 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards IID representation learning and its application on biomedical data
Mar 01, 2022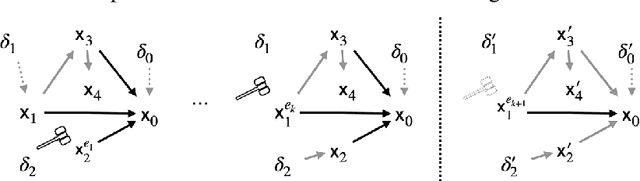
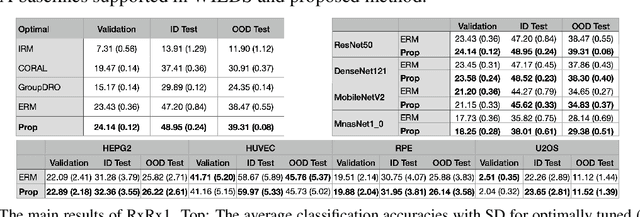
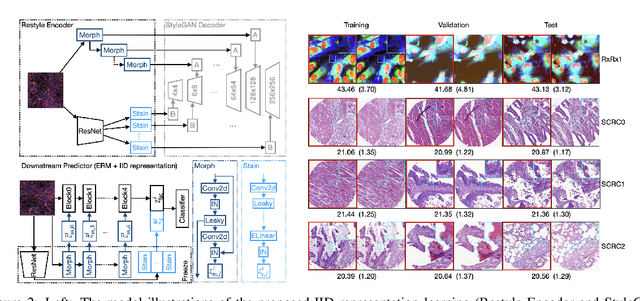
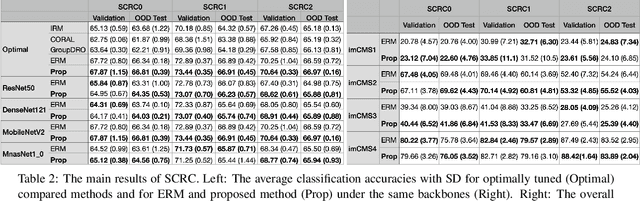
Due to the heterogeneity of real-world data, the widely accepted independent and identically distributed (IID) assumption has been criticized in recent studies on causality. In this paper, we argue that instead of being a questionable assumption, IID is a fundamental task-relevant property that needs to be learned. Consider $k$ independent random vectors $\mathsf{X}^{i = 1, \ldots, k}$, we elaborate on how a variety of different causal questions can be reformulated to learning a task-relevant function $\phi$ that induces IID among $\mathsf{Z}^i := \phi \circ \mathsf{X}^i$, which we term IID representation learning. For proof of concept, we examine the IID representation learning on Out-of-Distribution (OOD) generalization tasks. Concretely, by utilizing the representation obtained via the learned function that induces IID, we conduct prediction of molecular characteristics (molecular prediction) on two biomedical datasets with real-world distribution shifts introduced by a) preanalytical variation and b) sampling protocol. To enable reproducibility and for comparison to the state-of-the-art (SOTA) methods, this is done by following the OOD benchmarking guidelines recommended from WILDS. Compared to the SOTA baselines supported in WILDS, the results confirm the superior performance of IID representation learning on OOD tasks. The code is publicly accessible via https://github.com/CTPLab/IID_representation_learning.
Efficient Two-Step Adversarial Defense for Deep Neural Networks
Oct 08, 2018
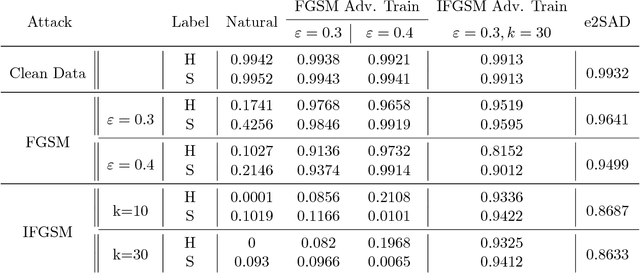


In recent years, deep neural networks have demonstrated outstanding performance in many machine learning tasks. However, researchers have discovered that these state-of-the-art models are vulnerable to adversarial examples: legitimate examples added by small perturbations which are unnoticeable to human eyes. Adversarial training, which augments the training data with adversarial examples during the training process, is a well known defense to improve the robustness of the model against adversarial attacks. However, this robustness is only effective to the same attack method used for adversarial training. Madry et al.(2017) suggest that effectiveness of iterative multi-step adversarial attacks and particularly that projected gradient descent (PGD) may be considered the universal first order adversary and applying the adversarial training with PGD implies resistance against many other first order attacks. However, the computational cost of the adversarial training with PGD and other multi-step adversarial examples is much higher than that of the adversarial training with other simpler attack techniques. In this paper, we show how strong adversarial examples can be generated only at a cost similar to that of two runs of the fast gradient sign method (FGSM), allowing defense against adversarial attacks with a robustness level comparable to that of the adversarial training with multi-step adversarial examples. We empirically demonstrate the effectiveness of the proposed two-step defense approach against different attack methods and its improvements over existing defense strategies.