 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized SHAP values via sparse Fourier function approximation
Oct 08, 2024SHAP values are a popular local feature-attribution method widely used in interpretable and explainable AI. We tackle the problem of efficiently computing these values. We cover both the model-agnostic (black-box) setting, where one only has query access to the model and also the case of (ensembles of) trees where one has access to the structure of the tree. For both the black-box and the tree setting we propose a two-stage approach for estimating SHAP values. Our algorithm's first step harnesses recent results showing that many real-world predictors have a spectral bias that allows us to either exactly represent (in the case of ensembles of decision trees), or efficiently approximate them (in the case of neural networks) using a compact Fourier representation. In the second step of the algorithm, we use the Fourier representation to exactly compute SHAP values. The second step is computationally very cheap because firstly, the representation is compact and secondly, we prove that there exists a closed-form expression for SHAP values for the Fourier basis functions. Furthermore, the expression we derive effectively linearizes the computation into a simple summation and is amenable to parallelization on multiple cores or a GPU. Since the function approximation (first step) is only done once, it allows us to produce Shapley values in an amortized way. We show speedups compared to relevant baseline methods equal levels of accuracy for both the tree and black-box settings. Moreover, this approach introduces a reliable and fine-grained continuous trade-off between computation and accuracy through the sparsity of the Fourier approximation, a feature previously unavailable in all black-box methods.
A Scalable Walsh-Hadamard Regularizer to Overcome the Low-degree Spectral Bias of Neural Networks
May 16, 2023Despite the capacity of neural nets to learn arbitrary functions, models trained through gradient descent often exhibit a bias towards ``simpler'' functions. Various notions of simplicity have been introduced to characterize this behavior. Here, we focus on the case of neural networks with discrete (zero-one) inputs through the lens of their Fourier (Walsh-Hadamard) transforms, where the notion of simplicity can be captured through the \emph{degree} of the Fourier coefficients. We empirically show that neural networks have a tendency to learn lower-degree frequencies. We show how this spectral bias towards simpler features can in fact \emph{hurt} the neural network's generalization on real-world datasets. To remedy this we propose a new scalable functional regularization scheme that aids the neural network to learn higher degree frequencies. Our regularizer also helps avoid erroneous identification of low-degree frequencies, which further improves generalization. We extensively evaluate our regularizer on synthetic datasets to gain insights into its behavior. Finally, we show significantly improved generalization on four different datasets compared to standard neural networks and other relevant baselines.
Contrastive Learning of Single-Cell Phenotypic Representations for Treatment Classification
Mar 30, 2021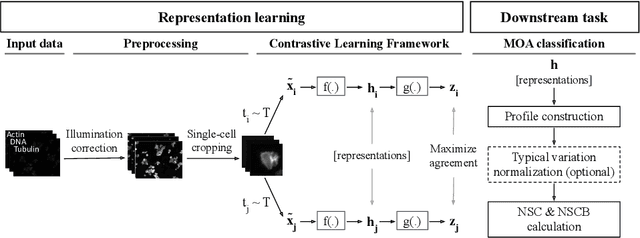

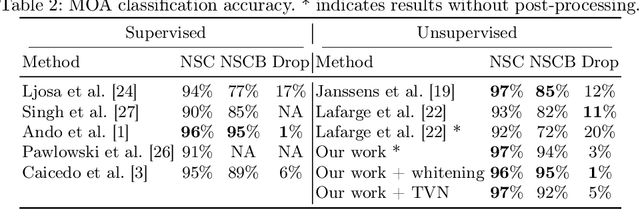

Learning robust representations to discriminate cell phenotypes based on microscopy images is important for drug discovery. Drug development efforts typically analyse thousands of cell images to screen for potential treatments. Early works focus on creating hand-engineered features from these images or learn such features with deep neural networks in a fully or weakly-supervised framework. Both require prior knowledge or labelled datasets. Therefore, subsequent works propose unsupervised approaches based on generative models to learn these representations. Recently, representations learned with self-supervised contrastive loss-based methods have yielded state-of-the-art results on various imaging tasks compared to earlier unsupervised approaches. In this work, we leverage a contrastive learning framework to learn appropriate representations from single-cell fluorescent microscopy images for the task of Mechanism-of-Action classification. The proposed work is evaluated on the annotated BBBC021 dataset, and we obtain state-of-the-art results in NSC, NCSB and drop metrics for an unsupervised approach. We observe an improvement of 10% in NCSB accuracy and 11% in NSC-NSCB drop over the previously best unsupervised method. Moreover, the performance of our unsupervised approach ties with the best supervised approach. Additionally, we observe that our framework performs well even without post-processing, unlike earlier methods. With this, we conclude that one can learn robust cell representations with contrastive learning.