 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models Trained on Code
Jul 14, 2021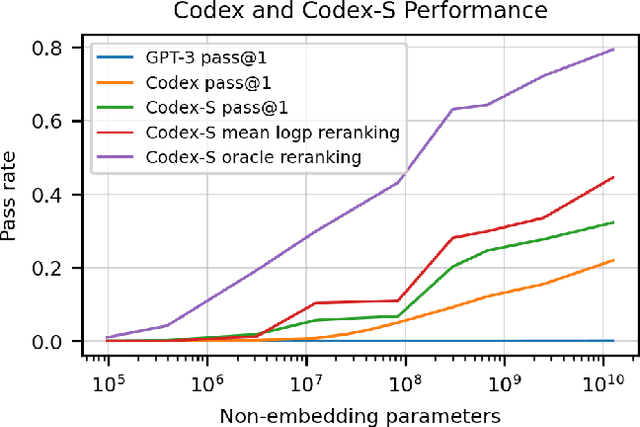
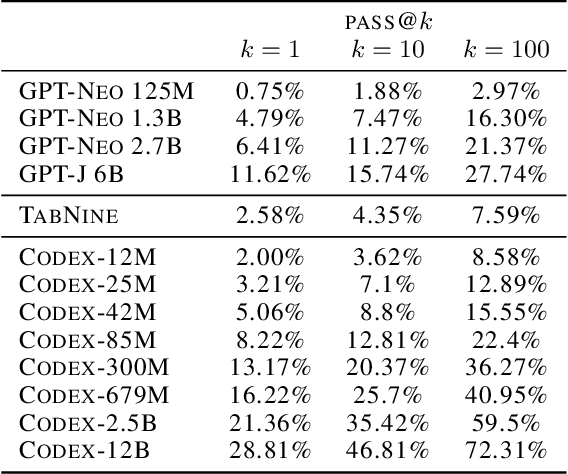
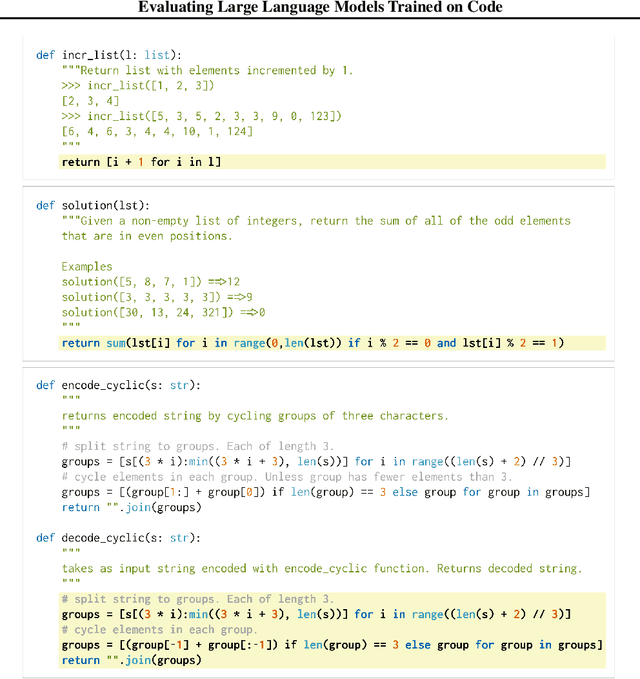
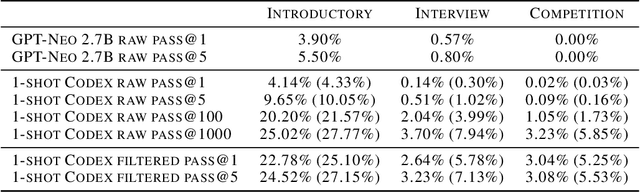
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Multi-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
Jun 28, 2021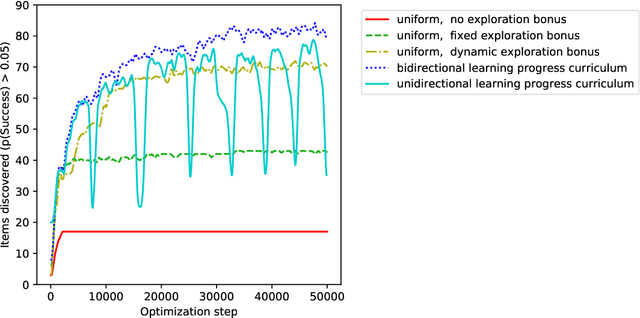
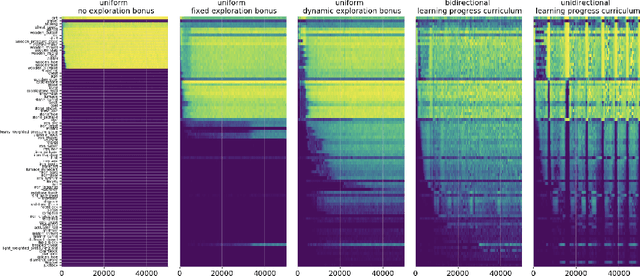
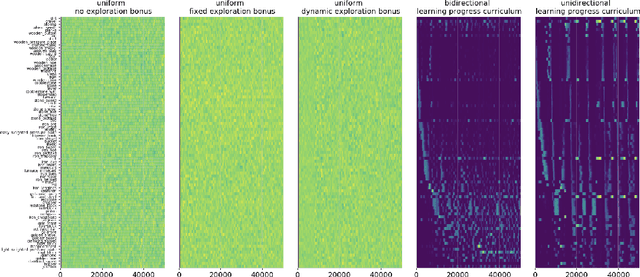
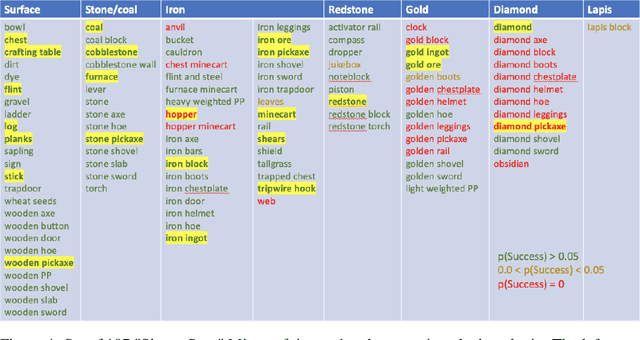
An important challenge in reinforcement learning is training agents that can solve a wide variety of tasks. If tasks depend on each other (e.g. needing to learn to walk before learning to run), curriculum learning can speed up learning by focusing on the next best task to learn. We explore curriculum learning in a complex, visual domain with many hard exploration challenges: Minecraft. We find that learning progress (defined as a change in success probability of a task) is a reliable measure of learnability for automatically constructing an effective curriculum. We introduce a learning-progress based curriculum and test it on a complex reinforcement learning problem (called "Simon Says") where an agent is instructed to obtain a desired goal item. Many of the required skills depend on each other. Experiments demonstrate that: (1) a within-episode exploration bonus for obtaining new items improves performance, (2) dynamically adjusting this bonus across training such that it only applies to items the agent cannot reliably obtain yet further increases performance, (3) the learning-progress based curriculum elegantly follows the learning curve of the agent, and (4) when the learning-progress based curriculum is combined with the dynamic exploration bonus it learns much more efficiently and obtains far higher performance than uniform baselines. These results suggest that combining intra-episode and across-training exploration bonuses with learning progress creates a promising method for automated curriculum generation, which may substantially increase our ability to train more capable, generally intelligent agents.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021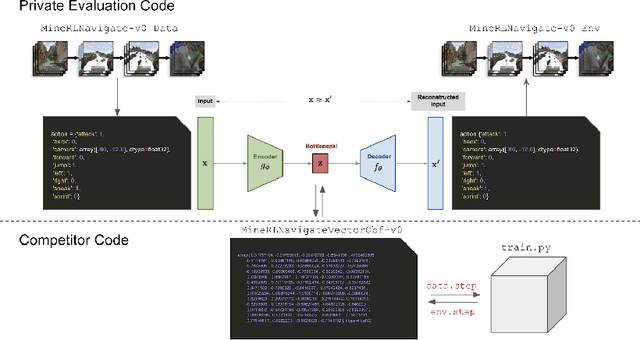

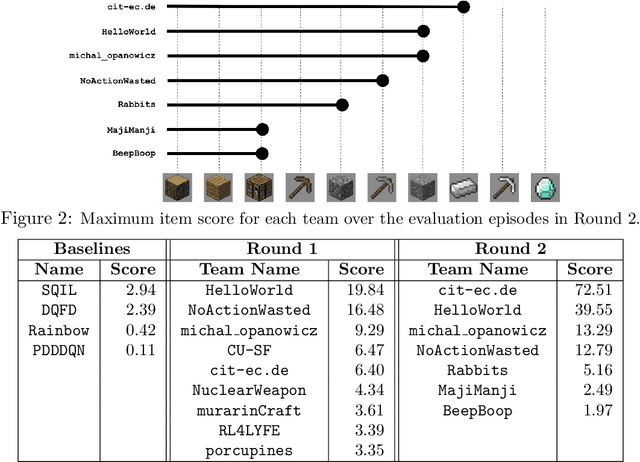
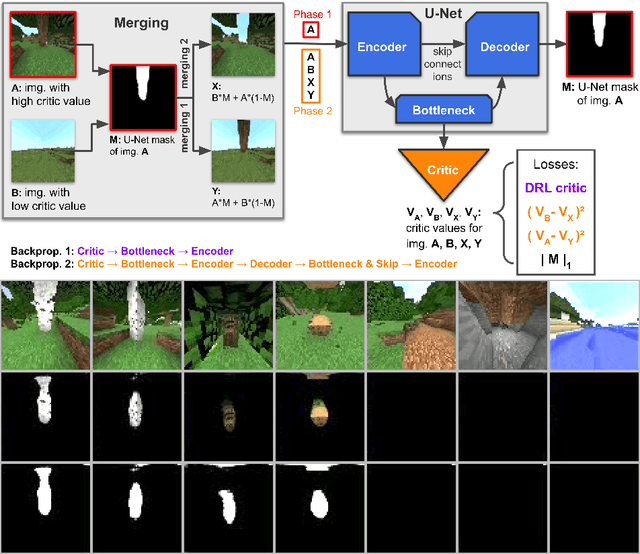
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen Benchmark
Mar 29, 2021
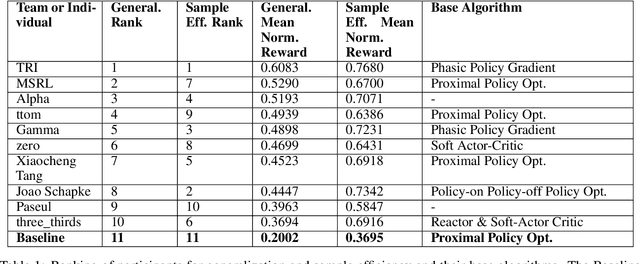
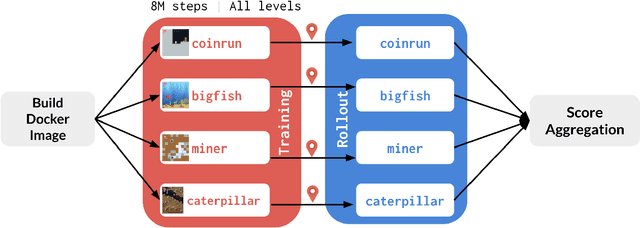
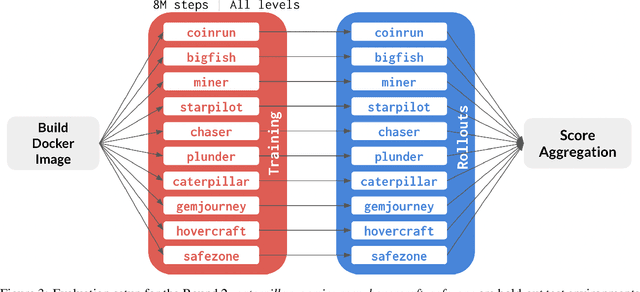
The NeurIPS 2020 Procgen Competition was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. Generalization remains one of the most fundamental challenges in deep reinforcement learning, and yet we do not have enough benchmarks to measure the progress of the community on Generalization in Reinforcement Learning. We present the design of a centralized benchmark for Reinforcement Learning which can help measure Sample Efficiency and Generalization in Reinforcement Learning by doing end to end evaluation of the training and rollout phases of thousands of user submitted code bases in a scalable way. We designed the benchmark on top of the already existing Procgen Benchmark by defining clear tasks and standardizing the end to end evaluation setups. The design aims to maximize the flexibility available for researchers who wish to design future iterations of such benchmarks, and yet imposes necessary practical constraints to allow for a system like this to scale. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS.