 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Apr 29, 2024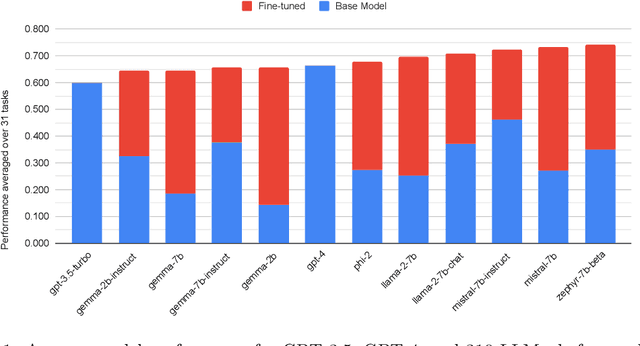


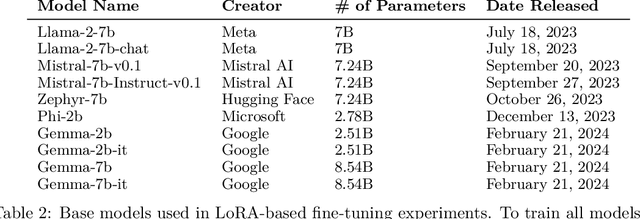
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
Witgenstein's influence on artificial intelligence
Feb 03, 2023We examine how much of the contemporary progress in artificial intelligence (and, specifically, in natural language processing), can be, more or less directly, traced back to the seminal work and ideas of the Austrian-British philosopher Ludwig Wittgenstein, with particular focus on his late views. Discussing Wittgenstein's original theses will give us the chance to survey the state of artificial intelligence, and comment on both its strengths and weaknesses. A similar text appeared first in Spanish as a chapter of CENTENARIO DEL SILENCIO (2021), a book celebrating 100 years since the publication of the Tractatus.
Personalized Benchmarking with the Ludwig Benchmarking Toolkit
Nov 08, 2021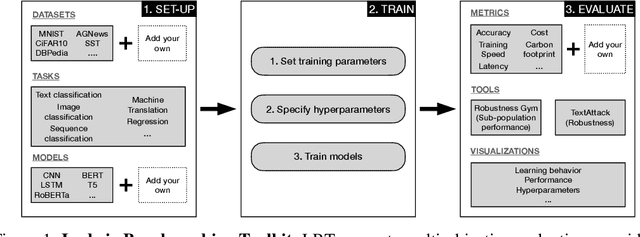
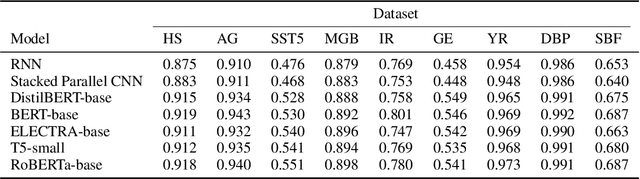
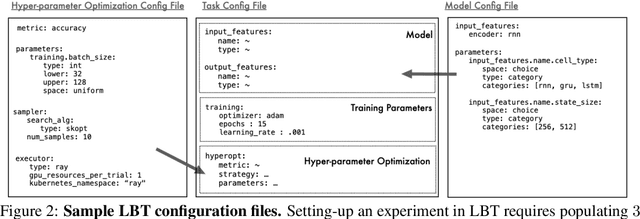
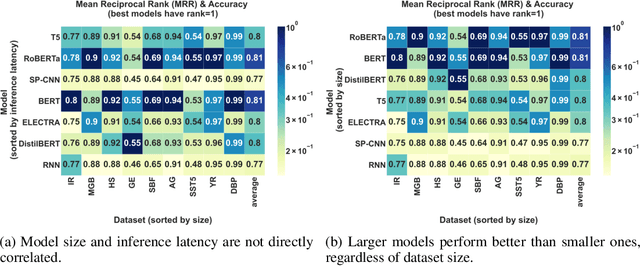
The rapid proliferation of machine learning models across domains and deployment settings has given rise to various communities (e.g. industry practitioners) which seek to benchmark models across tasks and objectives of personal value. Unfortunately, these users cannot use standard benchmark results to perform such value-driven comparisons as traditional benchmarks evaluate models on a single objective (e.g. average accuracy) and fail to facilitate a standardized training framework that controls for confounding variables (e.g. computational budget), making fair comparisons difficult. To address these challenges, we introduce the open-source Ludwig Benchmarking Toolkit (LBT), a personalized benchmarking toolkit for running end-to-end benchmark studies (from hyperparameter optimization to evaluation) across an easily extensible set of tasks, deep learning models, datasets and evaluation metrics. LBT provides a configurable interface for controlling training and customizing evaluation, a standardized training framework for eliminating confounding variables, and support for multi-objective evaluation. We demonstrate how LBT can be used to create personalized benchmark studies with a large-scale comparative analysis for text classification across 7 models and 9 datasets. We explore the trade-offs between inference latency and performance, relationships between dataset attributes and performance, and the effects of pretraining on convergence and robustness, showing how LBT can be used to satisfy various benchmarking objectives.
Declarative Machine Learning Systems
Jul 16, 2021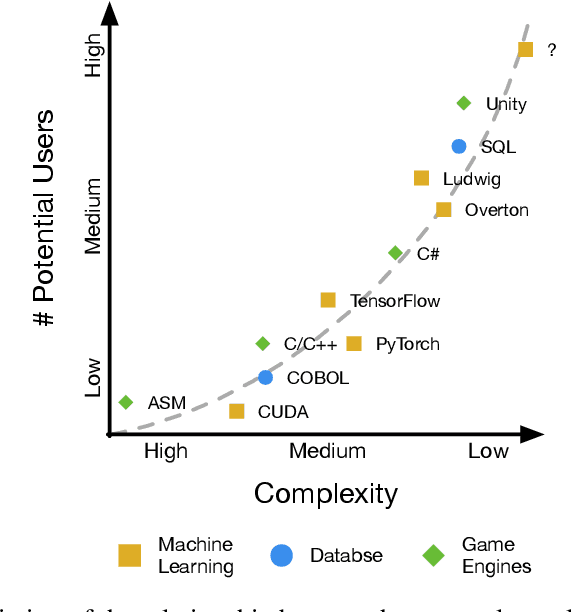
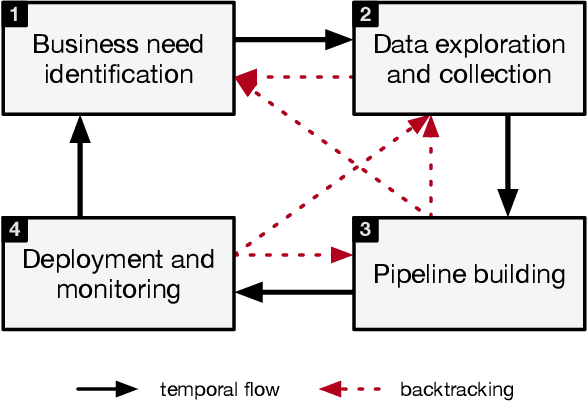


In the last years machine learning (ML) has moved from a academic endeavor to a pervasive technology adopted in almost every aspect of computing. ML-powered products are now embedded in our digital lives: from recommendations of what to watch, to divining our search intent, to powering virtual assistants in consumer and enterprise settings. Recent successes in applying ML in natural sciences revealed that ML can be used to tackle some of the hardest real-world problems humanity faces today. For these reasons ML has become central in the strategy of tech companies and has gathered even more attention from academia than ever before. Despite these successes, what we have witnessed so far is just the beginning. Right now the people training and using ML models are expert developers working within large organizations, but we believe the next wave of ML systems will allow a larger amount of people, potentially without coding skills, to perform the same tasks. These new ML systems will not require users to fully understand all the details of how models are trained and utilized for obtaining predictions. Declarative interfaces are well suited for this goal, by hiding complexity and favouring separation of interests, and can lead to increased productivity. We worked on such abstract interfaces by developing two declarative ML systems, Overton and Ludwig, that require users to declare only their data schema (names and types of inputs) and tasks rather then writing low level ML code. In this article we will describe how ML systems are currently structured, highlight important factors for their success and adoption, what are the issues current ML systems are facing and how the systems we developed addressed them. Finally we will talk about learnings from the development of ML systems throughout the years and how we believe the next generation of ML systems will look like.
Controllable Text Generation with Focused Variation
Sep 25, 2020
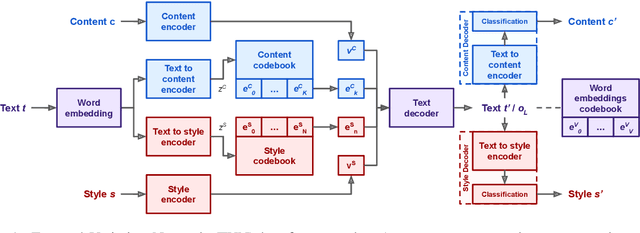
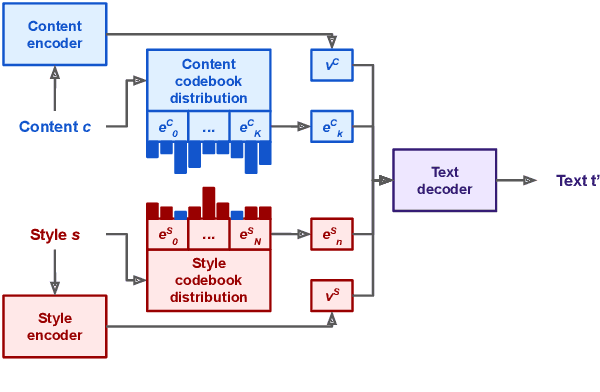
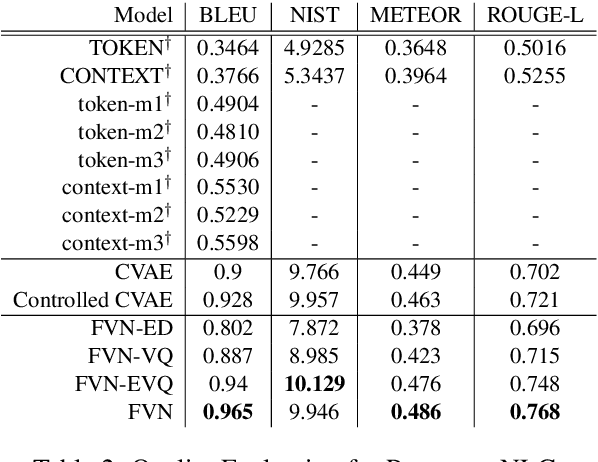
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
Joint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020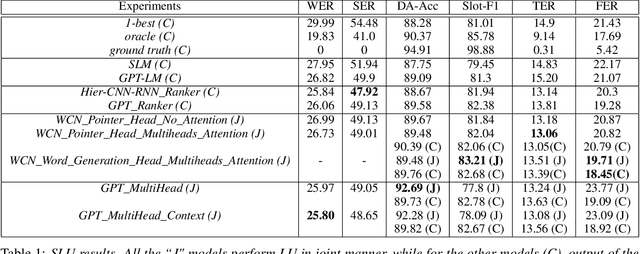
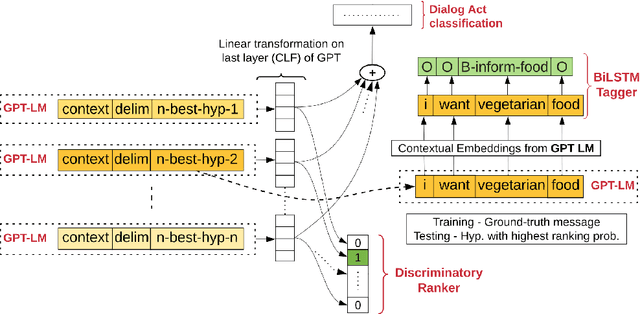
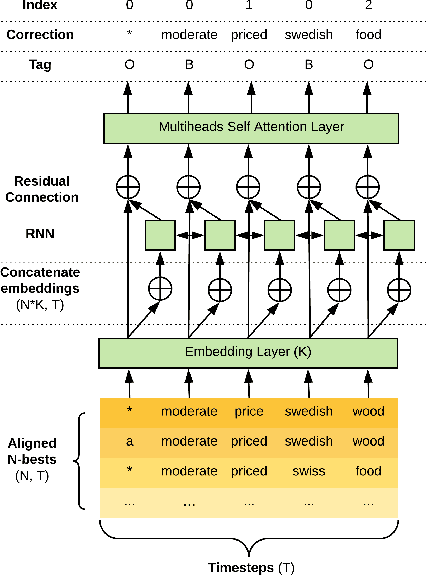
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

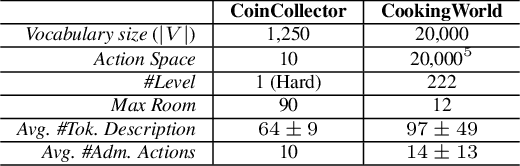
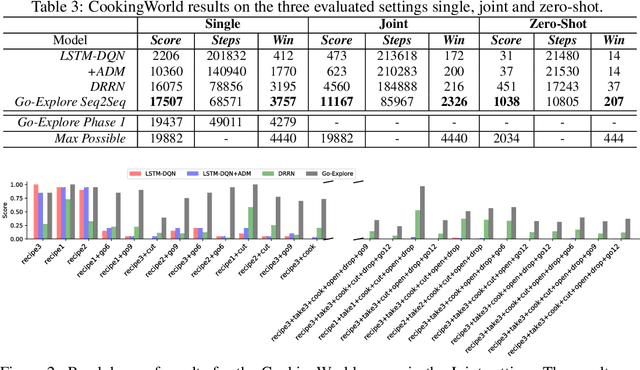
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Plato Dialogue System: A Flexible Conversational AI Research Platform
Jan 17, 2020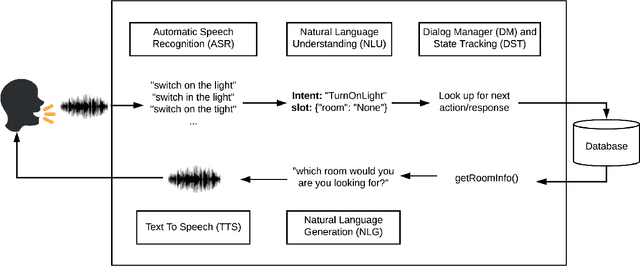

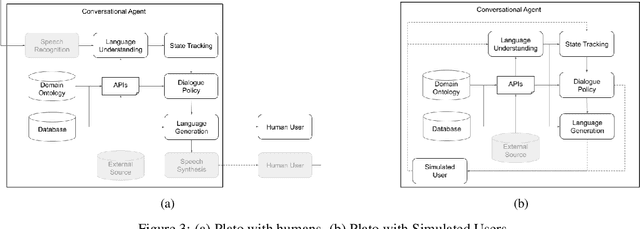
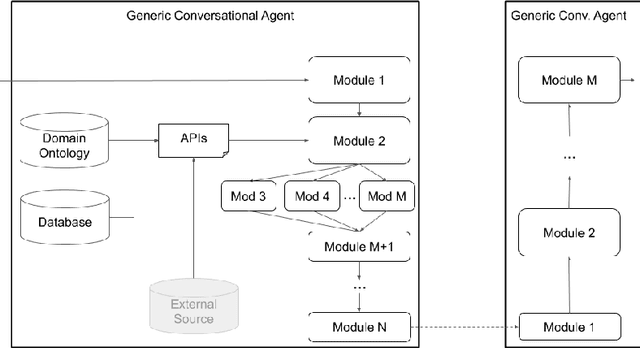
As the field of Spoken Dialogue Systems and Conversational AI grows, so does the need for tools and environments that abstract away implementation details in order to expedite the development process, lower the barrier of entry to the field, and offer a common test-bed for new ideas. In this paper, we present Plato, a flexible Conversational AI platform written in Python that supports any kind of conversational agent architecture, from standard architectures to architectures with jointly-trained components, single- or multi-party interactions, and offline or online training of any conversational agent component. Plato has been designed to be easy to understand and debug and is agnostic to the underlying learning frameworks that train each component.
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
Jan 08, 2020
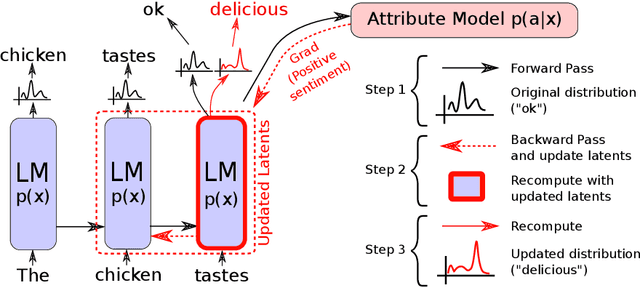
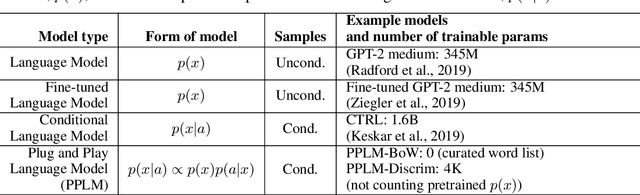
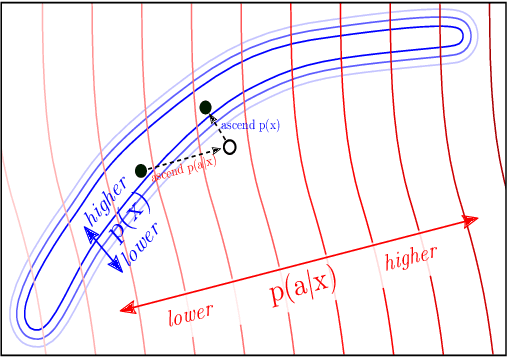
Large transformer-based language models (LMs) trained on huge text corpora have shown unparalleled generation capabilities. However, controlling attributes of the generated language (e.g. switching topic or sentiment) is difficult without modifying the model architecture or fine-tuning on attribute-specific data and entailing the significant cost of retraining. We propose a simple alternative: the Plug and Play Language Model (PPLM) for controllable language generation, which combines a pretrained LM with one or more simple attribute classifiers that guide text generation without any further training of the LM. In the canonical scenario we present, the attribute models are simple classifiers consisting of a user-specified bag of words or a single learned layer with 100,000 times fewer parameters than the LM. Sampling entails a forward and backward pass in which gradients from the attribute model push the LM's hidden activations and thus guide the generation. Model samples demonstrate control over a range of topics and sentiment styles, and extensive automated and human annotated evaluations show attribute alignment and fluency. PPLMs are flexible in that any combination of differentiable attribute models may be used to steer text generation, which will allow for diverse and creative applications beyond the examples given in this paper.
Meta-Graph: Few shot Link Prediction via Meta Learning
Dec 20, 2019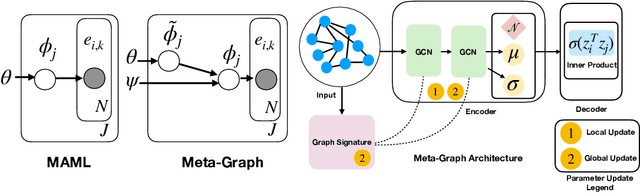
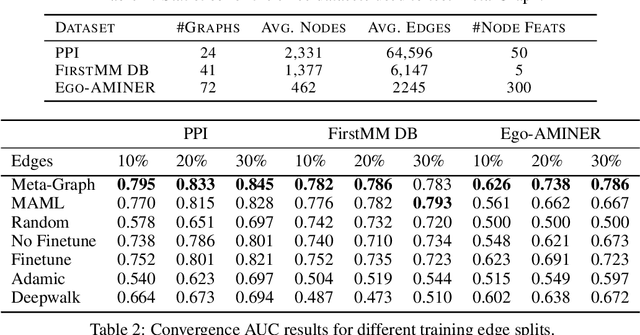
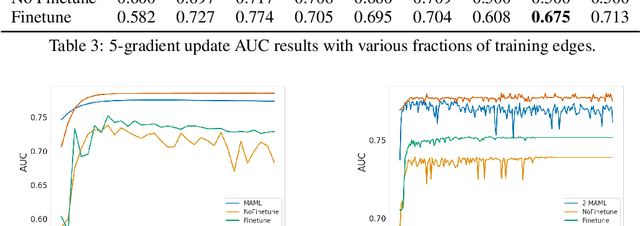
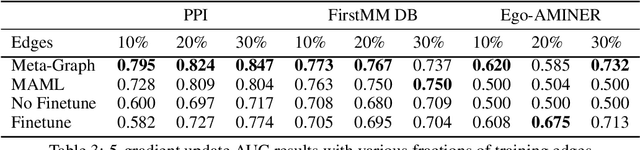
Fast adaptation to new data is one key facet of human intelligence and is an unexplored problem on graph-structured data. Few-Shot Link Prediction is a challenging task representative of real world data with evolving sub-graphs or entirely new graphs with shared structure. In this work, we present a meta-learning approach to Few Shot Link-Prediction. We further introduce Meta-Graph, a meta-learning algorithm which in addition to the global parameters learns a Graph Signature function that exploits structural information of a graph compared to other graphs from the same distribution for even faster adaptation and better convergence than vanilla Meta-Learning.