 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Endoscopic Super-Resolution
Apr 20, 2026Super-resolution (SR) models are attracting growing interest for enhancing minimally invasive surgery and diagnostic videos under hardware constraints. However, valid concerns remain regarding the introduction of hallucinated structures and amplified noise, limiting their reliability in safety-critical settings. We propose a direct and practical framework to make SR systems more trustworthy by identifying where reconstructions are likely to fail. Our approach integrates a lightweight error-prediction network that operates on intermediate representations to estimate pixel-wise reconstruction error. The module is computationally efficient and low-latency, making it suitable for real-time deployment. We convert these predictions into operational failure decisions by constructing Conformal Failure Masks (CFM), which localize regions where the SR output should not be trusted. Built on conformal risk control principles, our method provides theoretical guarantees for controlling both the tolerated error limit and the miscoverage in detected failures. We evaluate our approach on image and video SR, demonstrating its effectiveness in detecting unreliable reconstructions in endoscopic and robotic surgery settings. To our knowledge, this is the first study to provide a model-agnostic, theoretically grounded approach to improving the safety of real-time endoscopic image SR.
Spatial Autoregressive Modeling of DINOv3 Embeddings for Unsupervised Anomaly Detection
Mar 03, 2026DINO models provide rich patch-level representations that have recently enabled strong performance in unsupervised anomaly detection (UAD). Most existing methods extract patch embeddings from ``normal'' images and model them independently, ignoring spatial and neighborhood relationships between patches. This implicitly assumes that self-attention and positional encodings sufficiently encode contextual information within each patch embedding. In addition, the normative distribution is often modeled as memory banks or prototype-based representations, which require storing large numbers of features and performing costly comparisons at inference time, leading to substantial memory and computational overhead. In this work, we address both limitations by proposing a simple and efficient framework that explicitly models spatial and contextual dependencies between patch embeddings using a 2D autoregressive (AR) model. Instead of storing embeddings or clustering prototypes, our approach learns a compact parametric model of the normative distribution via an AR convolutional neural network (CNN). At test time, anomaly detection reduces to a single forward pass through the network and enables fast and memory-efficient inference. We evaluate our method on the BMAD benchmark, which comprises three medical imaging datasets, and compare it against existing work including recent DINO-based methods. Experimental results demonstrate that explicitly modeling spatial dependencies achieves competitive anomaly detection performance while substantially reducing inference time and memory requirements. Code is available at the project page: https://eerdil.github.io/spatial-ar-dinov3-uad/.
Semi-Supervised Few-Shot Adaptation of Vision-Language Models
Mar 03, 2026Vision-language models (VLMs) pre-trained on large, heterogeneous data sources are becoming increasingly popular, providing rich multi-modal embeddings that enable efficient transfer to new tasks. A particularly relevant application is few-shot adaptation, where only a handful of annotated examples are available to adapt the model through multi-modal linear probes. In medical imaging, specialized VLMs have shown promising performance in zero- and few-shot image classification, which is valuable for mitigating the high cost of expert annotations. However, challenges remain in extremely low-shot regimes: the inherent class imbalances in medical tasks often lead to underrepresented categories, penalizing overall model performance. To address this limitation, we propose leveraging unlabeled data by introducing an efficient semi-supervised solver that propagates text-informed pseudo-labels during few-shot adaptation. The proposed method enables lower-budget annotation pipelines for adapting VLMs, reducing labeling effort by >50% in low-shot regimes.
A Single-Parameter Factor-Graph Image Prior
Jan 13, 2026We propose a novel piecewise smooth image model with piecewise constant local parameters that are automatically adapted to each image. Technically, the model is formulated in terms of factor graphs with NUP (normal with unknown parameters) priors, and the pertinent computations amount to iterations of conjugate-gradient steps and Gaussian message passing. The proposed model and algorithms are demonstrated with applications to denoising and contrast enhancement.
A Multi-Centric Anthropomorphic 3D CT Phantom-Based Benchmark Dataset for Harmonization
Jul 02, 2025Artificial intelligence (AI) has introduced numerous opportunities for human assistance and task automation in medicine. However, it suffers from poor generalization in the presence of shifts in the data distribution. In the context of AI-based computed tomography (CT) analysis, significant data distribution shifts can be caused by changes in scanner manufacturer, reconstruction technique or dose. AI harmonization techniques can address this problem by reducing distribution shifts caused by various acquisition settings. This paper presents an open-source benchmark dataset containing CT scans of an anthropomorphic phantom acquired with various scanners and settings, which purpose is to foster the development of AI harmonization techniques. Using a phantom allows fixing variations attributed to inter- and intra-patient variations. The dataset includes 1378 image series acquired with 13 scanners from 4 manufacturers across 8 institutions using a harmonized protocol as well as several acquisition doses. Additionally, we present a methodology, baseline results and open-source code to assess image- and feature-level stability and liver tissue classification, promoting the development of AI harmonization strategies.
Exploiting Temporal State Space Sharing for Video Semantic Segmentation
Mar 26, 2025Video semantic segmentation (VSS) plays a vital role in understanding the temporal evolution of scenes. Traditional methods often segment videos frame-by-frame or in a short temporal window, leading to limited temporal context, redundant computations, and heavy memory requirements. To this end, we introduce a Temporal Video State Space Sharing (TV3S) architecture to leverage Mamba state space models for temporal feature sharing. Our model features a selective gating mechanism that efficiently propagates relevant information across video frames, eliminating the need for a memory-heavy feature pool. By processing spatial patches independently and incorporating shifted operation, TV3S supports highly parallel computation in both training and inference stages, which reduces the delay in sequential state space processing and improves the scalability for long video sequences. Moreover, TV3S incorporates information from prior frames during inference, achieving long-range temporal coherence and superior adaptability to extended sequences. Evaluations on the VSPW and Cityscapes datasets reveal that our approach outperforms current state-of-the-art methods, establishing a new standard for VSS with consistent results across long video sequences. By achieving a good balance between accuracy and efficiency, TV3S shows a significant advancement in spatiotemporal modeling, paving the way for efficient video analysis. The code is publicly available at https://github.com/Ashesham/TV3S.git.
CamSAM2: Segment Anything Accurately in Camouflaged Videos
Mar 26, 2025Video camouflaged object segmentation (VCOS), aiming at segmenting camouflaged objects that seamlessly blend into their environment, is a fundamental vision task with various real-world applications. With the release of SAM2, video segmentation has witnessed significant progress. However, SAM2's capability of segmenting camouflaged videos is suboptimal, especially when given simple prompts such as point and box. To address the problem, we propose Camouflaged SAM2 (CamSAM2), which enhances SAM2's ability to handle camouflaged scenes without modifying SAM2's parameters. Specifically, we introduce a decamouflaged token to provide the flexibility of feature adjustment for VCOS. To make full use of fine-grained and high-resolution features from the current frame and previous frames, we propose implicit object-aware fusion (IOF) and explicit object-aware fusion (EOF) modules, respectively. Object prototype generation (OPG) is introduced to abstract and memorize object prototypes with informative details using high-quality features from previous frames. Extensive experiments are conducted to validate the effectiveness of our approach. While CamSAM2 only adds negligible learnable parameters to SAM2, it substantially outperforms SAM2 on three VCOS datasets, especially achieving 12.2 mDice gains with click prompt on MoCA-Mask and 19.6 mDice gains with mask prompt on SUN-SEG-Hard, with Hiera-T as the backbone. The code will be available at https://github.com/zhoustan/CamSAM2.
Learning to segment anatomy and lesions from disparately labeled sources in brain MRI
Mar 25, 2025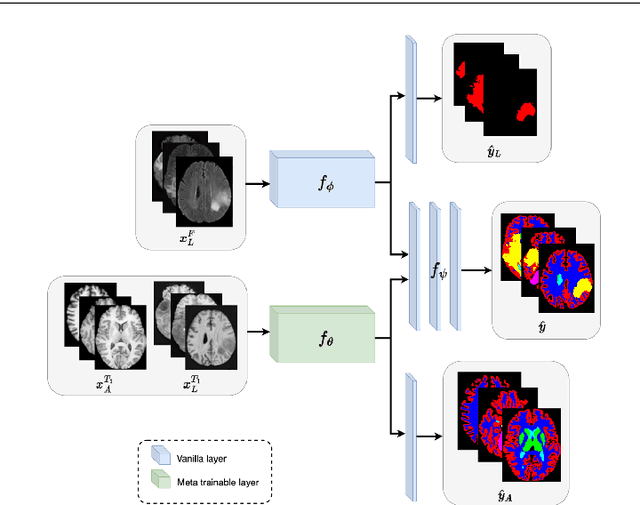
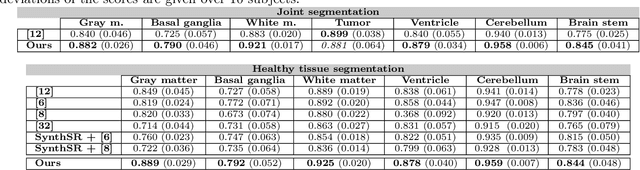

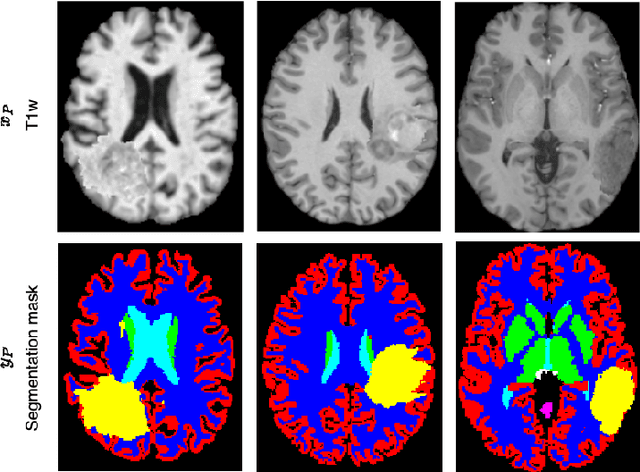
Segmenting healthy tissue structures alongside lesions in brain Magnetic Resonance Images (MRI) remains a challenge for today's algorithms due to lesion-caused disruption of the anatomy and lack of jointly labeled training datasets, where both healthy tissues and lesions are labeled on the same images. In this paper, we propose a method that is robust to lesion-caused disruptions and can be trained from disparately labeled training sets, i.e., without requiring jointly labeled samples, to automatically segment both. In contrast to prior work, we decouple healthy tissue and lesion segmentation in two paths to leverage multi-sequence acquisitions and merge information with an attention mechanism. During inference, an image-specific adaptation reduces adverse influences of lesion regions on healthy tissue predictions. During training, the adaptation is taken into account through meta-learning and co-training is used to learn from disparately labeled training images. Our model shows an improved performance on several anatomical structures and lesions on a publicly available brain glioblastoma dataset compared to the state-of-the-art segmentation methods.
Generalized Few-shot 3D Point Cloud Segmentation with Vision-Language Model
Mar 20, 2025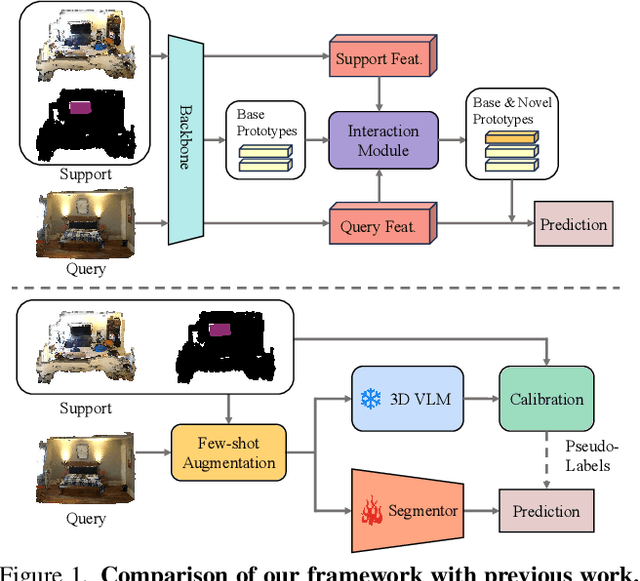
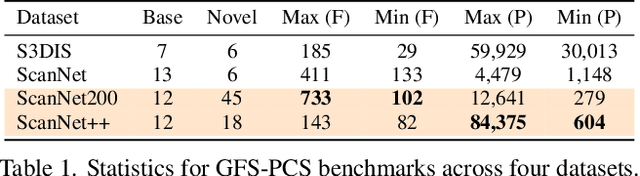
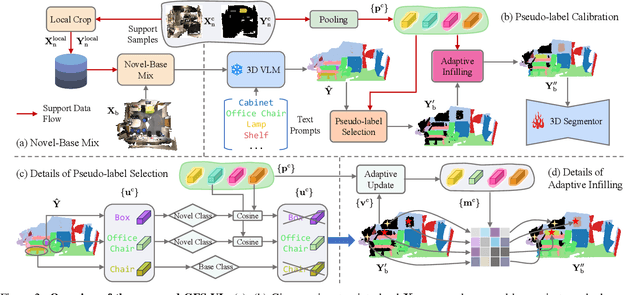
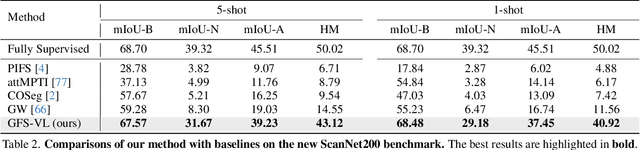
Generalized few-shot 3D point cloud segmentation (GFS-PCS) adapts models to new classes with few support samples while retaining base class segmentation. Existing GFS-PCS methods enhance prototypes via interacting with support or query features but remain limited by sparse knowledge from few-shot samples. Meanwhile, 3D vision-language models (3D VLMs), generalizing across open-world novel classes, contain rich but noisy novel class knowledge. In this work, we introduce a GFS-PCS framework that synergizes dense but noisy pseudo-labels from 3D VLMs with precise yet sparse few-shot samples to maximize the strengths of both, named GFS-VL. Specifically, we present a prototype-guided pseudo-label selection to filter low-quality regions, followed by an adaptive infilling strategy that combines knowledge from pseudo-label contexts and few-shot samples to adaptively label the filtered, unlabeled areas. Additionally, we design a novel-base mix strategy to embed few-shot samples into training scenes, preserving essential context for improved novel class learning. Moreover, recognizing the limited diversity in current GFS-PCS benchmarks, we introduce two challenging benchmarks with diverse novel classes for comprehensive generalization evaluation. Experiments validate the effectiveness of our framework across models and datasets. Our approach and benchmarks provide a solid foundation for advancing GFS-PCS in the real world. The code is at https://github.com/ZhaochongAn/GFS-VL
Conformal forecasting for surgical instrument trajectory
Mar 06, 2025


Forecasting surgical instrument trajectories and predicting the next surgical action recently started to attract attention from the research community. Both these tasks are crucial for automation and assistance in endoscopy surgery. Given the safety-critical nature of these tasks, reliable uncertainty quantification is essential. Conformal prediction is a fast-growing and widely recognized framework for uncertainty estimation in machine learning and computer vision, offering distribution-free, theoretically valid prediction intervals. In this work, we explore the application of standard conformal prediction and conformalized quantile regression to estimate uncertainty in forecasting surgical instrument motion, i.e., predicting direction and magnitude of surgical instruments' future motion. We analyze and compare their coverage and interval sizes, assessing the impact of multiple hypothesis testing and correction methods. Additionally, we show how these techniques can be employed to produce useful uncertainty heatmaps. To the best of our knowledge, this is the first study applying conformal prediction to surgical guidance, marking an initial step toward constructing principled prediction intervals with formal coverage guarantees in this domain.