 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitch-Conditioned Instrument Sound Synthesis From an Interactive Timbre Latent Space
Oct 05, 2025This paper presents a novel approach to neural instrument sound synthesis using a two-stage semi-supervised learning framework capable of generating pitch-accurate, high-quality music samples from an expressive timbre latent space. Existing approaches that achieve sufficient quality for music production often rely on high-dimensional latent representations that are difficult to navigate and provide unintuitive user experiences. We address this limitation through a two-stage training paradigm: first, we train a pitch-timbre disentangled 2D representation of audio samples using a Variational Autoencoder; second, we use this representation as conditioning input for a Transformer-based generative model. The learned 2D latent space serves as an intuitive interface for navigating and exploring the sound landscape. We demonstrate that the proposed method effectively learns a disentangled timbre space, enabling expressive and controllable audio generation with reliable pitch conditioning. Experimental results show the model's ability to capture subtle variations in timbre while maintaining a high degree of pitch accuracy. The usability of our method is demonstrated in an interactive web application, highlighting its potential as a step towards future music production environments that are both intuitive and creatively empowering: https://pgesam.faresschulz.com
Leveraging YOLO-World and GPT-4V LMMs for Zero-Shot Person Detection and Action Recognition in Drone Imagery
Apr 02, 2024In this article, we explore the potential of zero-shot Large Multimodal Models (LMMs) in the domain of drone perception. We focus on person detection and action recognition tasks and evaluate two prominent LMMs, namely YOLO-World and GPT-4V(ision) using a publicly available dataset captured from aerial views. Traditional deep learning approaches rely heavily on large and high-quality training datasets. However, in certain robotic settings, acquiring such datasets can be resource-intensive or impractical within a reasonable timeframe. The flexibility of prompt-based Large Multimodal Models (LMMs) and their exceptional generalization capabilities have the potential to revolutionize robotics applications in these scenarios. Our findings suggest that YOLO-World demonstrates good detection performance. GPT-4V struggles with accurately classifying action classes but delivers promising results in filtering out unwanted region proposals and in providing a general description of the scenery. This research represents an initial step in leveraging LMMs for drone perception and establishes a foundation for future investigations in this area.
YOLO -- You only look 10647 times
Jan 21, 2022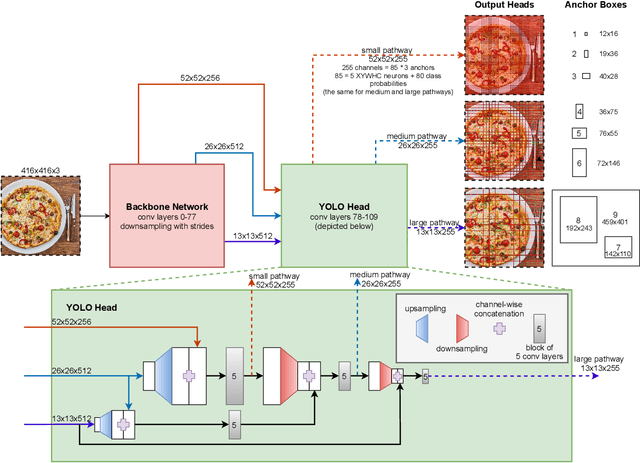



With this work we are explaining the "You Only Look Once" (YOLO) single-stage object detection approach as a parallel classification of 10647 fixed region proposals. We support this view by showing that each of YOLOs output pixel is attentive to a specific sub-region of previous layers, comparable to a local region proposal. This understanding reduces the conceptual gap between YOLO-like single-stage object detection models, RCNN-like two-stage region proposal based models, and ResNet-like image classification models. In addition, we created interactive exploration tools for a better visual understanding of the YOLO information processing streams: https://limchr.github.io/yolo_visualization
Critic Guided Segmentation of Rewarding Objects in First-Person Views
Jul 20, 2021
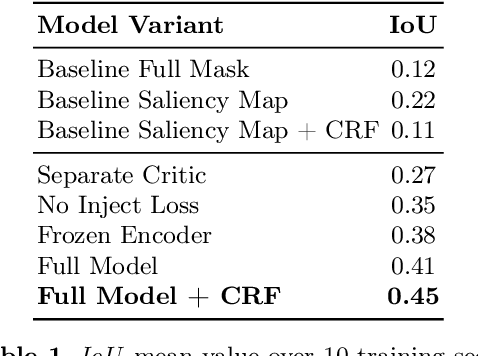

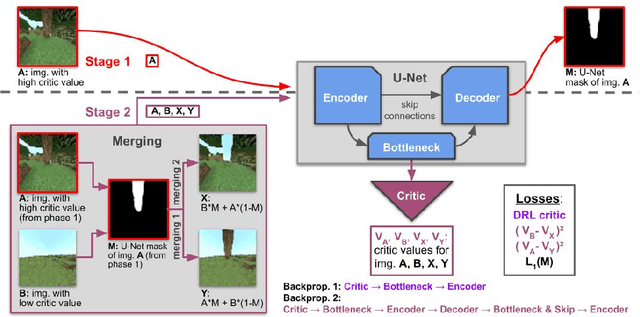
This work discusses a learning approach to mask rewarding objects in images using sparse reward signals from an imitation learning dataset. For that, we train an Hourglass network using only feedback from a critic model. The Hourglass network learns to produce a mask to decrease the critic's score of a high score image and increase the critic's score of a low score image by swapping the masked areas between these two images. We trained the model on an imitation learning dataset from the NeurIPS 2020 MineRL Competition Track, where our model learned to mask rewarding objects in a complex interactive 3D environment with a sparse reward signal. This approach was part of the 1st place winning solution in this competition. Video demonstration and code: https://rebrand.ly/critic-guided-segmentation