 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing distributional shifts in operations management: The case of order fulfillment in customized production
Apr 24, 2023
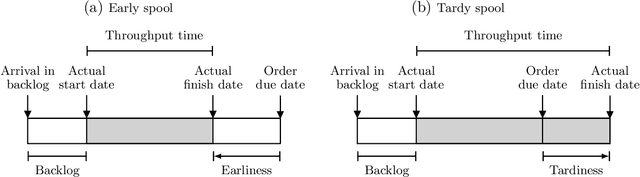
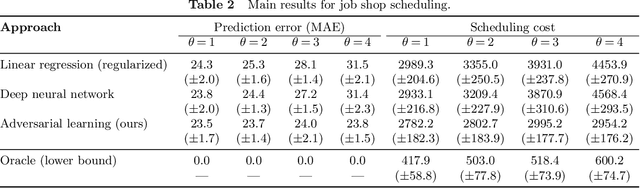
To meet order fulfillment targets, manufacturers seek to optimize production schedules. Machine learning can support this objective by predicting throughput times on production lines given order specifications. However, this is challenging when manufacturers produce customized products because customization often leads to changes in the probability distribution of operational data -- so-called distributional shifts. Distributional shifts can harm the performance of predictive models when deployed to future customer orders with new specifications. The literature provides limited advice on how such distributional shifts can be addressed in operations management. Here, we propose a data-driven approach based on adversarial learning and job shop scheduling, which allows us to account for distributional shifts in manufacturing settings with high degrees of product customization. We empirically validate our proposed approach using real-world data from a job shop production that supplies large metal components to an oil platform construction yard. Across an extensive series of numerical experiments, we find that our adversarial learning approach outperforms common baselines. Overall, this paper shows how production managers can improve their decision-making under distributional shifts.
QA Domain Adaptation using Hidden Space Augmentation and Self-Supervised Contrastive Adaptation
Oct 19, 2022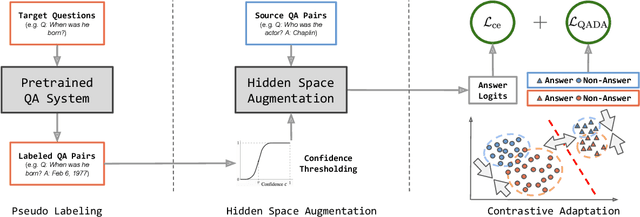
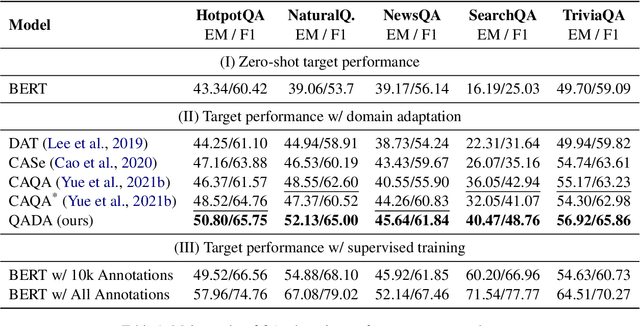
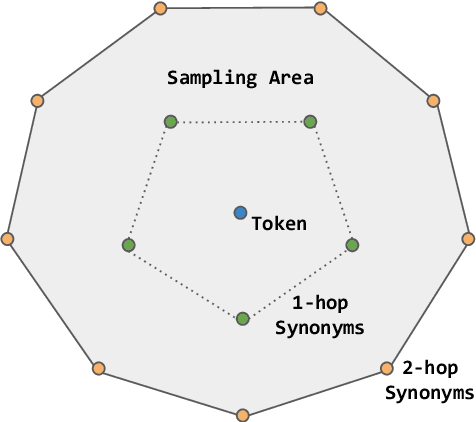
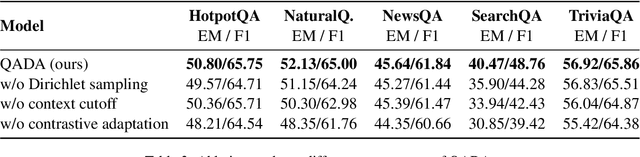
Question answering (QA) has recently shown impressive results for answering questions from customized domains. Yet, a common challenge is to adapt QA models to an unseen target domain. In this paper, we propose a novel self-supervised framework called QADA for QA domain adaptation. QADA introduces a novel data augmentation pipeline used to augment training QA samples. Different from existing methods, we enrich the samples via hidden space augmentation. For questions, we introduce multi-hop synonyms and sample augmented token embeddings with Dirichlet distributions. For contexts, we develop an augmentation method which learns to drop context spans via a custom attentive sampling strategy. Additionally, contrastive learning is integrated in the proposed self-supervised adaptation framework QADA. Unlike existing approaches, we generate pseudo labels and propose to train the model via a novel attention-based contrastive adaptation method. The attention weights are used to build informative features for discrepancy estimation that helps the QA model separate answers and generalize across source and target domains. To the best of our knowledge, our work is the first to leverage hidden space augmentation and attention-based contrastive adaptation for self-supervised domain adaptation in QA. Our evaluation shows that QADA achieves considerable improvements on multiple target datasets over state-of-the-art baselines in QA domain adaptation.
Contrastive Domain Adaptation for Question Answering using Limited Text Corpora
Aug 31, 2021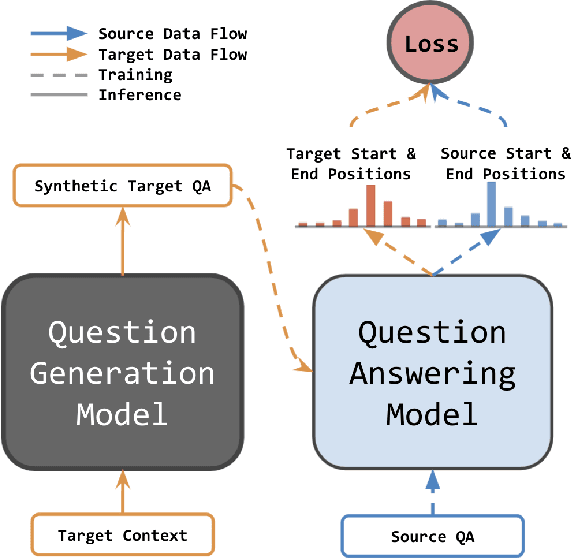
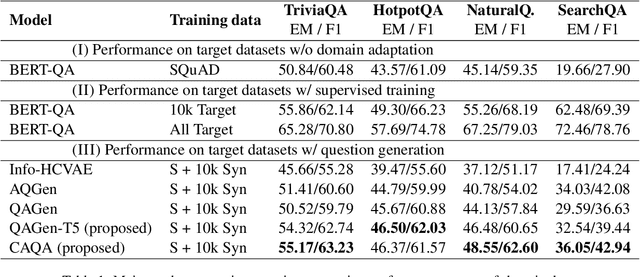
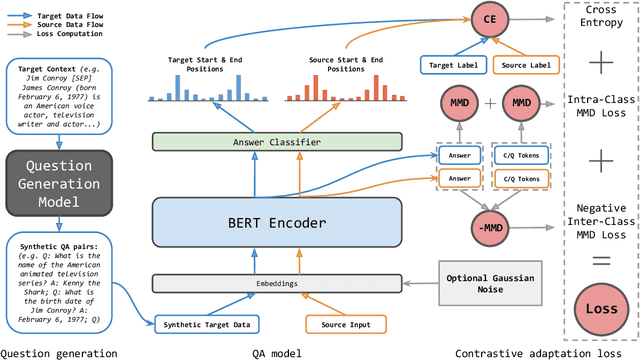
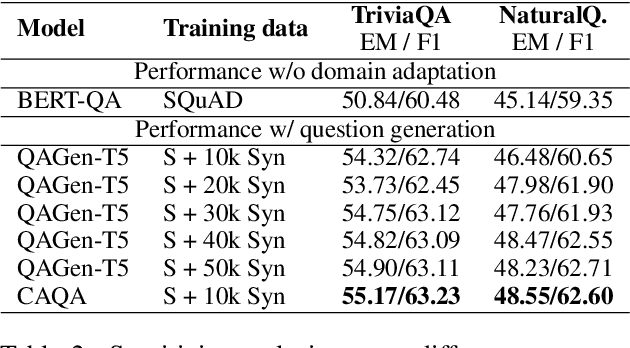
Question generation has recently shown impressive results in customizing question answering (QA) systems to new domains. These approaches circumvent the need for manually annotated training data from the new domain and, instead, generate synthetic question-answer pairs that are used for training. However, existing methods for question generation rely on large amounts of synthetically generated datasets and costly computational resources, which render these techniques widely inaccessible when the text corpora is of limited size. This is problematic as many niche domains rely on small text corpora, which naturally restricts the amount of synthetic data that can be generated. In this paper, we propose a novel framework for domain adaptation called contrastive domain adaptation for QA (CAQA). Specifically, CAQA combines techniques from question generation and domain-invariant learning to answer out-of-domain questions in settings with limited text corpora. Here, we train a QA system on both source data and generated data from the target domain with a contrastive adaptation loss that is incorporated in the training objective. By combining techniques from question generation and domain-invariant learning, our model achieved considerable improvements compared to state-of-the-art baselines.
Learning a Cost-Effective Annotation Policy for Question Answering
Oct 07, 2020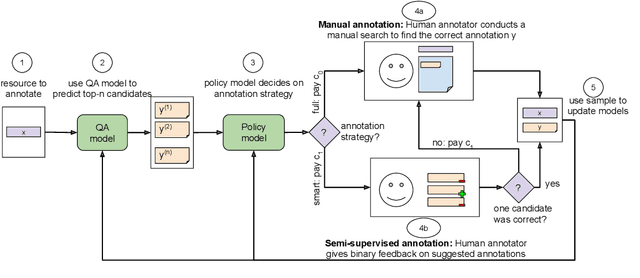

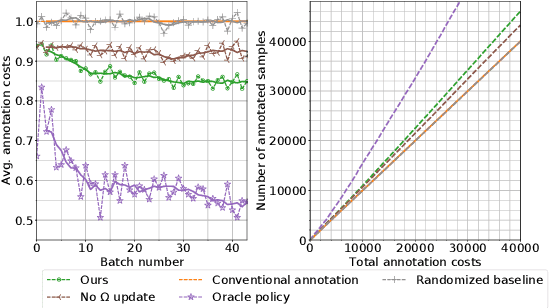

State-of-the-art question answering (QA) relies upon large amounts of training data for which labeling is time consuming and thus expensive. For this reason, customizing QA systems is challenging. As a remedy, we propose a novel framework for annotating QA datasets that entails learning a cost-effective annotation policy and a semi-supervised annotation scheme. The latter reduces the human effort: it leverages the underlying QA system to suggest potential candidate annotations. Human annotators then simply provide binary feedback on these candidates. Our system is designed such that past annotations continuously improve the future performance and thus overall annotation cost. To the best of our knowledge, this is the first paper to address the problem of annotating questions with minimal annotation cost. We compare our framework against traditional manual annotations in an extensive set of experiments. We find that our approach can reduce up to 21.1% of the annotation cost.
Practical Annotation Strategies for Question Answering Datasets
Mar 06, 2020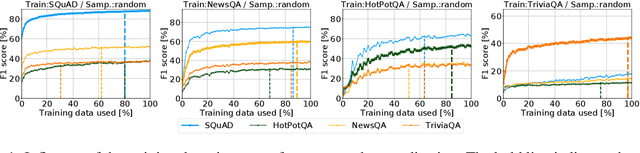
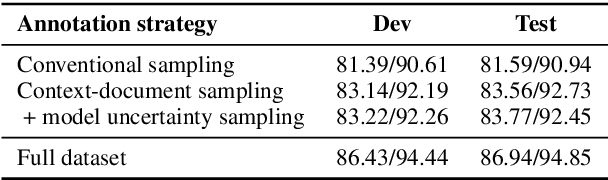
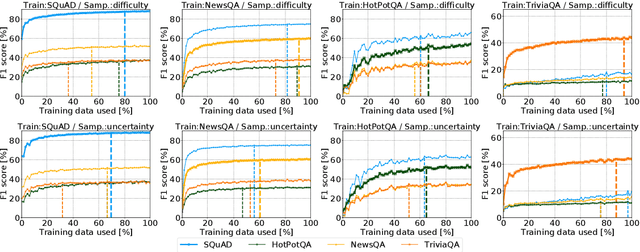
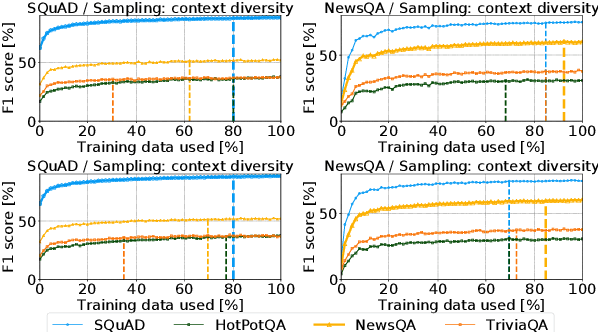
Annotating datasets for question answering (QA) tasks is very costly, as it requires intensive manual labor and often domain-specific knowledge. Yet strategies for annotating QA datasets in a cost-effective manner are scarce. To provide a remedy for practitioners, our objective is to develop heuristic rules for annotating a subset of questions, so that the annotation cost is reduced while maintaining both in- and out-of-domain performance. For this, we conduct a large-scale analysis in order to derive practical recommendations. First, we demonstrate experimentally that more training samples contribute often only to a higher in-domain test-set performance, but do not help the model in generalizing to unseen datasets. Second, we develop a model-guided annotation strategy: it makes a recommendation with regard to which subset of samples should be annotated. Its effectiveness is demonstrated in a case study based on domain customization of QA to a clinical setting. Here, remarkably, annotating a stratified subset with only 1.2% of the original training set achieves 97.7% of the performance as if the complete dataset was annotated. Hence, the labeling effort can be reduced immensely. Altogether, our work fulfills a demand in practice when labeling budgets are limited and where thus recommendations are needed for annotating QA datasets more cost-effectively.
RankQA: Neural Question Answering with Answer Re-Ranking
Jun 07, 2019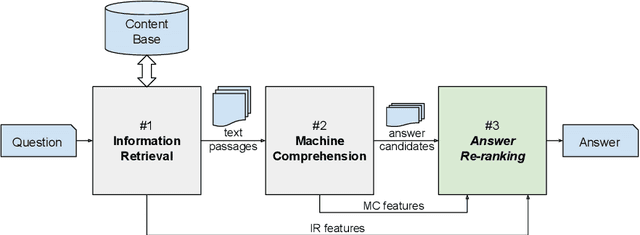
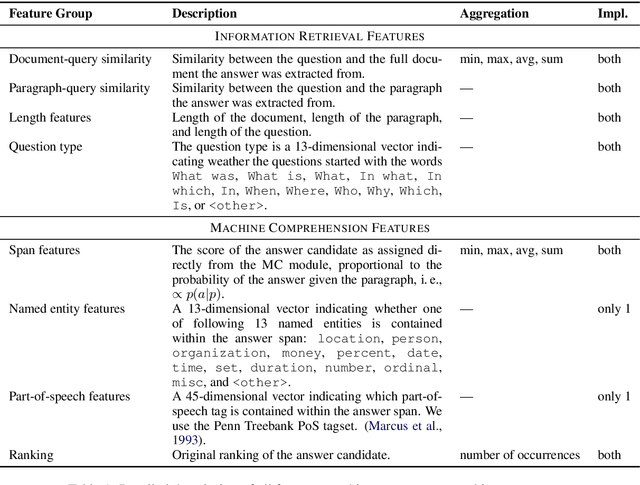
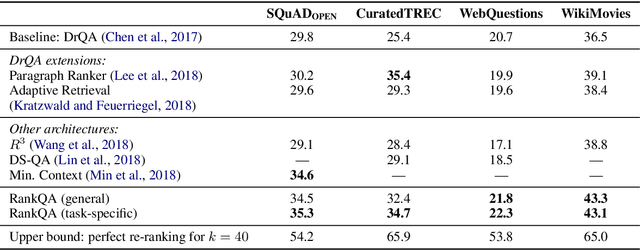
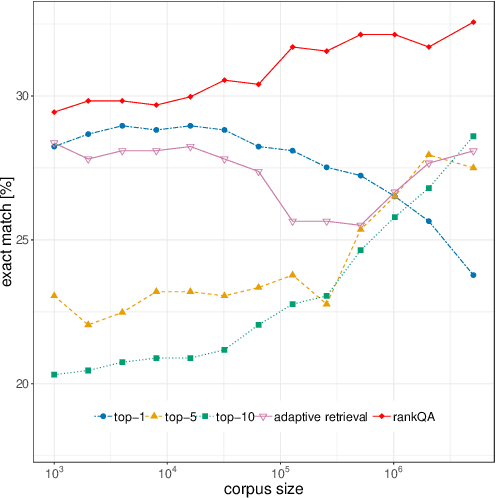
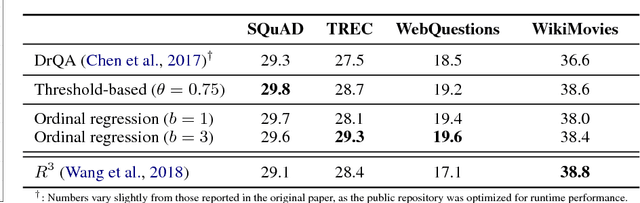
The conventional paradigm in neural question answering (QA) for narrative content is limited to a two-stage process: first, relevant text passages are retrieved and, subsequently, a neural network for machine comprehension extracts the likeliest answer. However, both stages are largely isolated in the status quo and, hence, information from the two phases is never properly fused. In contrast, this work proposes RankQA: RankQA extends the conventional two-stage process in neural QA with a third stage that performs an additional answer re-ranking. The re-ranking leverages different features that are directly extracted from the QA pipeline, i.e., a combination of retrieval and comprehension features. While our intentionally simple design allows for an efficient, data-sparse estimation, it nevertheless outperforms more complex QA systems by a significant margin: in fact, RankQA achieves state-of-the-art performance on 3 out of 4 benchmark datasets. Furthermore, its performance is especially superior in settings where the size of the corpus is dynamic. Here the answer re-ranking provides an effective remedy against the underlying noise-information trade-off due to a variable corpus size. As a consequence, RankQA represents a novel, powerful, and thus challenging baseline for future research in content-based QA.
Sample Complexity Bounds for Recurrent Neural Networks with Application to Combinatorial Graph Problems
Jan 29, 2019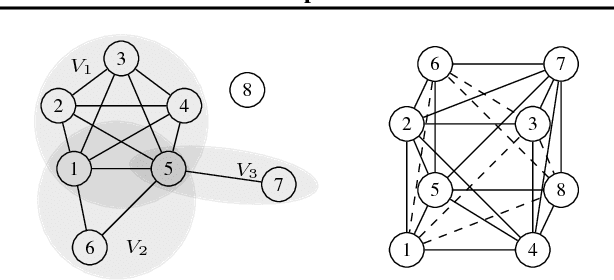
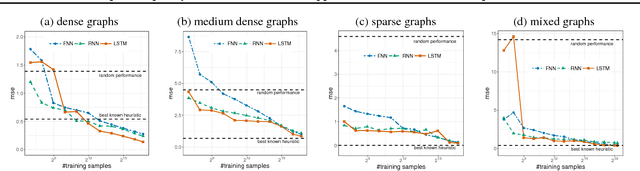
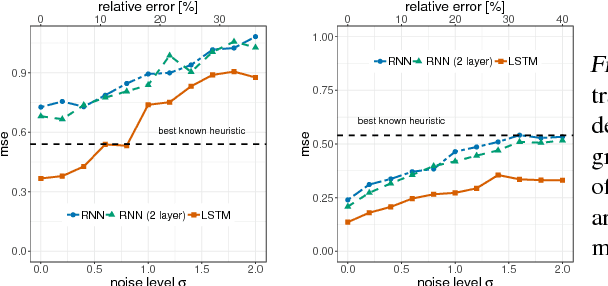
Learning to predict solutions to real-valued combinatorial graph problems promises efficient approximations. As demonstrated based on the NP-hard edge clique cover number, recurrent neural networks (RNNs) are particularly suited for this task and can even outperform state-of-the-art heuristics. However, the theoretical framework for estimating real-valued RNNs is understood only poorly. As our primary contribution, this is the first work that upper bounds the sample complexity for learning real-valued RNNs. While such derivations have been made earlier for feed-forward and convolutional neural networks, our work presents the first such attempt for recurrent neural networks. Given a single-layer RNN with $a$ rectified linear units and input of length $b$, we show that a population prediction error of $\varepsilon$ can be realized with at most $\tilde{\mathcal{O}}(a^4b/\varepsilon^2)$ samples. We further derive comparable results for multi-layer RNNs. Accordingly, a size-adaptive RNN fed with graphs of at most $n$ vertices can be learned in $\tilde{\mathcal{O}}(n^6/\varepsilon^2)$, i.e., with only a polynomial number of samples. For combinatorial graph problems, this provides a theoretical foundation that renders RNNs competitive.
Deep learning for affective computing: text-based emotion recognition in decision support
Sep 10, 2018
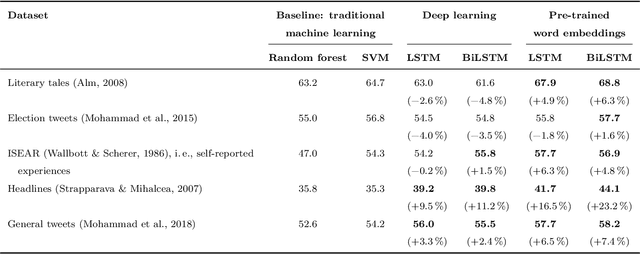
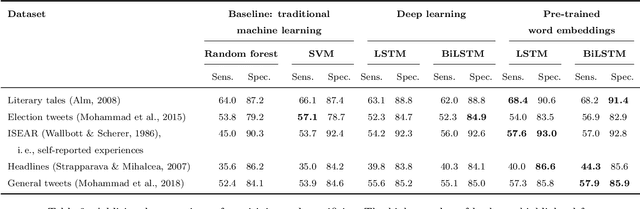
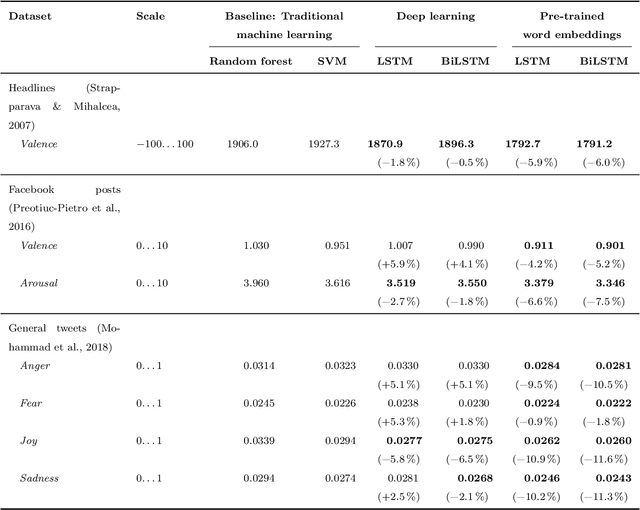
Emotions widely affect human decision-making. This fact is taken into account by affective computing with the goal of tailoring decision support to the emotional states of individuals. However, the accurate recognition of emotions within narrative documents presents a challenging undertaking due to the complexity and ambiguity of language. Performance improvements can be achieved through deep learning; yet, as demonstrated in this paper, the specific nature of this task requires the customization of recurrent neural networks with regard to bidirectional processing, dropout layers as a means of regularization, and weighted loss functions. In addition, we propose sent2affect, a tailored form of transfer learning for affective computing: here the network is pre-trained for a different task (i.e. sentiment analysis), while the output layer is subsequently tuned to the task of emotion recognition. The resulting performance is evaluated in a holistic setting across 6 benchmark datasets, where we find that both recurrent neural networks and transfer learning consistently outperform traditional machine learning. Altogether, the findings have considerable implications for the use of affective computing.
Adaptive Document Retrieval for Deep Question Answering
Aug 20, 2018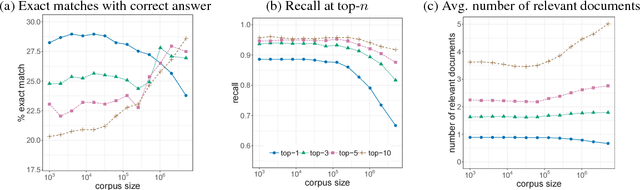
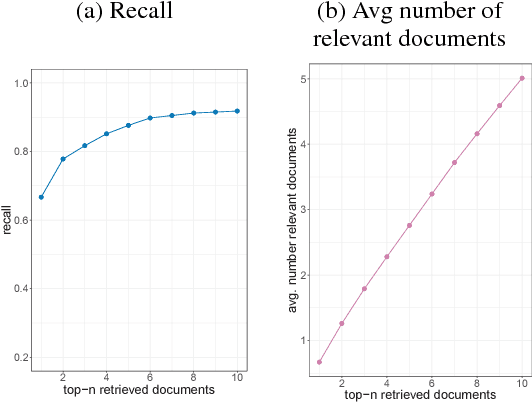

State-of-the-art systems in deep question answering proceed as follows: (1) an initial document retrieval selects relevant documents, which (2) are then processed by a neural network in order to extract the final answer. Yet the exact interplay between both components is poorly understood, especially concerning the number of candidate documents that should be retrieved. We show that choosing a static number of documents -- as used in prior research -- suffers from a noise-information trade-off and yields suboptimal results. As a remedy, we propose an adaptive document retrieval model. This learns the optimal candidate number for document retrieval, conditional on the size of the corpus and the query. We report extensive experimental results showing that our adaptive approach outperforms state-of-the-art methods on multiple benchmark datasets, as well as in the context of corpora with variable sizes.
Putting Question-Answering Systems into Practice: Transfer Learning for Efficient Domain Customization
Apr 19, 2018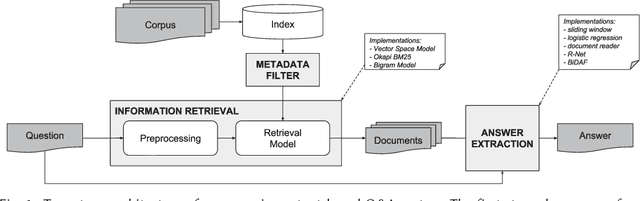

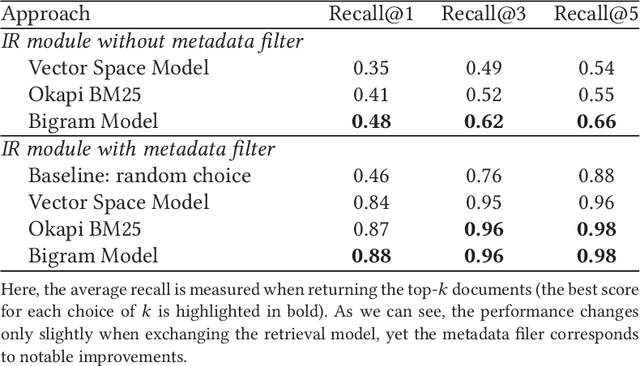
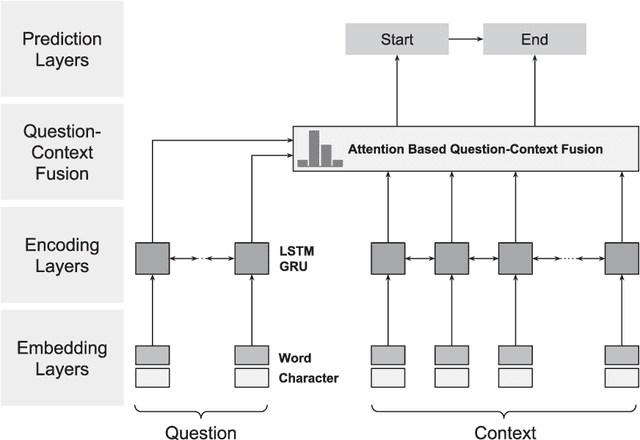
Traditional information retrieval (such as that offered by web search engines) impedes users with information overload from extensive result pages and the need to manually locate the desired information therein. Conversely, question-answering systems change how humans interact with information systems: users can now ask specific questions and obtain a tailored answer - both conveniently in natural language. Despite obvious benefits, their use is often limited to an academic context, largely because of expensive domain customizations, which means that the performance in domain-specific applications often fails to meet expectations. This paper presents cost-efficient remedies: a selection mechanism increases the precision of document retrieval and a fused approach to transfer learning is proposed in order to improve the performance of answer extraction. Here knowledge is inductively transferred from a related, yet different, tasks to the domain-specific application, while accounting for potential differences in the sample sizes across both tasks. The resulting performance is demonstrated with an actual use case from a finance company, where fewer than 400 question-answer pairs had to be annotated in order to yield significant performance gains. As a direct implication to management, this presents a promising path to better leveraging of knowledge stored in information systems.