 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable and Reliable AI in Finance
Oct 30, 2025Financial forecasting increasingly uses large neural network models, but their opacity raises challenges for trust and regulatory compliance. We present several approaches to explainable and reliable AI in finance. \emph{First}, we describe how Time-LLM, a time series foundation model, uses a prompt to avoid a wrong directional forecast. \emph{Second}, we show that combining foundation models for time series forecasting with a reliability estimator can filter our unreliable predictions. \emph{Third}, we argue for symbolic reasoning encoding domain rules for transparent justification. These approaches shift emphasize executing only forecasts that are both reliable and explainable. Experiments on equity and cryptocurrency data show that the architecture reduces false positives and supports selective execution. By integrating predictive performance with reliability estimation and rule-based reasoning, our framework advances transparent and auditable financial AI systems.
Echo State Networks for Bitcoin Time Series Prediction
Aug 07, 2025Forecasting stock and cryptocurrency prices is challenging due to high volatility and non-stationarity, influenced by factors like economic changes and market sentiment. Previous research shows that Echo State Networks (ESNs) can effectively model short-term stock market movements, capturing nonlinear patterns in dynamic data. To the best of our knowledge, this work is among the first to explore ESNs for cryptocurrency forecasting, especially during extreme volatility. We also conduct chaos analysis through the Lyapunov exponent in chaotic periods and show that our approach outperforms existing machine learning methods by a significant margin. Our findings are consistent with the Lyapunov exponent analysis, showing that ESNs are robust during chaotic periods and excel under high chaos compared to Boosting and Na\"ive methods.
Leveraging YOLO-World and GPT-4V LMMs for Zero-Shot Person Detection and Action Recognition in Drone Imagery
Apr 02, 2024



In this article, we explore the potential of zero-shot Large Multimodal Models (LMMs) in the domain of drone perception. We focus on person detection and action recognition tasks and evaluate two prominent LMMs, namely YOLO-World and GPT-4V(ision) using a publicly available dataset captured from aerial views. Traditional deep learning approaches rely heavily on large and high-quality training datasets. However, in certain robotic settings, acquiring such datasets can be resource-intensive or impractical within a reasonable timeframe. The flexibility of prompt-based Large Multimodal Models (LMMs) and their exceptional generalization capabilities have the potential to revolutionize robotics applications in these scenarios. Our findings suggest that YOLO-World demonstrates good detection performance. GPT-4V struggles with accurately classifying action classes but delivers promising results in filtering out unwanted region proposals and in providing a general description of the scenery. This research represents an initial step in leveraging LMMs for drone perception and establishes a foundation for future investigations in this area.
Deep learning for affective computing: text-based emotion recognition in decision support
Sep 10, 2018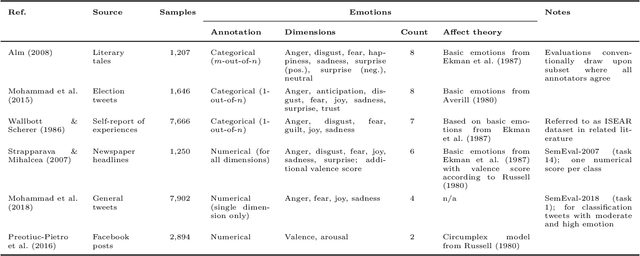
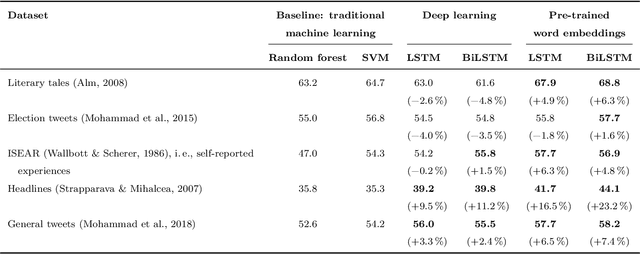
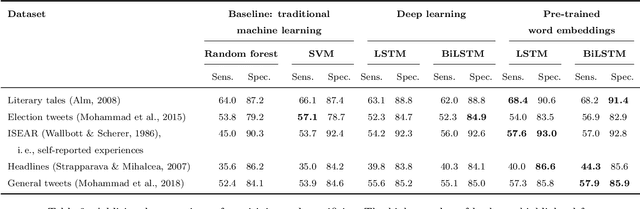
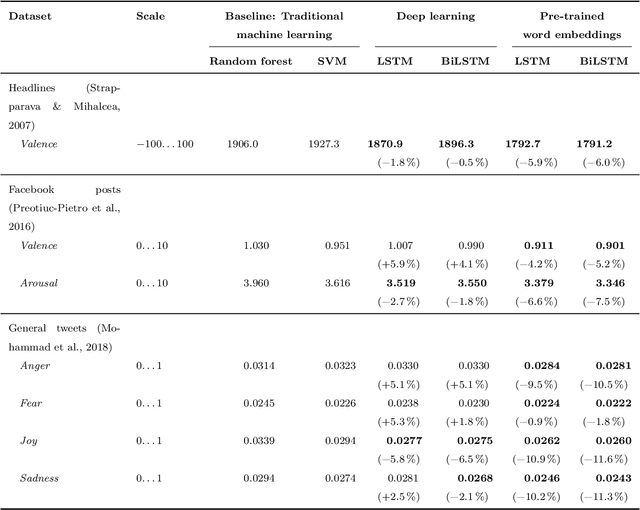
Emotions widely affect human decision-making. This fact is taken into account by affective computing with the goal of tailoring decision support to the emotional states of individuals. However, the accurate recognition of emotions within narrative documents presents a challenging undertaking due to the complexity and ambiguity of language. Performance improvements can be achieved through deep learning; yet, as demonstrated in this paper, the specific nature of this task requires the customization of recurrent neural networks with regard to bidirectional processing, dropout layers as a means of regularization, and weighted loss functions. In addition, we propose sent2affect, a tailored form of transfer learning for affective computing: here the network is pre-trained for a different task (i.e. sentiment analysis), while the output layer is subsequently tuned to the task of emotion recognition. The resulting performance is evaluated in a holistic setting across 6 benchmark datasets, where we find that both recurrent neural networks and transfer learning consistently outperform traditional machine learning. Altogether, the findings have considerable implications for the use of affective computing.
News-based trading strategies
Jul 18, 2018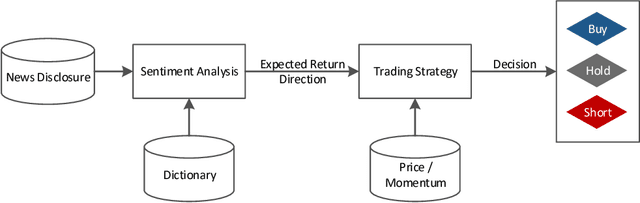
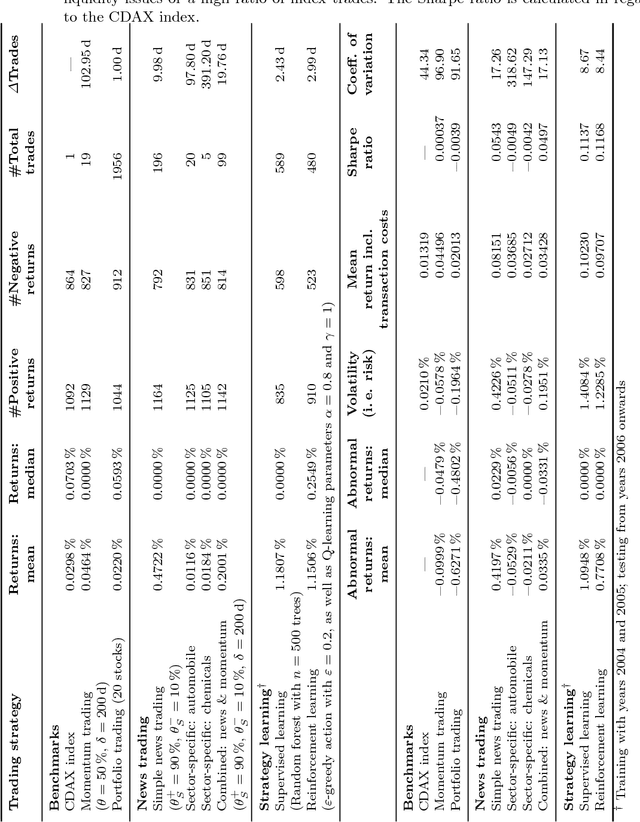

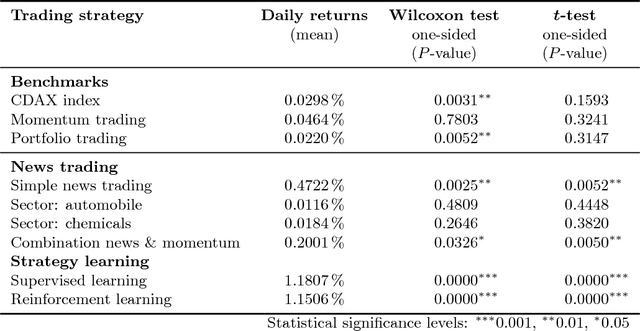
The marvel of markets lies in the fact that dispersed information is instantaneously processed and used to adjust the price of goods, services and assets. Financial markets are particularly efficient when it comes to processing information; such information is typically embedded in textual news that is then interpreted by investors. Quite recently, researchers have started to automatically determine news sentiment in order to explain stock price movements. Interestingly, this so-called news sentiment works fairly well in explaining stock returns. In this paper, we design trading strategies that utilize textual news in order to obtain profits on the basis of novel information entering the market. We thus propose approaches for automated decision-making based on supervised and reinforcement learning. Altogether, we demonstrate how news-based data can be incorporated into an investment system.
IIIDYT at SemEval-2018 Task 3: Irony detection in English tweets
Apr 22, 2018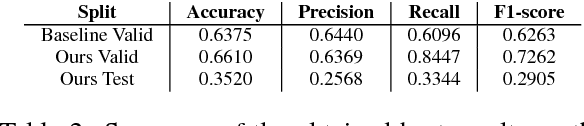
In this paper we introduce our system for the task of Irony detection in English tweets, a part of SemEval 2018. We propose representation learning approach that relies on a multi-layered bidirectional LSTM, without using external features that provide additional semantic information. Although our model is able to outperform the baseline in the validation set, our results show limited generalization power over the test set. Given the limited size of the dataset, we think the usage of more pre-training schemes would greatly improve the obtained results.
Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection
Jun 15, 2017
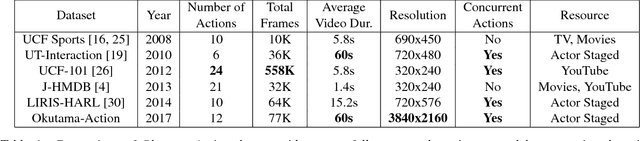
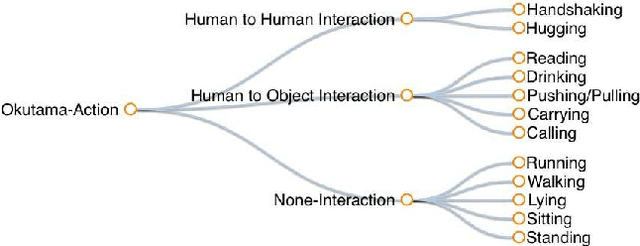
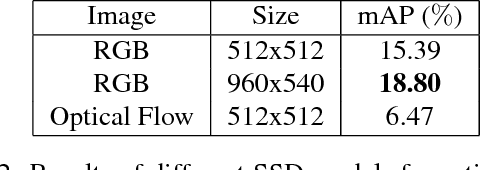
Despite significant progress in the development of human action detection datasets and algorithms, no current dataset is representative of real-world aerial view scenarios. We present Okutama-Action, a new video dataset for aerial view concurrent human action detection. It consists of 43 minute-long fully-annotated sequences with 12 action classes. Okutama-Action features many challenges missing in current datasets, including dynamic transition of actions, significant changes in scale and aspect ratio, abrupt camera movement, as well as multi-labeled actors. As a result, our dataset is more challenging than existing ones, and will help push the field forward to enable real-world applications.