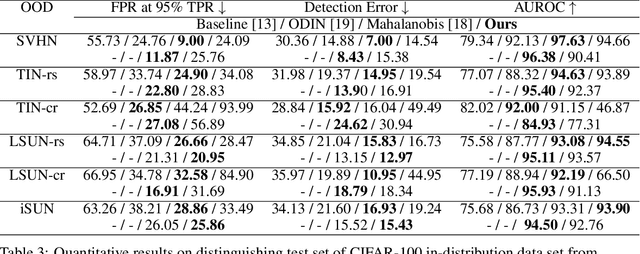
Deep neural networks achieve significant advancement to the state-of-the-art in many computer vision tasks. However, accuracy of the networks may drop drastically when test data come from a different distribution than training data. Therefore, detecting out-of-distribution (OOD) examples in neural networks arises as a crucial problem. Although, majority of the existing methods focuses on OOD detection in classification networks, the problem exist for any type of networks. In this paper, we propose an unsupervised OOD detection method that can work with both classification and non-classification networks by using kernel density estimation (KDE). The proposed method estimates probability density functions (pdfs) of activations at various levels of the network by performing KDE on the in-distribution dataset. At test time, the pdfs are evaluated on the test data to obtain a confidence score for each layer which are expected to be higher for in-distribution and lower for OOD. The scores are combined into a final score using logistic regression. We perform experiments on 2 different classification networks trained on CIFAR-10 and CIFAR-100, and on a segmentation network trained on Pascal VOC datasets. In CIFAR-10, our method achieves better results than the other methods in 4 of 6 OOD datasets while being the second best in the remaining ones. In CIFAR-100, we obtain the best results in 2 and the second best in 3 OOD datasets. In the segmentation network, we achieve the highest scores according to most of the evaluation metrics among all other OOD detection methods. The results demonstrate that the proposed method achieves competitive results to the state-of-the-art in classification networks and leads to improvement on segmentation network.
Contrastive learning of global and local features for medical image segmentation with limited annotations
Jun 18, 2020
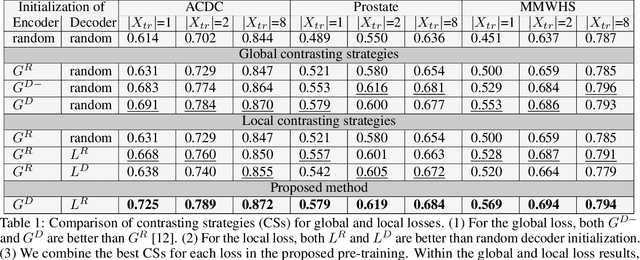

A key requirement for the success of supervised deep learning is a large labeled dataset - a condition that is difficult to meet in medical image analysis. Self-supervised learning (SSL) can help in this regard by providing a strategy to pre-train a neural network with unlabeled data, followed by fine-tuning for a downstream task with limited annotations. Contrastive learning, a particular variant of SSL, is a powerful technique for learning image-level representations. In this work, we propose strategies for extending the contrastive learning framework for segmentation of volumetric medical images in the semi-supervised setting with limited annotations, by leveraging domain-specific and problem-specific cues. Specifically, we propose (1) novel contrasting strategies that leverage structural similarity across volumetric medical images (domain-specific cue) and (2) a local version of the contrastive loss to learn distinctive representations of local regions that are useful for per-pixel segmentation (problem-specific cue). We carry out an extensive evaluation on three Magnetic Resonance Imaging (MRI) datasets. In the limited annotation setting, the proposed method yields substantial improvements compared to other self-supervision and semi-supervised learning techniques. When combined with a simple data augmentation technique, the proposed method reaches within 8% of benchmark performance using only two labeled MRI volumes for training, corresponding to only 4% (for ACDC) of the training data used to train the benchmark.