 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO -- You only look 10647 times
Jan 21, 2022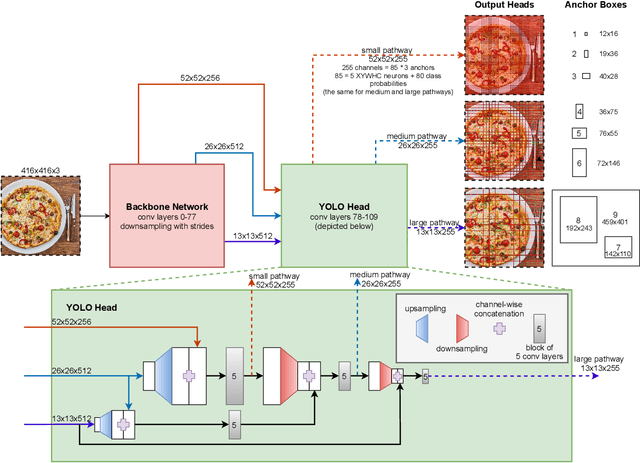



With this work we are explaining the "You Only Look Once" (YOLO) single-stage object detection approach as a parallel classification of 10647 fixed region proposals. We support this view by showing that each of YOLOs output pixel is attentive to a specific sub-region of previous layers, comparable to a local region proposal. This understanding reduces the conceptual gap between YOLO-like single-stage object detection models, RCNN-like two-stage region proposal based models, and ResNet-like image classification models. In addition, we created interactive exploration tools for a better visual understanding of the YOLO information processing streams: https://limchr.github.io/yolo_visualization
Critic Guided Segmentation of Rewarding Objects in First-Person Views
Jul 20, 2021
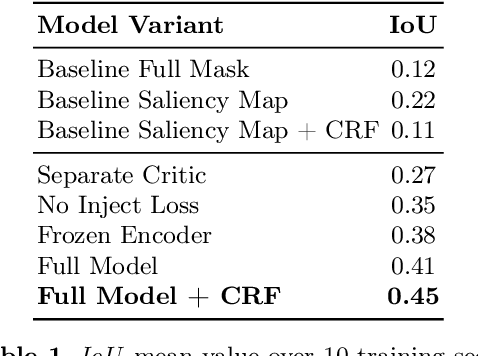

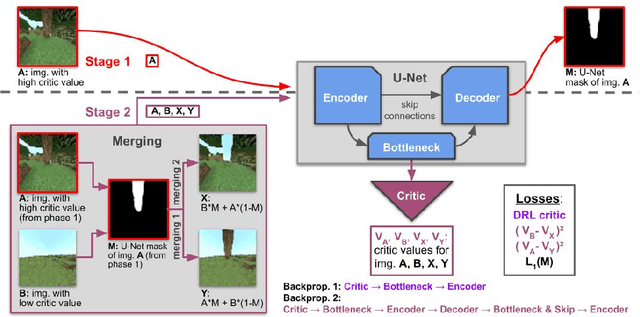
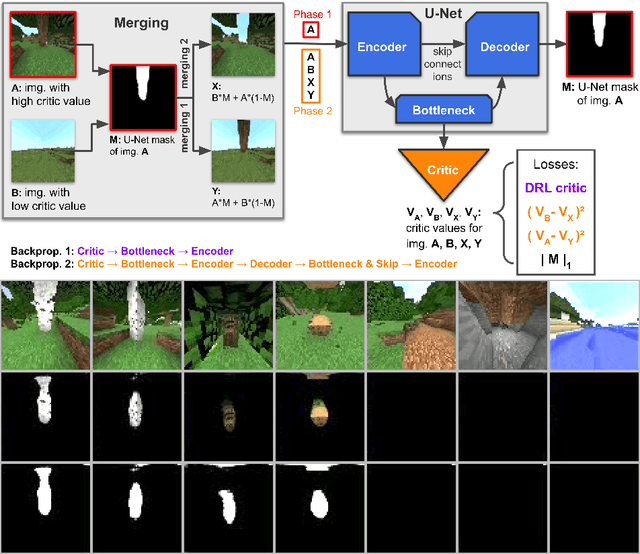
This work discusses a learning approach to mask rewarding objects in images using sparse reward signals from an imitation learning dataset. For that, we train an Hourglass network using only feedback from a critic model. The Hourglass network learns to produce a mask to decrease the critic's score of a high score image and increase the critic's score of a low score image by swapping the masked areas between these two images. We trained the model on an imitation learning dataset from the NeurIPS 2020 MineRL Competition Track, where our model learned to mask rewarding objects in a complex interactive 3D environment with a sparse reward signal. This approach was part of the 1st place winning solution in this competition. Video demonstration and code: https://rebrand.ly/critic-guided-segmentation
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021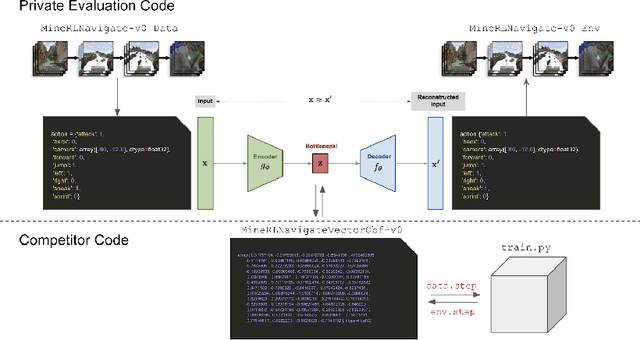

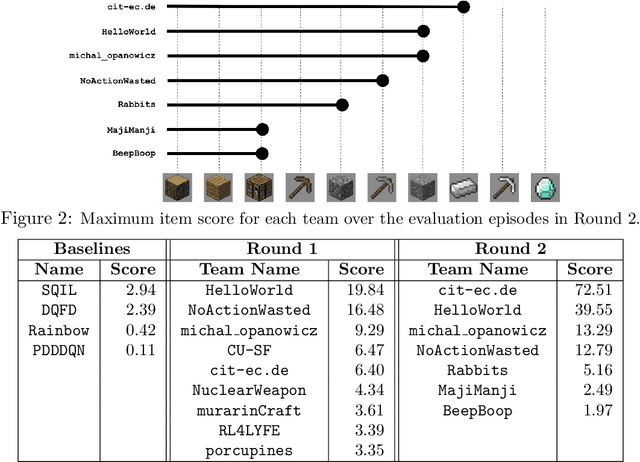
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Solving Physics Puzzles by Reasoning about Paths
Nov 14, 2020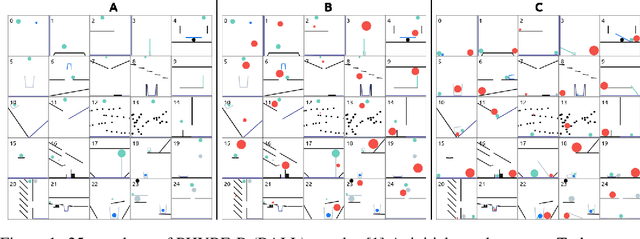

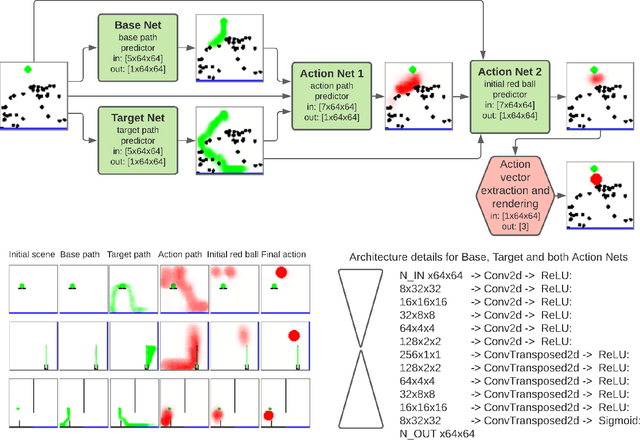
We propose a new deep learning model for goal-driven tasks that require intuitive physical reasoning and intervention in the scene to achieve a desired end goal. Its modular structure is motivated by hypothesizing a sequence of intuitive steps that humans apply when trying to solve such a task. The model first predicts the path the target object would follow without intervention and the path the target object should follow in order to solve the task. Next, it predicts the desired path of the action object and generates the placement of the action object. All components of the model are trained jointly in a supervised way; each component receives its own learning signal but learning signals are also backpropagated through the entire architecture. To evaluate the model we use PHYRE - a benchmark test for goal-driven physical reasoning in 2D mechanics puzzles.