 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023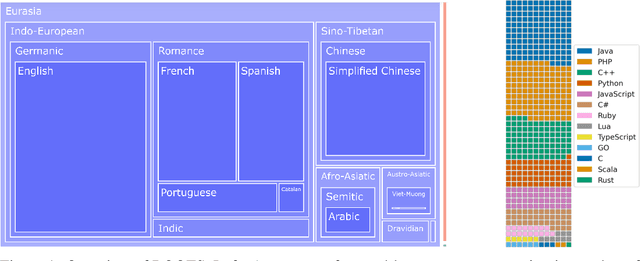


As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
Deep learning for affective computing: text-based emotion recognition in decision support
Sep 10, 2018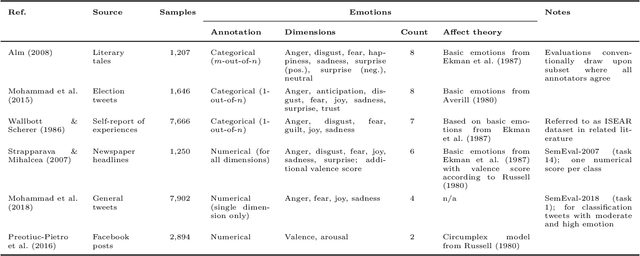
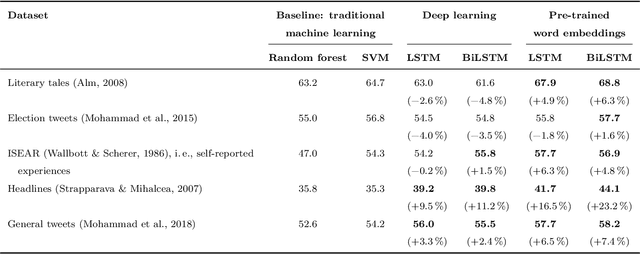
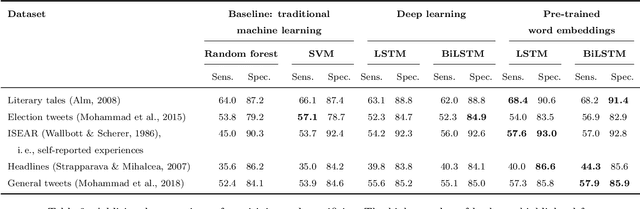
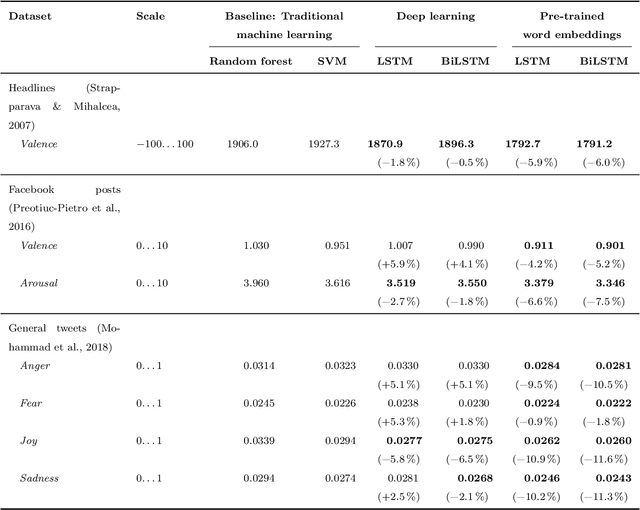
Emotions widely affect human decision-making. This fact is taken into account by affective computing with the goal of tailoring decision support to the emotional states of individuals. However, the accurate recognition of emotions within narrative documents presents a challenging undertaking due to the complexity and ambiguity of language. Performance improvements can be achieved through deep learning; yet, as demonstrated in this paper, the specific nature of this task requires the customization of recurrent neural networks with regard to bidirectional processing, dropout layers as a means of regularization, and weighted loss functions. In addition, we propose sent2affect, a tailored form of transfer learning for affective computing: here the network is pre-trained for a different task (i.e. sentiment analysis), while the output layer is subsequently tuned to the task of emotion recognition. The resulting performance is evaluated in a holistic setting across 6 benchmark datasets, where we find that both recurrent neural networks and transfer learning consistently outperform traditional machine learning. Altogether, the findings have considerable implications for the use of affective computing.
IIIDYT at SemEval-2018 Task 3: Irony detection in English tweets
Apr 22, 2018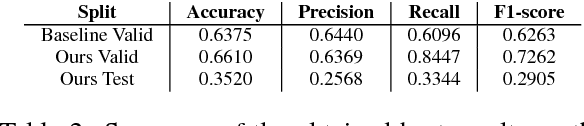
In this paper we introduce our system for the task of Irony detection in English tweets, a part of SemEval 2018. We propose representation learning approach that relies on a multi-layered bidirectional LSTM, without using external features that provide additional semantic information. Although our model is able to outperform the baseline in the validation set, our results show limited generalization power over the test set. Given the limited size of the dataset, we think the usage of more pre-training schemes would greatly improve the obtained results.