 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTera-MIND: Tera-scale mouse brain simulation via spatial mRNA-guided diffusion
Mar 04, 2025Holistic 3D modeling of molecularly defined brain structures is crucial for understanding complex brain functions. Emerging tissue profiling technologies enable the construction of a comprehensive atlas of the mammalian brain with sub-cellular resolution and spatially resolved gene expression data. However, such tera-scale volumetric datasets present significant computational challenges in understanding complex brain functions within their native 3D spatial context. Here, we propose the novel generative approach $\textbf{Tera-MIND}$, which can simulate $\textbf{Tera}$-scale $\textbf{M}$ouse bra$\textbf{IN}$s in 3D using a patch-based and boundary-aware $\textbf{D}$iffusion model. Taking spatial transcriptomic data as the conditional input, we generate virtual mouse brains with comprehensive cellular morphological detail at teravoxel scale. Through the lens of 3D $gene$-$gene$ self-attention, we identify spatial molecular interactions for key transcriptomic pathways in the murine brain, exemplified by glutamatergic and dopaminergic neuronal systems. Importantly, these $in$-$silico$ biological findings are consistent and reproducible across three tera-scale virtual mouse brains. Therefore, Tera-MIND showcases a promising path toward efficient and generative simulations of whole organ systems for biomedical research. Project website: https://musikisomorphie.github.io/Tera-MIND.html
Towards IID representation learning and its application on biomedical data
Mar 01, 2022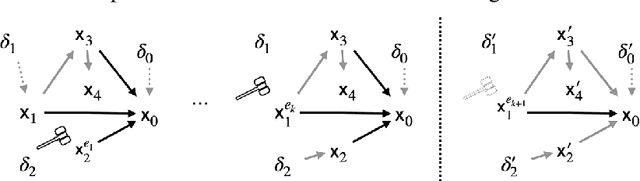
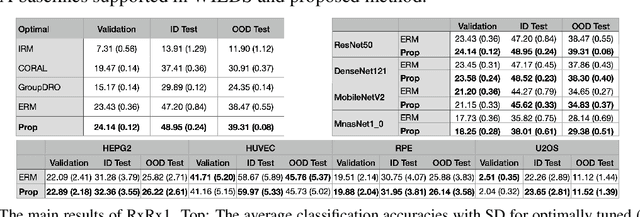
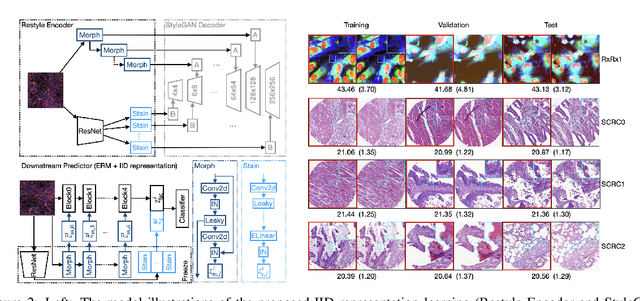
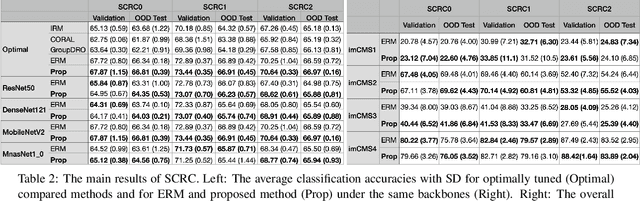
Due to the heterogeneity of real-world data, the widely accepted independent and identically distributed (IID) assumption has been criticized in recent studies on causality. In this paper, we argue that instead of being a questionable assumption, IID is a fundamental task-relevant property that needs to be learned. Consider $k$ independent random vectors $\mathsf{X}^{i = 1, \ldots, k}$, we elaborate on how a variety of different causal questions can be reformulated to learning a task-relevant function $\phi$ that induces IID among $\mathsf{Z}^i := \phi \circ \mathsf{X}^i$, which we term IID representation learning. For proof of concept, we examine the IID representation learning on Out-of-Distribution (OOD) generalization tasks. Concretely, by utilizing the representation obtained via the learned function that induces IID, we conduct prediction of molecular characteristics (molecular prediction) on two biomedical datasets with real-world distribution shifts introduced by a) preanalytical variation and b) sampling protocol. To enable reproducibility and for comparison to the state-of-the-art (SOTA) methods, this is done by following the OOD benchmarking guidelines recommended from WILDS. Compared to the SOTA baselines supported in WILDS, the results confirm the superior performance of IID representation learning on OOD tasks. The code is publicly accessible via https://github.com/CTPLab/IID_representation_learning.
Automated causal inference in application to randomized controlled clinical trials
Jan 20, 2022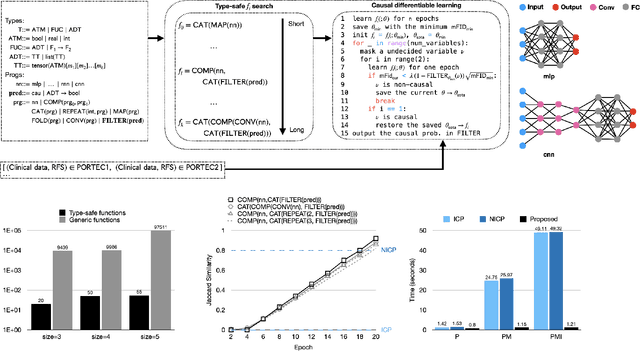
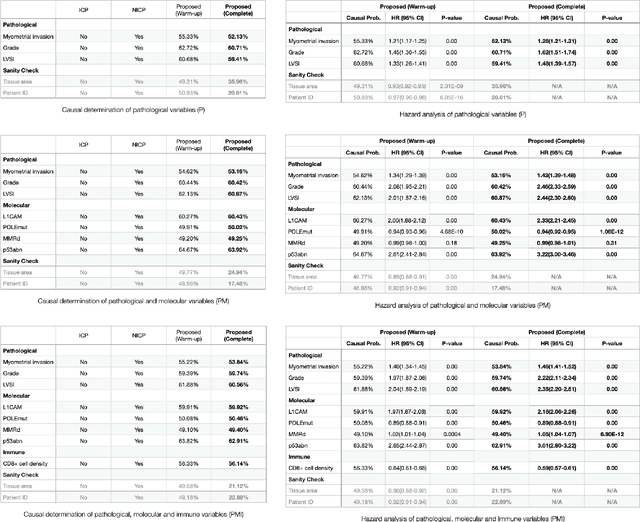
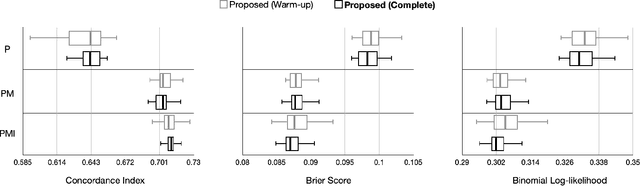
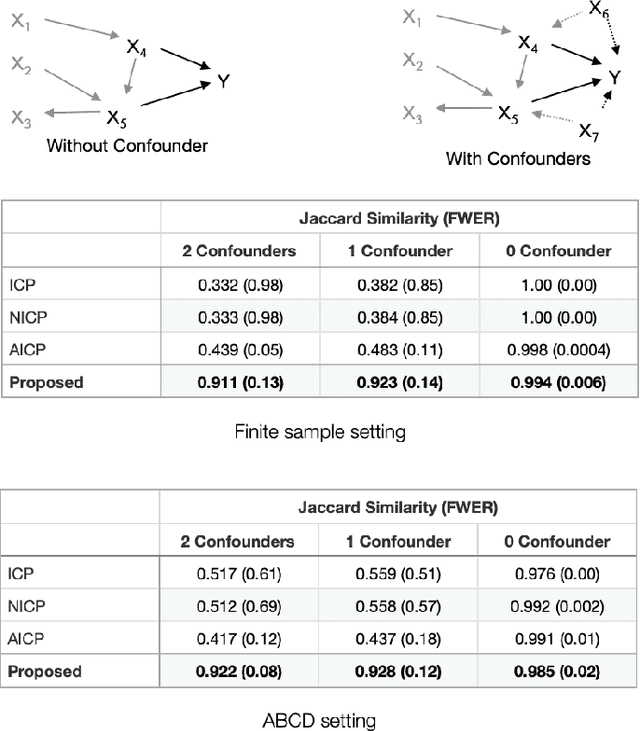
Randomized controlled trials (RCTs) are considered as the gold standard for testing causal hypotheses in the clinical domain. However, the investigation of prognostic variables of patient outcome in a hypothesized cause-effect route is not feasible using standard statistical methods. Here, we propose a new automated causal inference method (AutoCI) built upon the invariant causal prediction (ICP) framework for the causal re-interpretation of clinical trial data. Compared to existing methods, we show that the proposed AutoCI allows to efficiently determine the causal variables with a clear differentiation on two real-world RCTs of endometrial cancer patients with mature outcome and extensive clinicopathological and molecular data. This is achieved via suppressing the causal probability of non-causal variables by a wide margin. In ablation studies, we further demonstrate that the assignment of causal probabilities by AutoCI remain consistent in the presence of confounders. In conclusion, these results confirm the robustness and feasibility of AutoCI for future applications in real-world clinical analysis.
Divide-and-Conquer Adversarial Learning for High-Resolution Image and Video Enhancement
Oct 23, 2019

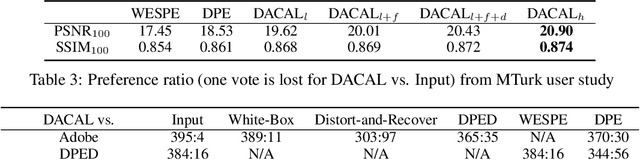

This paper introduces a divide-and-conquer inspired adversarial learning (DACAL) approach for photo enhancement. The key idea is to decompose the photo enhancement process into hierarchically multiple sub-problems, which can be better conquered from bottom to up. On the top level, we propose a perception-based division to learn additive and multiplicative components, required to translate a low-quality image or video into its high-quality counterpart. On the intermediate level, we use a frequency-based division with generative adversarial network (GAN) to weakly supervise the photo enhancement process. On the lower level, we design a dimension-based division that enables the GAN model to better approximates the distribution distance on multiple independent one-dimensional data to train the GAN model. While considering all three hierarchies, we develop multiscale and recurrent training approaches to optimize the image and video enhancement process in a weakly-supervised manner. Both quantitative and qualitative results clearly demonstrate that the proposed DACAL achieves the state-of-the-art performance for high-resolution image and video enhancement.
Sliced Wasserstein Generative Models
Apr 13, 2019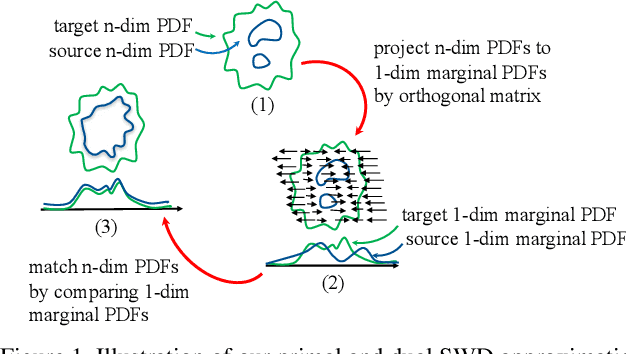
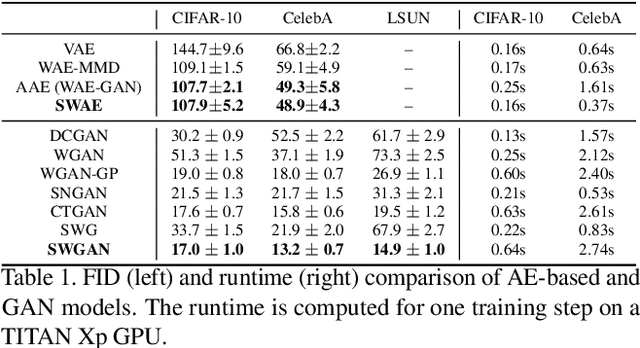
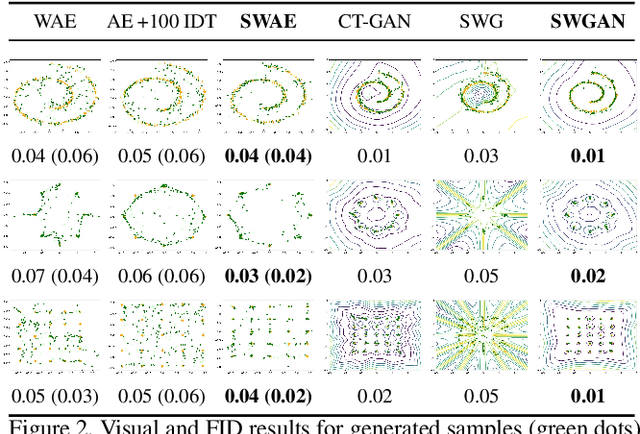
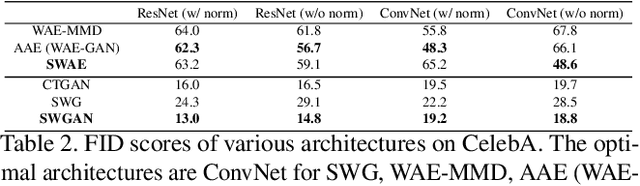
In generative modeling, the Wasserstein distance (WD) has emerged as a useful metric to measure the discrepancy between generated and real data distributions. Unfortunately, it is challenging to approximate the WD of high-dimensional distributions. In contrast, the sliced Wasserstein distance (SWD) factorizes high-dimensional distributions into their multiple one-dimensional marginal distributions and is thus easier to approximate. In this paper, we introduce novel approximations of the primal and dual SWD. Instead of using a large number of random projections, as it is done by conventional SWD approximation methods, we propose to approximate SWDs with a small number of parameterized orthogonal projections in an end-to-end deep learning fashion. As concrete applications of our SWD approximations, we design two types of differentiable SWD blocks to equip modern generative frameworks---Auto-Encoders (AE) and Generative Adversarial Networks (GAN). In the experiments, we not only show the superiority of the proposed generative models on standard image synthesis benchmarks, but also demonstrate the state-of-the-art performance on challenging high resolution image and video generation in an unsupervised manner.
Wasserstein Divergence for GANs
Sep 05, 2018
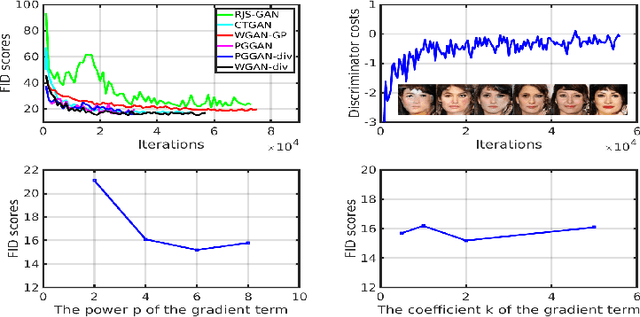
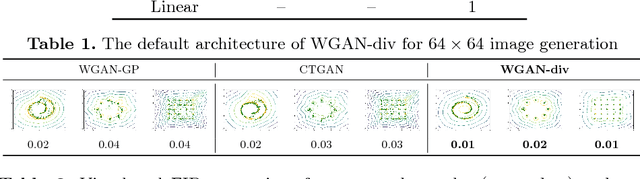

In many domains of computer vision, generative adversarial networks (GANs) have achieved great success, among which the family of Wasserstein GANs (WGANs) is considered to be state-of-the-art due to the theoretical contributions and competitive qualitative performance. However, it is very challenging to approximate the $k$-Lipschitz constraint required by the Wasserstein-1 metric~(W-met). In this paper, we propose a novel Wasserstein divergence~(W-div), which is a relaxed version of W-met and does not require the $k$-Lipschitz constraint. As a concrete application, we introduce a Wasserstein divergence objective for GANs~(WGAN-div), which can faithfully approximate W-div through optimization. Under various settings, including progressive growing training, we demonstrate the stability of the proposed WGAN-div owing to its theoretical and practical advantages over WGANs. Also, we study the quantitative and visual performance of WGAN-div on standard image synthesis benchmarks of computer vision, showing the superior performance of WGAN-div compared to the state-of-the-art methods.
Building Deep Networks on Grassmann Manifolds
Jan 29, 2018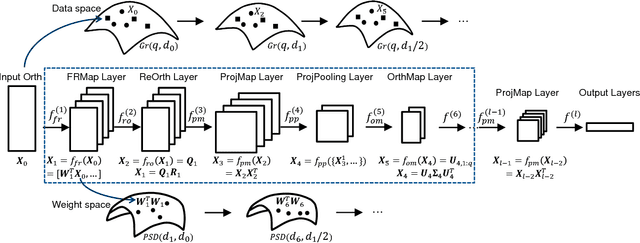
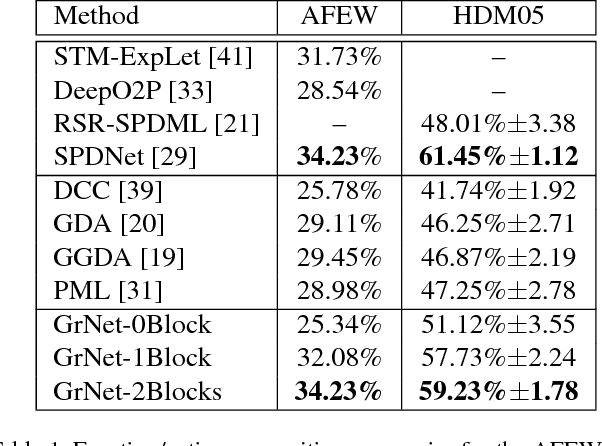
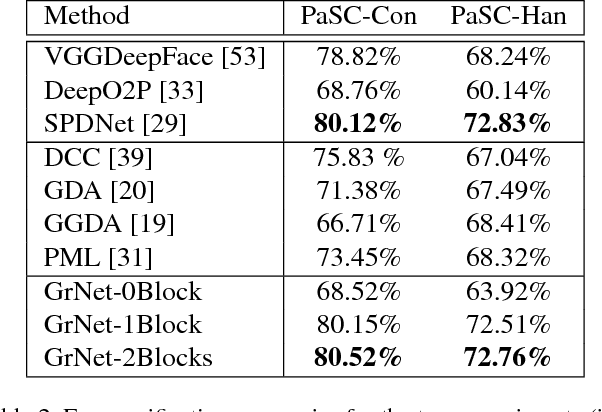
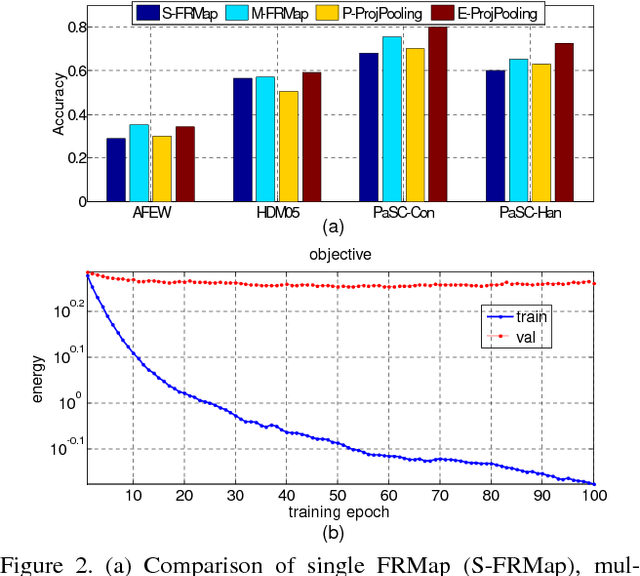
Learning representations on Grassmann manifolds is popular in quite a few visual recognition tasks. In order to enable deep learning on Grassmann manifolds, this paper proposes a deep network architecture by generalizing the Euclidean network paradigm to Grassmann manifolds. In particular, we design full rank mapping layers to transform input Grassmannian data to more desirable ones, exploit re-orthonormalization layers to normalize the resulting matrices, study projection pooling layers to reduce the model complexity in the Grassmannian context, and devise projection mapping layers to respect Grassmannian geometry and meanwhile achieve Euclidean forms for regular output layers. To train the Grassmann networks, we exploit a stochastic gradient descent setting on manifolds of the connection weights, and study a matrix generalization of backpropagation to update the structured data. The evaluations on three visual recognition tasks show that our Grassmann networks have clear advantages over existing Grassmann learning methods, and achieve results comparable with state-of-the-art approaches.
Manifold-valued Image Generation with Wasserstein Adversarial Networks
Dec 05, 2017



Unsupervised image generation has recently received an increasing amount of attention thanks to the great success of generative adversarial networks (GANs), particularly Wasserstein GANs. Inspired by the paradigm of real-valued image generation, this paper makes the first attempt to formulate the problem of generating manifold-valued images, which are frequently encountered in real-world applications. For the study, we specially exploit three typical manifold-valued image generation tasks: hue-saturation-value (HSV) color image generation, chromaticity-brightness (CB) color image generation, and diffusion-tensor (DT) image generation. In order to produce such kinds of images as realistic as possible, we generalize the state-of-the-art technique of Wasserstein GANs to the manifold context with exploiting Riemannian geometry. For the proposed manifold-valued image generation problem, we recommend three benchmark datasets that are CIFAR-10 HSV/CB color images, ImageNet HSV/CB color images, UCL DT image datasets. On the three datasets, we experimentally demonstrate the proposed manifold-aware Wasserestein GAN can generate high quality manifold-valued images.
Face Translation between Images and Videos using Identity-aware CycleGAN
Dec 04, 2017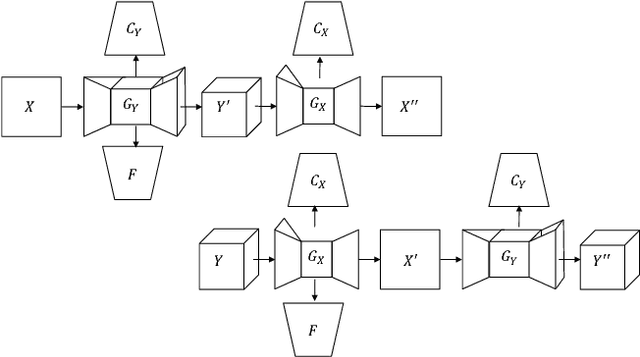
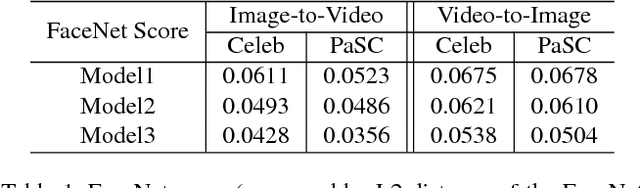
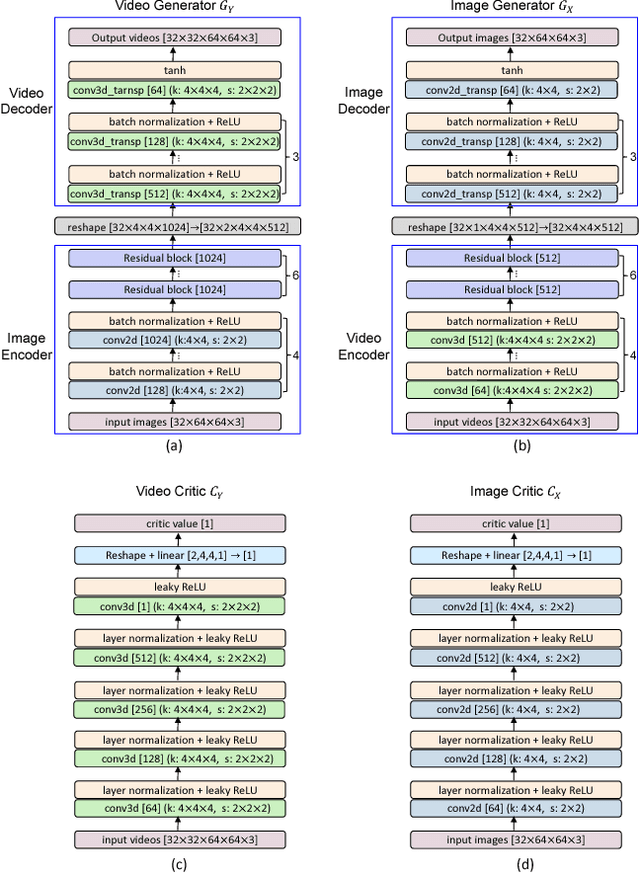

This paper presents a new problem of unpaired face translation between images and videos, which can be applied to facial video prediction and enhancement. In this problem there exist two major technical challenges: 1) designing a robust translation model between static images and dynamic videos, and 2) preserving facial identity during image-video translation. To address such two problems, we generalize the state-of-the-art image-to-image translation network (Cycle-Consistent Adversarial Networks) to the image-to-video/video-to-image translation context by exploiting a image-video translation model and an identity preservation model. In particular, we apply the state-of-the-art Wasserstein GAN technique to the setting of image-video translation for better convergence, and we meanwhile introduce a face verificator to ensure the identity. Experiments on standard image/video face datasets demonstrate the effectiveness of the proposed model in both terms of qualitative and quantitative evaluations.