 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision
Dec 14, 2023



Widely used alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on the ability of humans to supervise model behavior - for example, to evaluate whether a model faithfully followed instructions or generated safe outputs. However, future superhuman models will behave in complex ways too difficult for humans to reliably evaluate; humans will only be able to weakly supervise superhuman models. We study an analogy to this problem: can weak model supervision elicit the full capabilities of a much stronger model? We test this using a range of pretrained language models in the GPT-4 family on natural language processing (NLP), chess, and reward modeling tasks. We find that when we naively finetune strong pretrained models on labels generated by a weak model, they consistently perform better than their weak supervisors, a phenomenon we call weak-to-strong generalization. However, we are still far from recovering the full capabilities of strong models with naive finetuning alone, suggesting that techniques like RLHF may scale poorly to superhuman models without further work. We find that simple methods can often significantly improve weak-to-strong generalization: for example, when finetuning GPT-4 with a GPT-2-level supervisor and an auxiliary confidence loss, we can recover close to GPT-3.5-level performance on NLP tasks. Our results suggest that it is feasible to make empirical progress today on a fundamental challenge of aligning superhuman models.
Video PreTraining : Learning to Act by Watching Unlabeled Online Videos
Jun 23, 2022

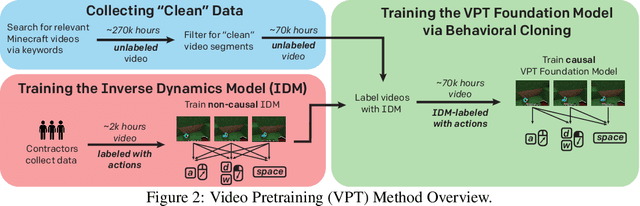
Pretraining on noisy, internet-scale datasets has been heavily studied as a technique for training models with broad, general capabilities for text, images, and other modalities. However, for many sequential decision domains such as robotics, video games, and computer use, publicly available data does not contain the labels required to train behavioral priors in the same way. We extend the internet-scale pretraining paradigm to sequential decision domains through semi-supervised imitation learning wherein agents learn to act by watching online unlabeled videos. Specifically, we show that with a small amount of labeled data we can train an inverse dynamics model accurate enough to label a huge unlabeled source of online data -- here, online videos of people playing Minecraft -- from which we can then train a general behavioral prior. Despite using the native human interface (mouse and keyboard at 20Hz), we show that this behavioral prior has nontrivial zero-shot capabilities and that it can be fine-tuned, with both imitation learning and reinforcement learning, to hard-exploration tasks that are impossible to learn from scratch via reinforcement learning. For many tasks our models exhibit human-level performance, and we are the first to report computer agents that can craft diamond tools, which can take proficient humans upwards of 20 minutes (24,000 environment actions) of gameplay to accomplish.
Multi-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
Jun 28, 2021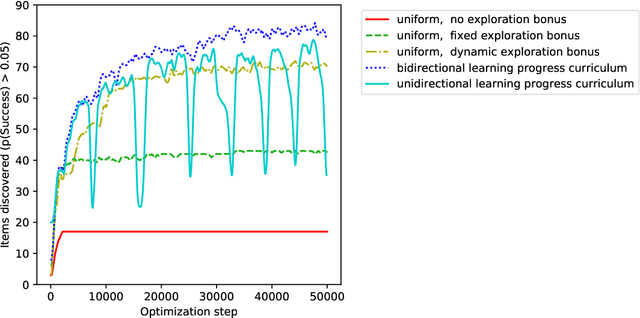
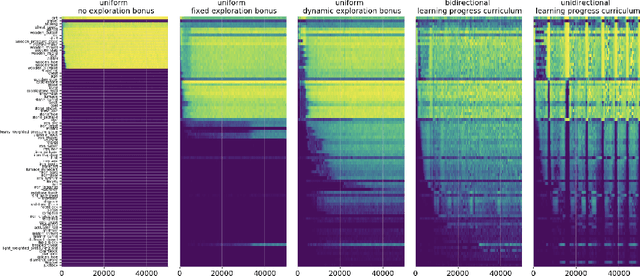
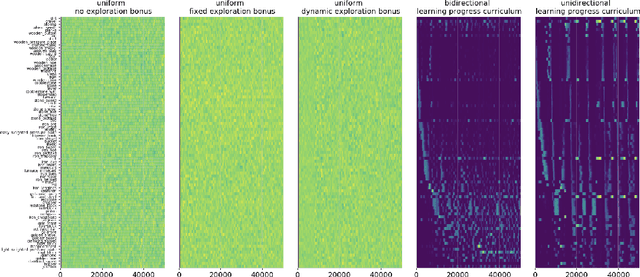
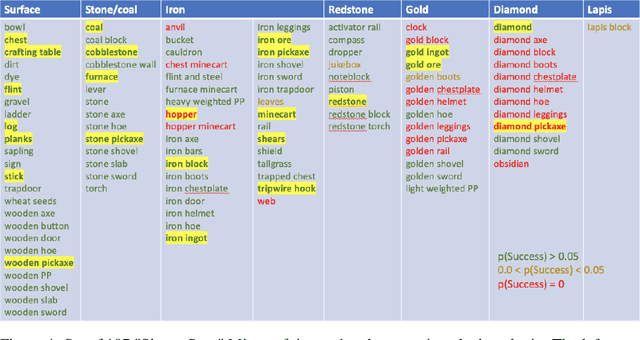
An important challenge in reinforcement learning is training agents that can solve a wide variety of tasks. If tasks depend on each other (e.g. needing to learn to walk before learning to run), curriculum learning can speed up learning by focusing on the next best task to learn. We explore curriculum learning in a complex, visual domain with many hard exploration challenges: Minecraft. We find that learning progress (defined as a change in success probability of a task) is a reliable measure of learnability for automatically constructing an effective curriculum. We introduce a learning-progress based curriculum and test it on a complex reinforcement learning problem (called "Simon Says") where an agent is instructed to obtain a desired goal item. Many of the required skills depend on each other. Experiments demonstrate that: (1) a within-episode exploration bonus for obtaining new items improves performance, (2) dynamically adjusting this bonus across training such that it only applies to items the agent cannot reliably obtain yet further increases performance, (3) the learning-progress based curriculum elegantly follows the learning curve of the agent, and (4) when the learning-progress based curriculum is combined with the dynamic exploration bonus it learns much more efficiently and obtains far higher performance than uniform baselines. These results suggest that combining intra-episode and across-training exploration bonuses with learning progress creates a promising method for automated curriculum generation, which may substantially increase our ability to train more capable, generally intelligent agents.
Open Questions in Creating Safe Open-ended AI: Tensions Between Control and Creativity
Jun 12, 2020Artificial life originated and has long studied the topic of open-ended evolution, which seeks the principles underlying artificial systems that innovate continually, inspired by biological evolution. Recently, interest has grown within the broader field of AI in a generalization of open-ended evolution, here called open-ended search, wherein such questions of open-endedness are explored for advancing AI, whatever the nature of the underlying search algorithm (e.g. evolutionary or gradient-based). For example, open-ended search might design new architectures for neural networks, new reinforcement learning algorithms, or most ambitiously, aim at designing artificial general intelligence. This paper proposes that open-ended evolution and artificial life have much to contribute towards the understanding of open-ended AI, focusing here in particular on the safety of open-ended search. The idea is that AI systems are increasingly applied in the real world, often producing unintended harms in the process, which motivates the growing field of AI safety. This paper argues that open-ended AI has its own safety challenges, in particular, whether the creativity of open-ended systems can be productively and predictably controlled. This paper explains how unique safety problems manifest in open-ended search, and suggests concrete contributions and research questions to explore them. The hope is to inspire progress towards creative, useful, and safe open-ended search algorithms.
Reinforcement Learning Under Moral Uncertainty
Jun 08, 2020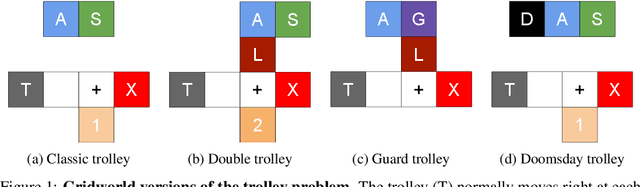
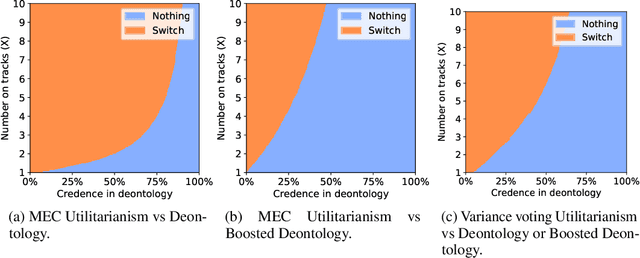
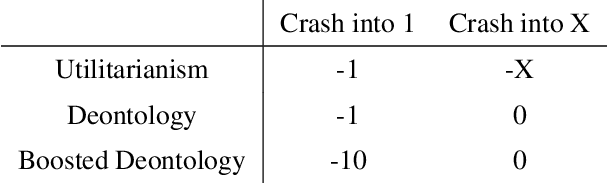
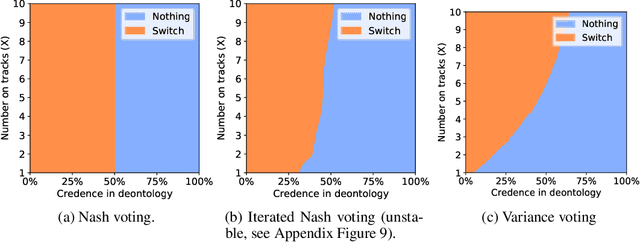
An ambitious goal for artificial intelligence is to create agents that behave ethically: The capacity to abide by human moral norms would greatly expand the context in which autonomous agents could be practically and safely deployed. While ethical agents could be trained through reinforcement, by rewarding correct behavior under a specific moral theory (e.g. utilitarianism), there remains widespread disagreement (both societally and among moral philosophers) about the nature of morality and what ethical theory (if any) is objectively correct. Acknowledging such disagreement, recent work in moral philosophy proposes that ethical behavior requires acting under moral uncertainty, i.e. to take into account when acting that one's credence is split across several plausible ethical theories. Inspired by such work, this paper proposes a formalism that translates such insights to the field of reinforcement learning. Demonstrating the formalism's potential, we then train agents in simple environments to act under moral uncertainty, highlighting how such uncertainty can help curb extreme behavior from commitment to single theories. The overall aim is to draw productive connections from the fields of moral philosophy and machine ethics to that of machine learning, to inspire further research by highlighting a spectrum of machine learning research questions relevant to training ethically capable reinforcement learning agents.
First return then explore
May 14, 2020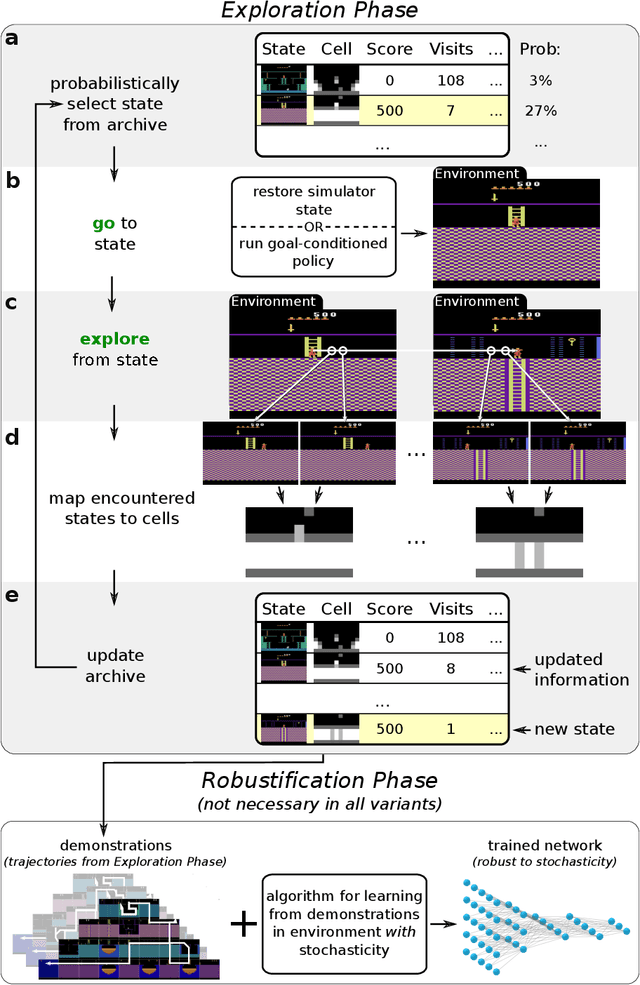
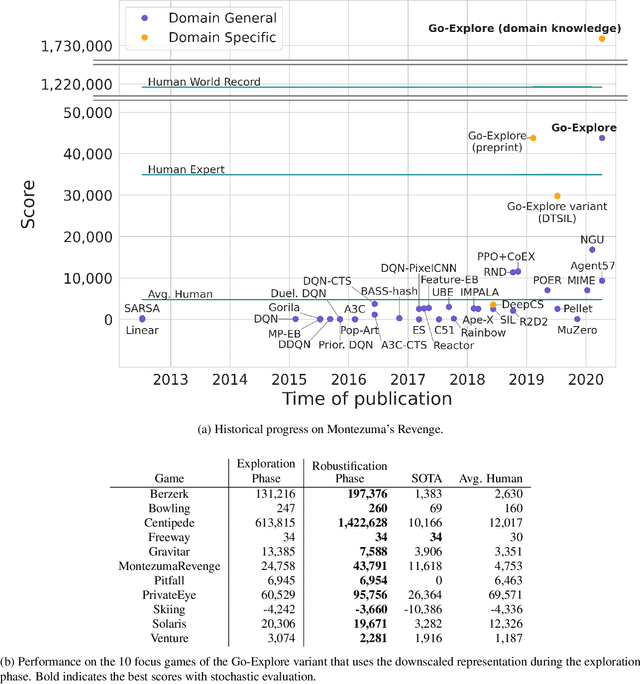
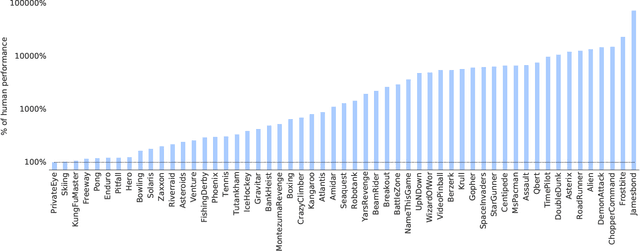
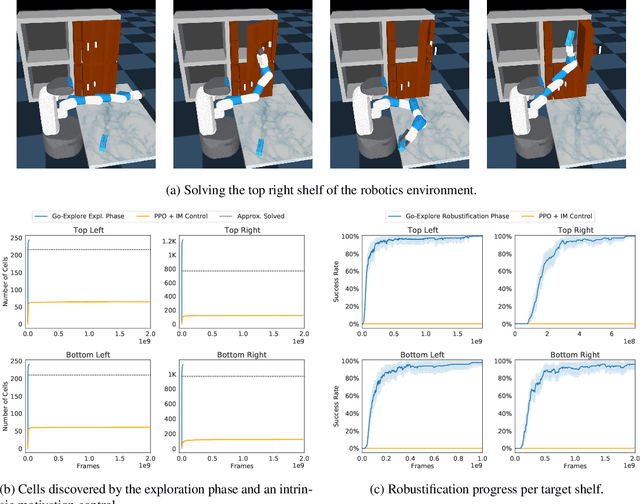
The promise of reinforcement learning is to solve complex sequential decision problems by specifying a high-level reward function only. However, RL algorithms struggle when, as is often the case, simple and intuitive rewards provide sparse and deceptive feedback. Avoiding these pitfalls requires thoroughly exploring the environment, but despite substantial investments by the community, creating algorithms that can do so remains one of the central challenges of the field. We hypothesize that the main impediment to effective exploration originates from algorithms forgetting how to reach previously visited states ("detachment") and from failing to first return to a state before exploring from it ("derailment"). We introduce Go-Explore, a family of algorithms that addresses these two challenges directly through the simple principles of explicitly remembering promising states and first returning to such states before exploring. Go-Explore solves all heretofore unsolved Atari games (those for which algorithms could not previously outperform humans when evaluated following current community standards) and surpasses the state of the art on all hard-exploration games, with orders of magnitude improvements on the grand challenges Montezuma's Revenge and Pitfall. We also demonstrate the practical potential of Go-Explore on a challenging and extremely sparse-reward robotics task. Additionally, we show that adding a goal-conditioned policy can further improve Go-Explore's exploration efficiency and enable it to handle stochasticity throughout training. The striking contrast between the substantial performance gains from Go-Explore and the simplicity of its mechanisms suggests that remembering promising states, returning to them, and exploring from them is a powerful and general approach to exploration, an insight that may prove critical to the creation of truly intelligent learning agents.
Estimating Q(s,s') with Deep Deterministic Dynamics Gradients
Feb 21, 2020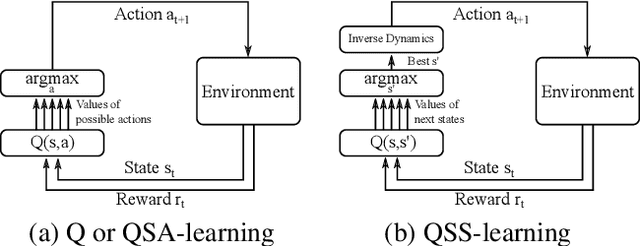
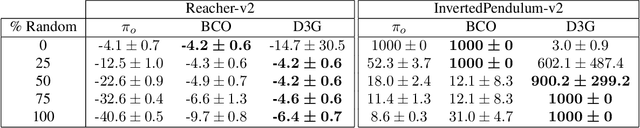
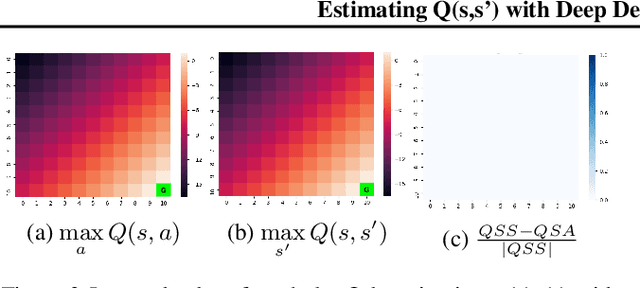
In this paper, we introduce a novel form of value function, $Q(s, s')$, that expresses the utility of transitioning from a state $s$ to a neighboring state $s'$ and then acting optimally thereafter. In order to derive an optimal policy, we develop a forward dynamics model that learns to make next-state predictions that maximize this value. This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies. Code and videos are available at \url{sites.google.com/view/qss-paper}.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

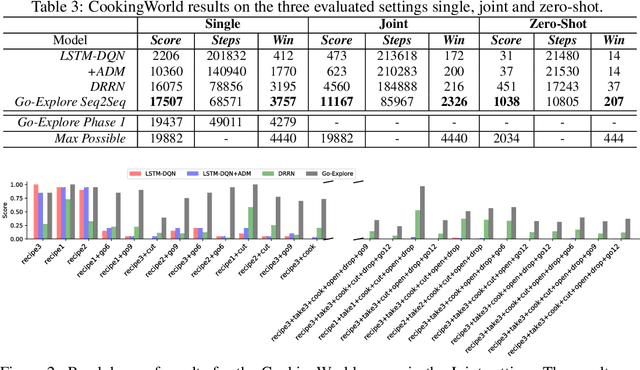
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Go-Explore: a New Approach for Hard-Exploration Problems
Jan 30, 2019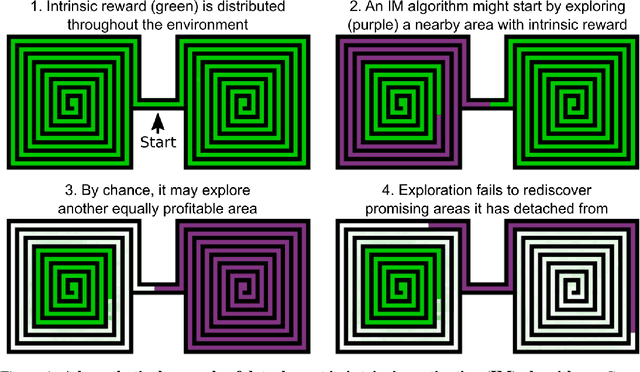



A grand challenge in reinforcement learning is intelligent exploration, especially when rewards are sparse or deceptive. Two Atari games serve as benchmarks for such hard-exploration domains: Montezuma's Revenge and Pitfall. On both games, current RL algorithms perform poorly, even those with intrinsic motivation, which is the dominant method to improve performance on hard-exploration domains. To address this shortfall, we introduce a new algorithm called Go-Explore. It exploits the following principles: (1) remember previously visited states, (2) first return to a promising state (without exploration), then explore from it, and (3) solve simulated environments through any available means (including by introducing determinism), then robustify via imitation learning. The combined effect of these principles is a dramatic performance improvement on hard-exploration problems. On Montezuma's Revenge, Go-Explore scores a mean of over 43k points, almost 4 times the previous state of the art. Go-Explore can also harness human-provided domain knowledge and, when augmented with it, scores a mean of over 650k points on Montezuma's Revenge. Its max performance of nearly 18 million surpasses the human world record, meeting even the strictest definition of "superhuman" performance. On Pitfall, Go-Explore with domain knowledge is the first algorithm to score above zero. Its mean score of almost 60k points exceeds expert human performance. Because Go-Explore produces high-performing demonstrations automatically and cheaply, it also outperforms imitation learning work where humans provide solution demonstrations. Go-Explore opens up many new research directions into improving it and weaving its insights into current RL algorithms. It may also enable progress on previously unsolvable hard-exploration problems in many domains, especially those that harness a simulator during training (e.g. robotics).