 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Likelihood Gaussian Process Latent Variable Model
Nov 19, 2018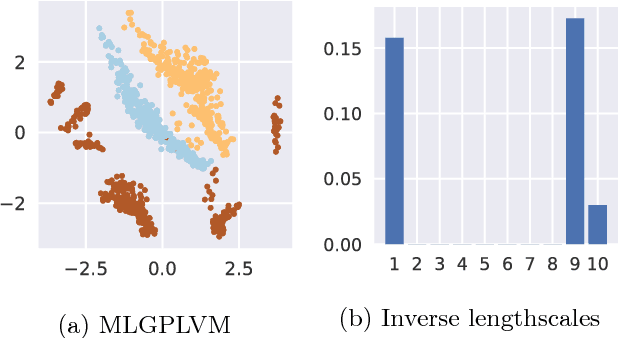
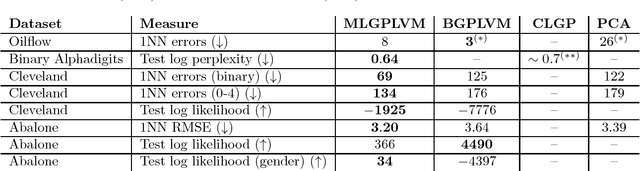
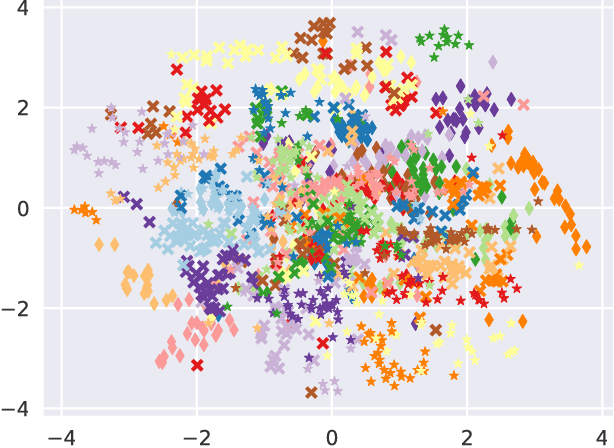
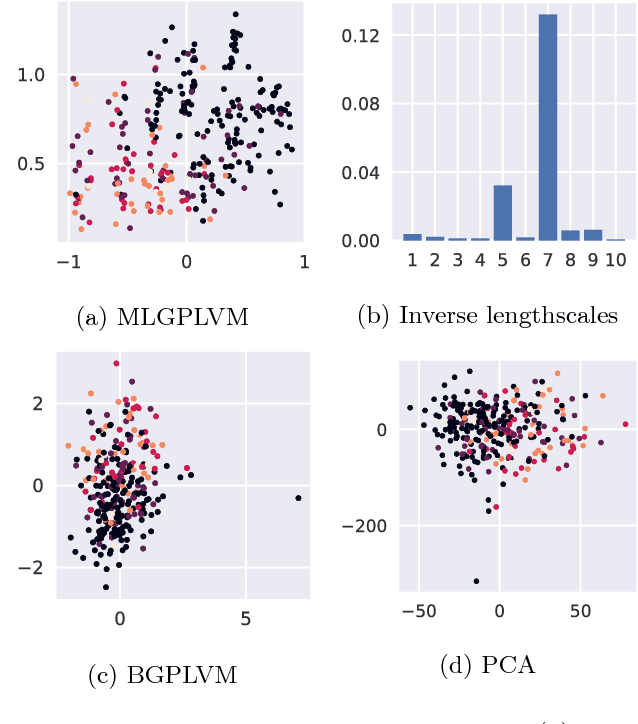
We present the Mixed Likelihood Gaussian process latent variable model (GP-LVM), capable of modeling data with attributes of different types. The standard formulation of GP-LVM assumes that each observation is drawn from a Gaussian distribution, which makes the model unsuited for data with e.g. categorical or nominal attributes. Our model, for which we use a sampling based variational inference, instead assumes a separate likelihood for each observed dimension. This formulation results in more meaningful latent representations, and give better predictive performance for real world data with dimensions of different types.
Real-Time Multiple Object Tracking - A Study on the Importance of Speed
Oct 02, 2017
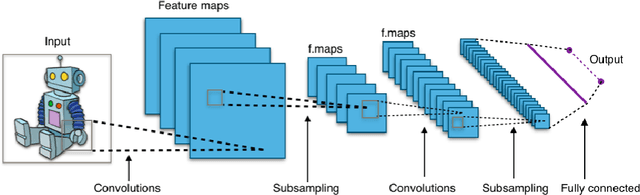


In this project, we implement a multiple object tracker, following the tracking-by-detection paradigm, as an extension of an existing method. It works by modelling the movement of objects by solving the filtering problem, and associating detections with predicted new locations in new frames using the Hungarian algorithm. Three different similarity measures are used, which use the location and shape of the bounding boxes. Compared to other trackers on the MOTChallenge leaderboard, our method, referred to as C++SORT, is the fastest non-anonymous submission, while also achieving decent score on other metrics. By running our model on the Okutama-Action dataset, sampled at different frame-rates, we show that the performance is greatly reduced when running the model - including detecting objects - in real-time. In most metrics, the score is reduced by 50%, but in certain cases as much as 90%. We argue that this indicates that other, slower methods could not be used for tracking in real-time, but that more research is required specifically on this.
Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection
Jun 15, 2017
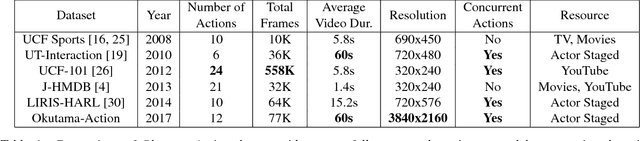
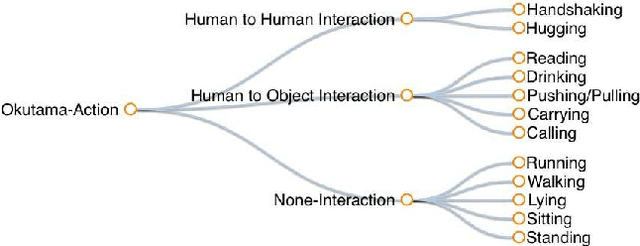
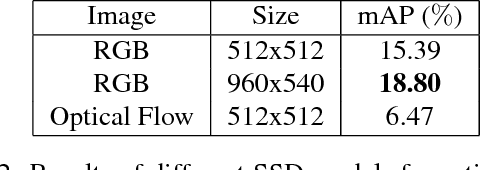
Despite significant progress in the development of human action detection datasets and algorithms, no current dataset is representative of real-world aerial view scenarios. We present Okutama-Action, a new video dataset for aerial view concurrent human action detection. It consists of 43 minute-long fully-annotated sequences with 12 action classes. Okutama-Action features many challenges missing in current datasets, including dynamic transition of actions, significant changes in scale and aspect ratio, abrupt camera movement, as well as multi-labeled actors. As a result, our dataset is more challenging than existing ones, and will help push the field forward to enable real-world applications.