 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
AutoDIME: Automatic Design of Interesting Multi-Agent Environments
Mar 04, 2022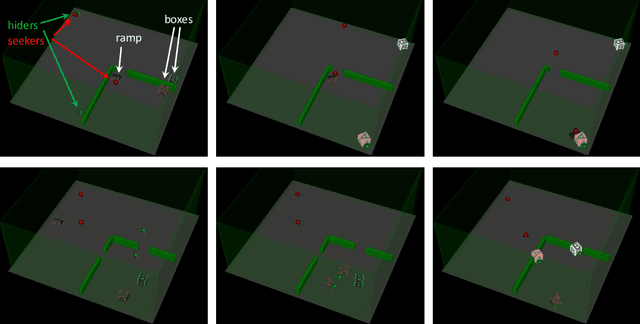
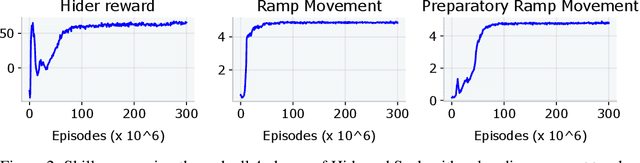
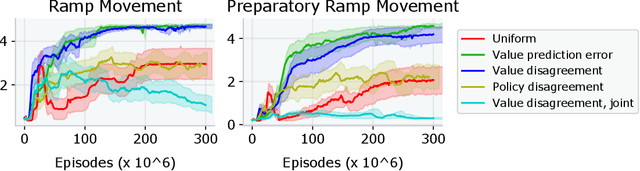

Designing a distribution of environments in which RL agents can learn interesting and useful skills is a challenging and poorly understood task, for multi-agent environments the difficulties are only exacerbated. One approach is to train a second RL agent, called a teacher, who samples environments that are conducive for the learning of student agents. However, most previous proposals for teacher rewards do not generalize straightforwardly to the multi-agent setting. We examine a set of intrinsic teacher rewards derived from prediction problems that can be applied in multi-agent settings and evaluate them in Mujoco tasks such as multi-agent Hide and Seek as well as a diagnostic single-agent maze task. Of the intrinsic rewards considered we found value disagreement to be most consistent across tasks, leading to faster and more reliable emergence of advanced skills in Hide and Seek and the maze task. Another candidate intrinsic reward considered, value prediction error, also worked well in Hide and Seek but was susceptible to noisy-TV style distractions in stochastic environments. Policy disagreement performed well in the maze task but did not speed up learning in Hide and Seek. Our results suggest that intrinsic teacher rewards, and in particular value disagreement, are a promising approach for automating both single and multi-agent environment design.
Multi-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
Jun 28, 2021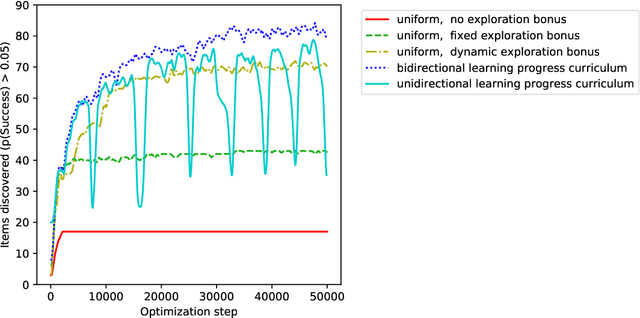
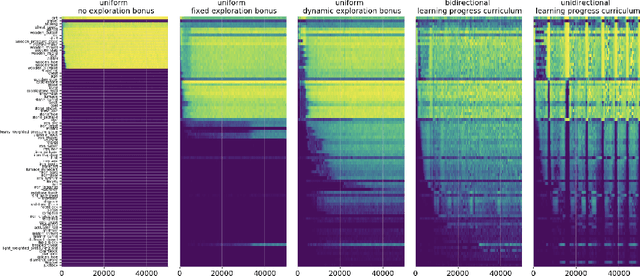
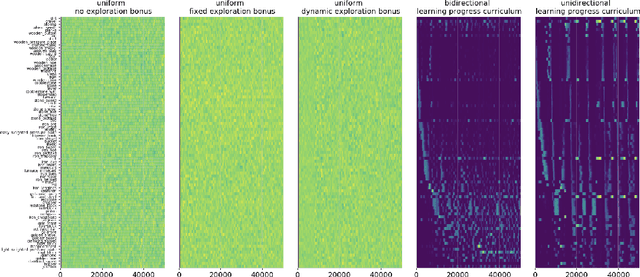
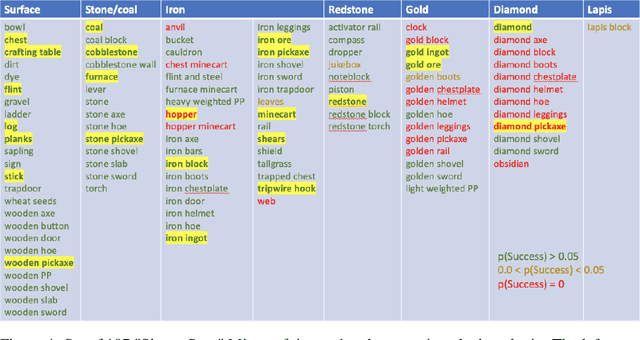
An important challenge in reinforcement learning is training agents that can solve a wide variety of tasks. If tasks depend on each other (e.g. needing to learn to walk before learning to run), curriculum learning can speed up learning by focusing on the next best task to learn. We explore curriculum learning in a complex, visual domain with many hard exploration challenges: Minecraft. We find that learning progress (defined as a change in success probability of a task) is a reliable measure of learnability for automatically constructing an effective curriculum. We introduce a learning-progress based curriculum and test it on a complex reinforcement learning problem (called "Simon Says") where an agent is instructed to obtain a desired goal item. Many of the required skills depend on each other. Experiments demonstrate that: (1) a within-episode exploration bonus for obtaining new items improves performance, (2) dynamically adjusting this bonus across training such that it only applies to items the agent cannot reliably obtain yet further increases performance, (3) the learning-progress based curriculum elegantly follows the learning curve of the agent, and (4) when the learning-progress based curriculum is combined with the dynamic exploration bonus it learns much more efficiently and obtains far higher performance than uniform baselines. These results suggest that combining intra-episode and across-training exploration bonuses with learning progress creates a promising method for automated curriculum generation, which may substantially increase our ability to train more capable, generally intelligent agents.
Emergent Tool Use From Multi-Agent Autocurricula
Sep 17, 2019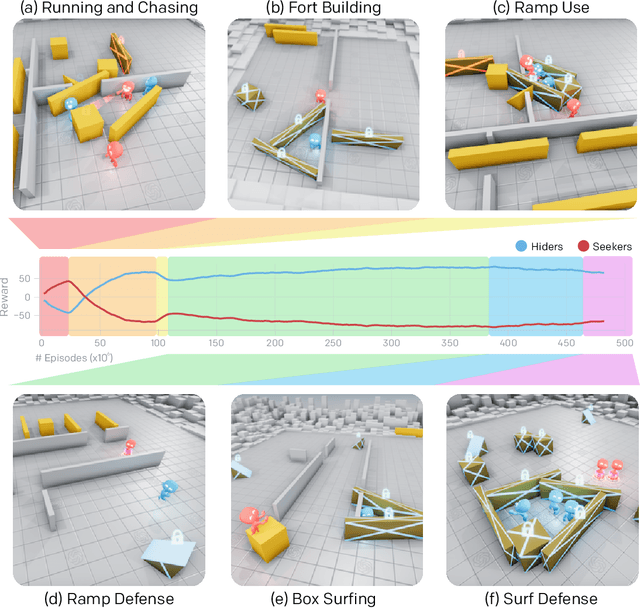
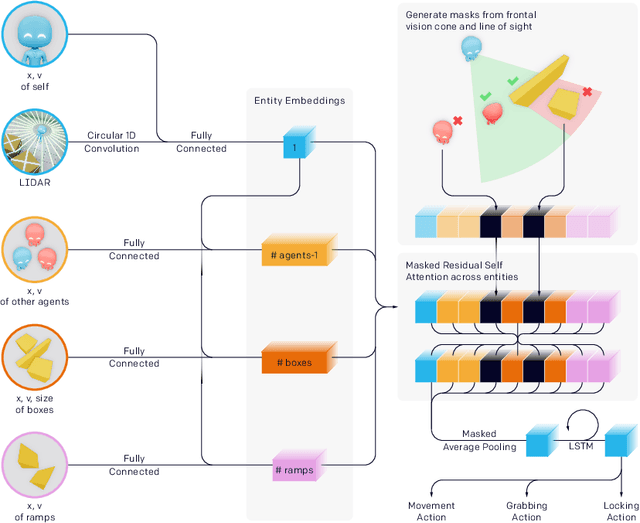
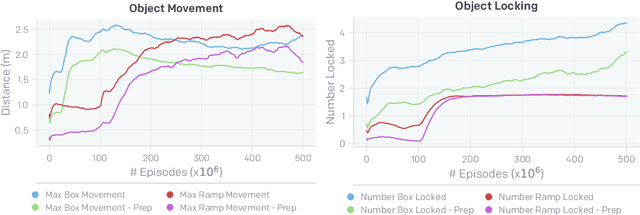
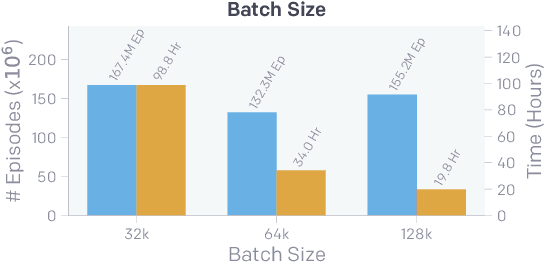
Through multi-agent competition, the simple objective of hide-and-seek, and standard reinforcement learning algorithms at scale, we find that agents create a self-supervised autocurriculum inducing multiple distinct rounds of emergent strategy, many of which require sophisticated tool use and coordination. We find clear evidence of six emergent phases in agent strategy in our environment, each of which creates a new pressure for the opposing team to adapt; for instance, agents learn to build multi-object shelters using moveable boxes which in turn leads to agents discovering that they can overcome obstacles using ramps. We further provide evidence that multi-agent competition may scale better with increasing environment complexity and leads to behavior that centers around far more human-relevant skills than other self-supervised reinforcement learning methods such as intrinsic motivation. Finally, we propose transfer and fine-tuning as a way to quantitatively evaluate targeted capabilities, and we compare hide-and-seek agents to both intrinsic motivation and random initialization baselines in a suite of domain-specific intelligence tests.